> ## Documentation Index
> Fetch the complete documentation index at: https://docs.portkey.ai/docs/llms.txt
> Use this file to discover all available pages before exploring further.
# Llama 3 on Portkey + Together AI
> Try out the new Llama 3 model directly using the OpenAI SDK
 ### You will need Portkey and Together AI API keys to get started
| Grab [Portkey API Key](https://app.portkey.ai/) | Grab [Together AI API Key](https://api.together.xyz/settings/api-keys) |
| ----------------------------------------------- | ---------------------------------------------------------------------- |
```bash theme={"system"}
pip install -qU portkey-ai openai
```
## With OpenAI Client
```python OpenAI Python icon="openai" theme={"system"}
from openai import OpenAI
from portkey_ai import PORTKEY_GATEWAY_URL, createHeaders
openai = OpenAI(
api_key='TOGETHER_API_KEY', # Grab from https://api.together.xyz/
base_url=PORTKEY_GATEWAY_URL,
default_headers=createHeaders(
provider="together-ai",
api_key='PORTKEY_API_KEY' # Grab from https://app.portkey.ai/
)
)
response = openai.chat.completions.create(
model="meta-llama/Llama-3-8b-chat-hf",
messages=[{"role": "user", "content": "What's a fractal?"}],
max_tokens=500
)
print(response.choices[0].message.content)
```
## With Portkey Client
Add your Together API key in [Model Catalog](https://app.portkey.ai/model-catalog) and access models using your provider slug
```python Python icon="python" theme={"system"}
from portkey_ai import Portkey
portkey = Portkey(api_key="PORTKEY_API_KEY")
response = portkey.chat.completions.create(
model="@together-prod/meta-llama/Llama-3-8b-chat-hf", # @provider-slug/model
messages=[{"role": "user", "content": "Who are you?"}],
max_tokens=500
)
print(response.choices[0].message.content)
```
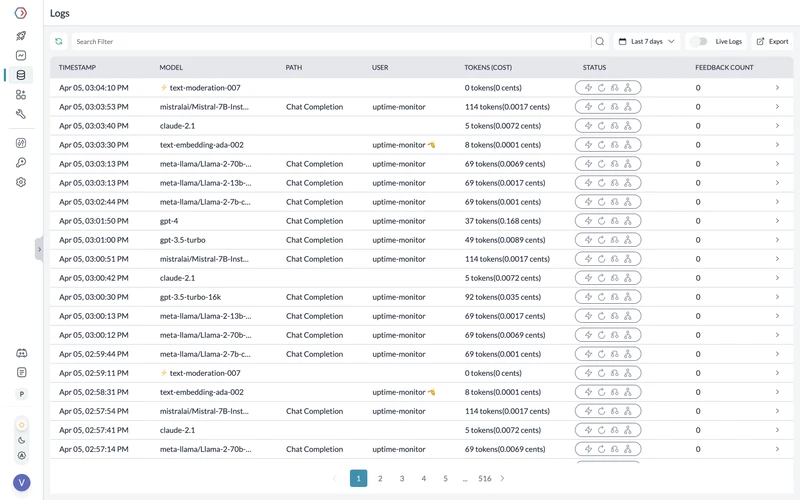
## Monitoring your Requests
Using Portkey you can monitor your Llama 3 requests and track tokens, cost, latency, and more.
### You will need Portkey and Together AI API keys to get started
| Grab [Portkey API Key](https://app.portkey.ai/) | Grab [Together AI API Key](https://api.together.xyz/settings/api-keys) |
| ----------------------------------------------- | ---------------------------------------------------------------------- |
```bash theme={"system"}
pip install -qU portkey-ai openai
```
## With OpenAI Client
```python OpenAI Python icon="openai" theme={"system"}
from openai import OpenAI
from portkey_ai import PORTKEY_GATEWAY_URL, createHeaders
openai = OpenAI(
api_key='TOGETHER_API_KEY', # Grab from https://api.together.xyz/
base_url=PORTKEY_GATEWAY_URL,
default_headers=createHeaders(
provider="together-ai",
api_key='PORTKEY_API_KEY' # Grab from https://app.portkey.ai/
)
)
response = openai.chat.completions.create(
model="meta-llama/Llama-3-8b-chat-hf",
messages=[{"role": "user", "content": "What's a fractal?"}],
max_tokens=500
)
print(response.choices[0].message.content)
```
## With Portkey Client
Add your Together API key in [Model Catalog](https://app.portkey.ai/model-catalog) and access models using your provider slug
```python Python icon="python" theme={"system"}
from portkey_ai import Portkey
portkey = Portkey(api_key="PORTKEY_API_KEY")
response = portkey.chat.completions.create(
model="@together-prod/meta-llama/Llama-3-8b-chat-hf", # @provider-slug/model
messages=[{"role": "user", "content": "Who are you?"}],
max_tokens=500
)
print(response.choices[0].message.content)
```
## Monitoring your Requests
Using Portkey you can monitor your Llama 3 requests and track tokens, cost, latency, and more.