> ## Documentation Index
> Fetch the complete documentation index at: https://docs.portkey.ai/docs/llms.txt
> Use this file to discover all available pages before exploring further.
# LlamaIndex (Python)
> Add Portkey's enterprise features to any LlamaIndex app—observability, reliability, caching, and cost control.
LlamaIndex provides a framework for building LLM applications with your data. Add Portkey to get production-grade features: full observability, automatic fallbacks, semantic caching, and cost controls—all without changing your LlamaIndex code.
## Quick Start
Add Portkey to any LlamaIndex app with 3 parameters:
```python theme={"system"}
from llama_index.llms.openai import OpenAI
llm = OpenAI(
model="@openai-prod/gpt-4o", # Provider slug from Model Catalog
api_base="https://api.portkey.ai/v1",
api_key="PORTKEY_API_KEY" # Your Portkey API key
)
response = llm.complete("Tell me a joke")
print(response.text)
```
 That's it! You now get:
* ✅ Full observability (costs, latency, logs)
* ✅ Dynamic model selection per request
* ✅ Automatic fallbacks and retries (via configs)
* ✅ Budget controls per team/project
## Why Add Portkey to LlamaIndex?
LlamaIndex handles data indexing and querying. Portkey adds production features:
Every request logged with costs, latency, tokens. Team-level analytics and debugging.
Switch models per request. Route simple queries to cheap models, complex to advanced—automatically tracked.
Automatic fallbacks, smart retries, load balancing—configured once, works everywhere.
Budget limits per team/project. Rate limiting. Centralized credential management.
## Setup
### 1. Install Packages
```bash theme={"system"}
pip install llama-index-llms-openai portkey-ai
```
### 2. Add Provider in Model Catalog
1. Go to [**Model Catalog → Add Provider**](https://app.portkey.ai/model-catalog/providers)
2. Select your provider (OpenAI, Anthropic, Google, etc.)
3. Choose existing credentials or create new by entering your API keys
4. Name your provider (e.g., `openai-prod`)
Your provider slug will be **`@openai-prod`** (or whatever you named it).
Set up budgets, rate limits, and manage credentials
### 3. Get Portkey API Key
Create your Portkey API key at [app.portkey.ai/api-keys](https://app.portkey.ai/api-keys)
### 4. Use in Your Code
Replace your existing LLM initialization:
```python theme={"system"}
# Before (direct to OpenAI)
from llama_index.llms.openai import OpenAI
llm = OpenAI(
model="gpt-4o",
api_key="OPENAI_API_KEY"
)
# After (via Portkey)
llm = OpenAI(
model="@openai-prod/gpt-4o",
api_base="https://api.portkey.ai/v1",
api_key="PORTKEY_API_KEY"
)
```
**That's the only change needed!** All your existing LlamaIndex code (indexes, query engines, agents) works exactly the same.
## Switching Between Providers
Just change the model string—everything else stays the same:
```python theme={"system"}
from llama_index.llms.openai import OpenAI
# OpenAI
llm = OpenAI(
model="@openai-prod/gpt-4o",
api_base="https://api.portkey.ai/v1",
api_key="PORTKEY_API_KEY"
)
# Anthropic
llm = OpenAI(
model="@anthropic-prod/claude-sonnet-4",
api_base="https://api.portkey.ai/v1",
api_key="PORTKEY_API_KEY"
)
# Google Gemini
llm = OpenAI(
model="@google-prod/gemini-2.0-flash",
api_base="https://api.portkey.ai/v1",
api_key="PORTKEY_API_KEY"
)
```
Portkey implements OpenAI-compatible APIs for all providers, so you always use `llama_index.llms.openai.OpenAI` regardless of which model you're calling.
## Using with LlamaIndex Chat
LlamaIndex's chat interface works seamlessly:
```python theme={"system"}
from llama_index.llms.openai import OpenAI
from llama_index.core.llms import ChatMessage
llm = OpenAI(
model="@openai-prod/gpt-4o",
api_base="https://api.portkey.ai/v1",
api_key="PORTKEY_API_KEY"
)
messages = [
ChatMessage(role="system", content="You are a helpful assistant"),
ChatMessage(role="user", content="What is the capital of France?")
]
response = llm.chat(messages)
print(response.message.content)
```
## Works With All LlamaIndex Features
✅ **Query Engines** - All query types supported\
✅ **Chat Engines** - Conversational interfaces\
✅ **Agents** - Full agent compatibility\
✅ **Streaming** - Token-by-token streaming\
✅ **RAG Pipelines** - Retrieval-augmented generation\
✅ **Workflows** - Complex LLM workflows
### Streaming
```python theme={"system"}
from llama_index.llms.openai import OpenAI
llm = OpenAI(
model="@openai-prod/gpt-4o",
api_base="https://api.portkey.ai/v1",
api_key="PORTKEY_API_KEY"
)
# Stream completions
for chunk in llm.stream_complete("Write a short story"):
print(chunk.delta, end="", flush=True)
# Stream chat
messages = [ChatMessage(role="user", content="Tell me a joke")]
for chunk in llm.stream_chat(messages):
print(chunk.delta, end="", flush=True)
```
### Async Support
```python theme={"system"}
import asyncio
from llama_index.llms.openai import OpenAI
async def main():
llm = OpenAI(
model="@openai-prod/gpt-4o",
api_base="https://api.portkey.ai/v1",
api_key="PORTKEY_API_KEY"
)
# Async completion
response = await llm.acomplete("What is 2+2?")
print(response.text)
# Async streaming
async for chunk in await llm.astream_complete("Write a haiku"):
print(chunk.delta, end="", flush=True)
asyncio.run(main())
```
### RAG with Query Engine
```python theme={"system"}
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
from llama_index.llms.openai import OpenAI
# Set up LLM with Portkey
llm = OpenAI(
model="@openai-prod/gpt-4o",
api_base="https://api.portkey.ai/v1",
api_key="PORTKEY_API_KEY"
)
# Load and index documents
documents = SimpleDirectoryReader("data").load_data()
index = VectorStoreIndex.from_documents(documents)
# Query with Portkey-enabled LLM
query_engine = index.as_query_engine(llm=llm)
response = query_engine.query("What is the main topic?")
print(response)
```
## Advanced Features via Configs
For production features like fallbacks, caching, and load balancing, use Portkey Configs:
```python theme={"system"}
from llama_index.llms.openai import OpenAI
from portkey_ai import PORTKEY_GATEWAY_URL, createHeaders
llm = OpenAI(
model="gpt-4o", # Default model
api_base=PORTKEY_GATEWAY_URL,
api_key="PORTKEY_API_KEY",
default_headers=createHeaders(
config="pc_your_config_id" # Created in Portkey dashboard
)
)
```
### Example: Fallbacks
```python theme={"system"}
from llama_index.llms.openai import OpenAI
from portkey_ai import PORTKEY_GATEWAY_URL, createHeaders
config = {
"strategy": {"mode": "fallback"},
"targets": [
{"override_params": {"model": "@openai-prod/gpt-4o"}},
{"override_params": {"model": "@anthropic-prod/claude-sonnet-4"}}
]
}
llm = OpenAI(
model="gpt-4o",
api_base=PORTKEY_GATEWAY_URL,
api_key="PORTKEY_API_KEY",
default_headers=createHeaders(config=config)
)
# Automatically falls back to Anthropic if OpenAI fails
response = llm.complete("Hello!")
```
### Example: Load Balancing
```python theme={"system"}
config = {
"strategy": {"mode": "loadbalance"},
"targets": [
{"override_params": {"model": "@openai-prod/gpt-4o"}, "weight": 0.5},
{"override_params": {"model": "@anthropic-prod/claude-sonnet-4"}, "weight": 0.5}
]
}
llm = OpenAI(
model="gpt-4o",
api_base=PORTKEY_GATEWAY_URL,
api_key="PORTKEY_API_KEY",
default_headers=createHeaders(config=config)
)
# Requests distributed 50/50 between OpenAI and Anthropic
response = llm.complete("Hello!")
```
### Example: Caching
```python theme={"system"}
config = {
"cache": {
"mode": "semantic", # or "simple" for exact matches
"max_age": 3600 # Cache for 1 hour
},
"override_params": {"model": "@openai-prod/gpt-4o"}
}
llm = OpenAI(
model="gpt-4o",
api_base=PORTKEY_GATEWAY_URL,
api_key="PORTKEY_API_KEY",
default_headers=createHeaders(config=config)
)
# Responses cached for similar queries
response = llm.complete("What is machine learning?")
```
Set up fallbacks, retries, caching, load balancing, and more
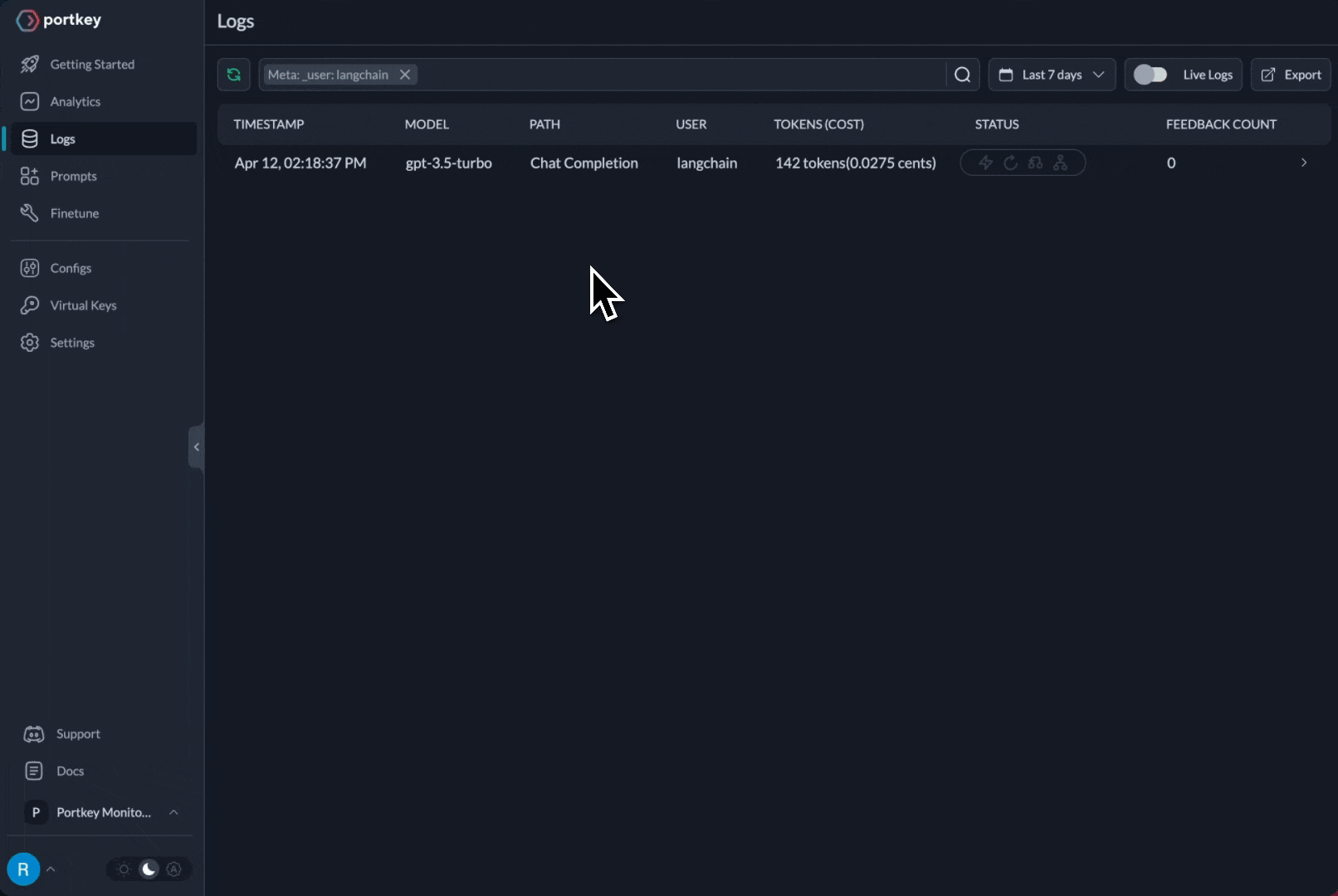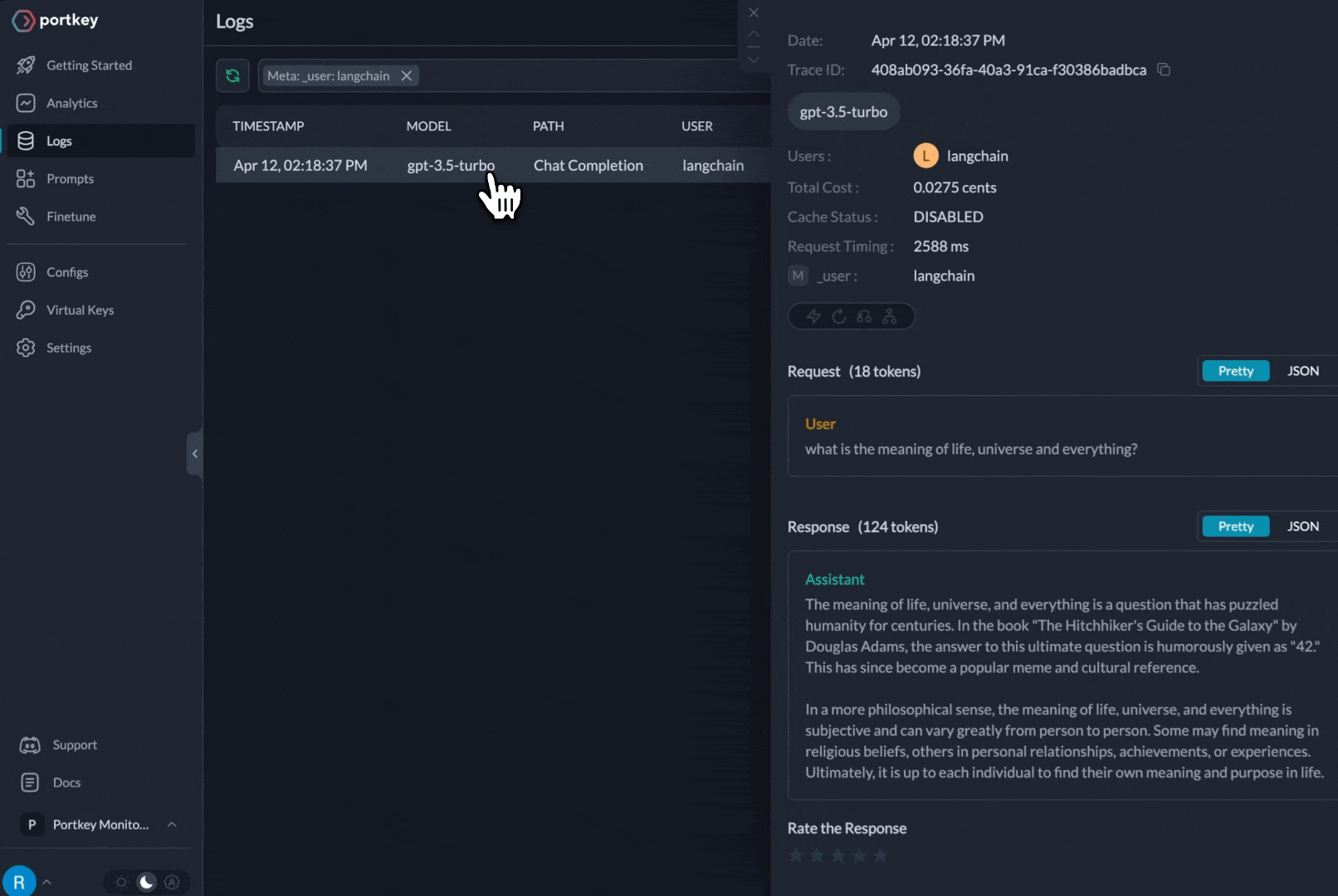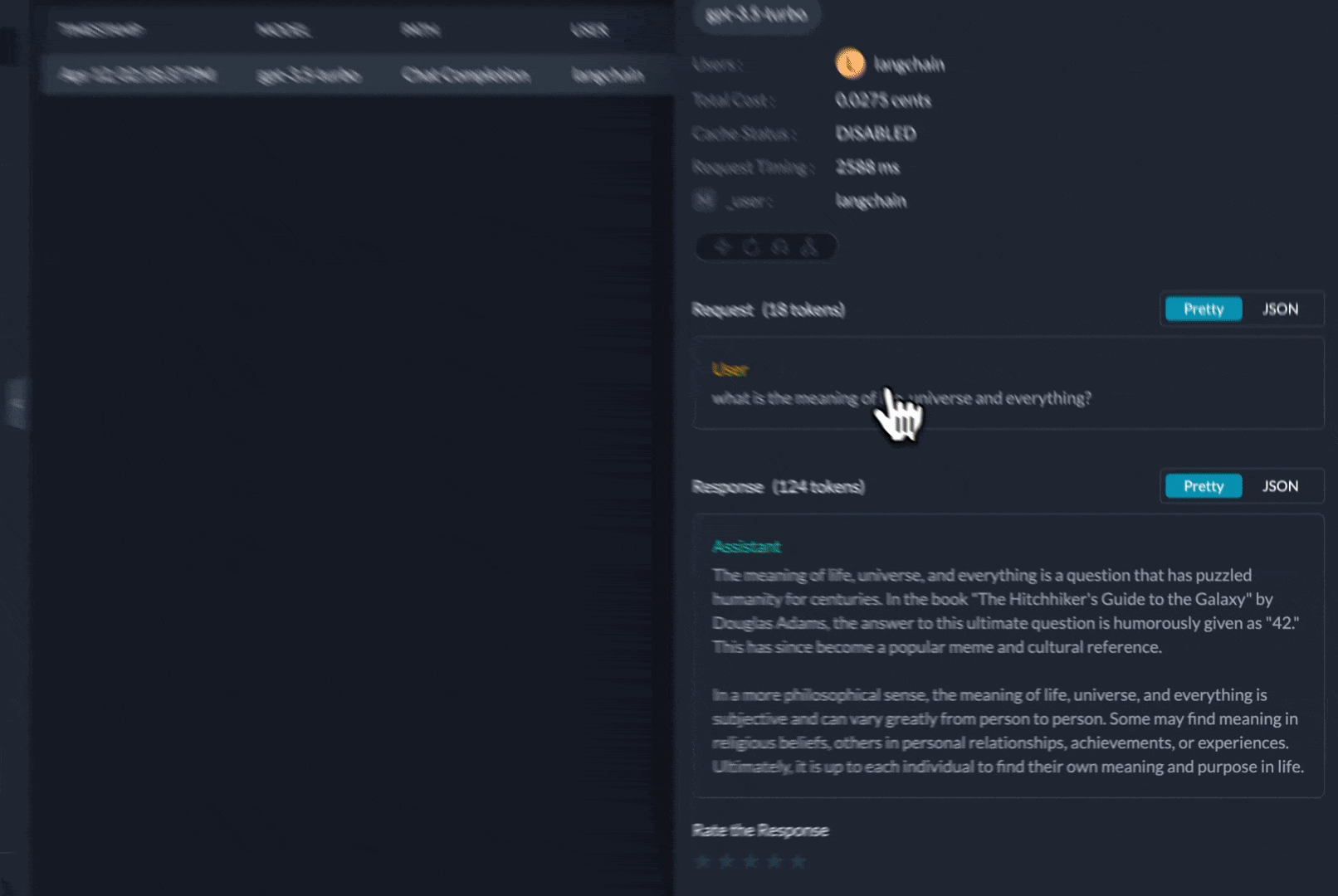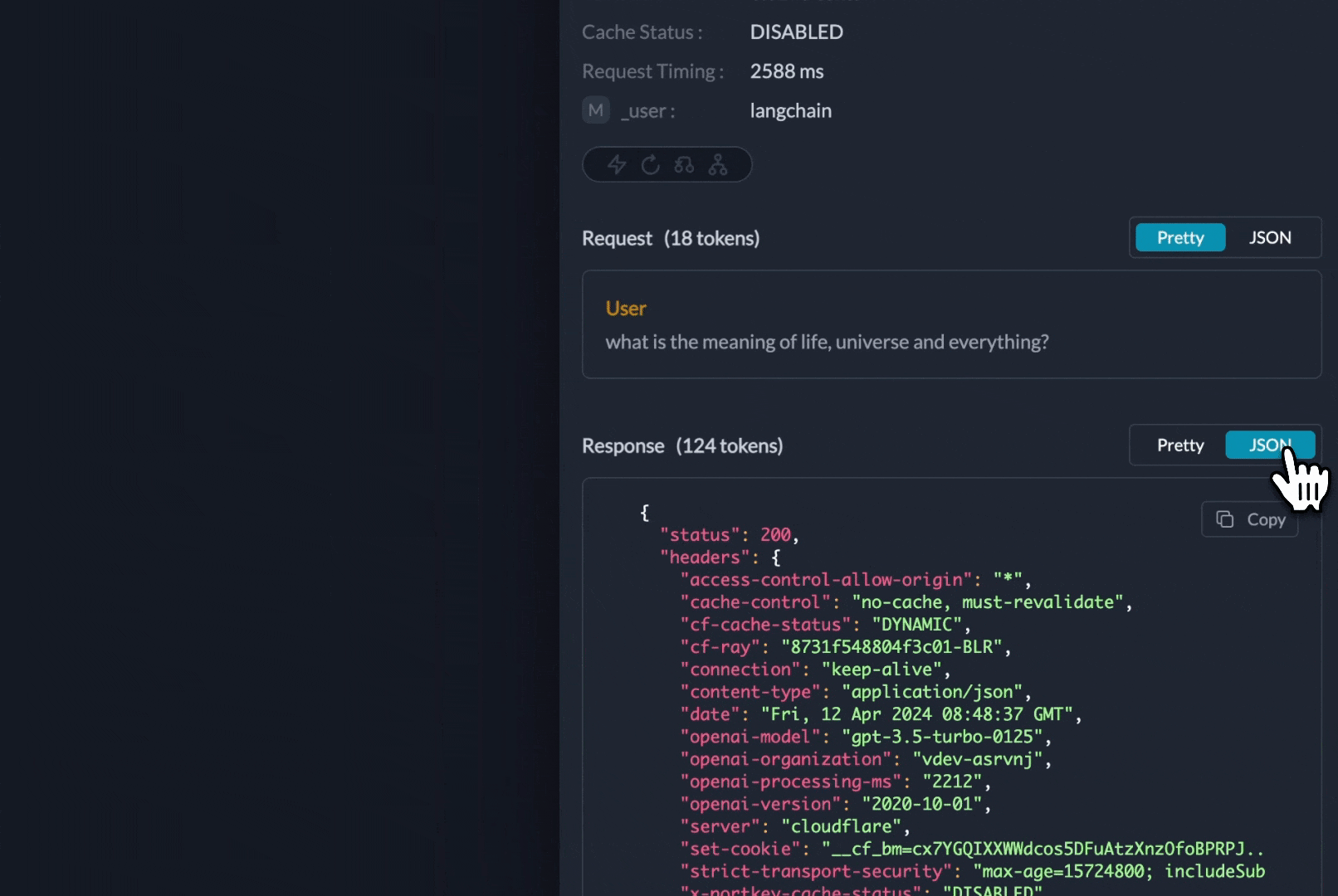
## Observability
Portkey automatically logs all requests. Add custom metadata for better analytics:
```python theme={"system"}
from llama_index.llms.openai import OpenAI
from portkey_ai import PORTKEY_GATEWAY_URL, createHeaders
llm = OpenAI(
model="@openai-prod/gpt-4o",
api_base=PORTKEY_GATEWAY_URL,
api_key="PORTKEY_API_KEY",
default_headers=createHeaders(
metadata={
"_user": "user_123",
"environment": "production",
"feature": "rag_query"
},
trace_id="unique_trace_id"
)
)
```
Filter and analyze logs by metadata in the Portkey dashboard.
Track costs, performance, and debug issues
## Prompt Management
Use prompts from Portkey's Prompt Library:
```python theme={"system"}
from llama_index.llms.openai import OpenAI
from llama_index.core.llms import ChatMessage
from portkey_ai import PORTKEY_GATEWAY_URL, createHeaders, Portkey
# Render prompt from Portkey
client = Portkey(api_key="PORTKEY_API_KEY")
prompt_template = client.prompts.render(
prompt_id="pp-your-prompt-id",
variables={"topic": "AI"}
).data.dict()
# Use with LlamaIndex
llm = OpenAI(
model="@openai-prod/gpt-4o",
api_base=PORTKEY_GATEWAY_URL,
api_key="PORTKEY_API_KEY"
)
messages = [
ChatMessage(content=msg["content"], role=msg["role"])
for msg in prompt_template["messages"]
]
response = llm.chat(messages)
print(response.message.content)
```
Manage, version, and test prompts in Portkey
## Migration from Direct OpenAI
Already using LlamaIndex with OpenAI? Just update 3 parameters:
```python theme={"system"}
# Before
from llama_index.llms.openai import OpenAI
import os
llm = OpenAI(
model="gpt-4o",
api_key=os.getenv("OPENAI_API_KEY"),
temperature=0.7
)
# After (add 2 parameters, change 1)
llm = OpenAI(
model="@openai-prod/gpt-4o", # Add provider slug
api_base="https://api.portkey.ai/v1", # Add this
api_key="PORTKEY_API_KEY", # Change to Portkey key
temperature=0.7 # Keep existing params
)
```
**Benefits:**
* Zero code changes to your existing LlamaIndex logic
* Instant observability for all requests
* Production-grade reliability features
* Cost controls and budgets
## Next Steps
Set up providers, budgets, and access control
Configure fallbacks, caching, and routing
Track costs, performance, and usage
Add PII detection and content filtering
For complete SDK documentation:
Complete Portkey SDK documentation
That's it! You now get:
* ✅ Full observability (costs, latency, logs)
* ✅ Dynamic model selection per request
* ✅ Automatic fallbacks and retries (via configs)
* ✅ Budget controls per team/project
## Why Add Portkey to LlamaIndex?
LlamaIndex handles data indexing and querying. Portkey adds production features:
Every request logged with costs, latency, tokens. Team-level analytics and debugging.
Switch models per request. Route simple queries to cheap models, complex to advanced—automatically tracked.
Automatic fallbacks, smart retries, load balancing—configured once, works everywhere.
Budget limits per team/project. Rate limiting. Centralized credential management.
## Setup
### 1. Install Packages
```bash theme={"system"}
pip install llama-index-llms-openai portkey-ai
```
### 2. Add Provider in Model Catalog
1. Go to [**Model Catalog → Add Provider**](https://app.portkey.ai/model-catalog/providers)
2. Select your provider (OpenAI, Anthropic, Google, etc.)
3. Choose existing credentials or create new by entering your API keys
4. Name your provider (e.g., `openai-prod`)
Your provider slug will be **`@openai-prod`** (or whatever you named it).
Set up budgets, rate limits, and manage credentials
### 3. Get Portkey API Key
Create your Portkey API key at [app.portkey.ai/api-keys](https://app.portkey.ai/api-keys)
### 4. Use in Your Code
Replace your existing LLM initialization:
```python theme={"system"}
# Before (direct to OpenAI)
from llama_index.llms.openai import OpenAI
llm = OpenAI(
model="gpt-4o",
api_key="OPENAI_API_KEY"
)
# After (via Portkey)
llm = OpenAI(
model="@openai-prod/gpt-4o",
api_base="https://api.portkey.ai/v1",
api_key="PORTKEY_API_KEY"
)
```
**That's the only change needed!** All your existing LlamaIndex code (indexes, query engines, agents) works exactly the same.
## Switching Between Providers
Just change the model string—everything else stays the same:
```python theme={"system"}
from llama_index.llms.openai import OpenAI
# OpenAI
llm = OpenAI(
model="@openai-prod/gpt-4o",
api_base="https://api.portkey.ai/v1",
api_key="PORTKEY_API_KEY"
)
# Anthropic
llm = OpenAI(
model="@anthropic-prod/claude-sonnet-4",
api_base="https://api.portkey.ai/v1",
api_key="PORTKEY_API_KEY"
)
# Google Gemini
llm = OpenAI(
model="@google-prod/gemini-2.0-flash",
api_base="https://api.portkey.ai/v1",
api_key="PORTKEY_API_KEY"
)
```
Portkey implements OpenAI-compatible APIs for all providers, so you always use `llama_index.llms.openai.OpenAI` regardless of which model you're calling.
## Using with LlamaIndex Chat
LlamaIndex's chat interface works seamlessly:
```python theme={"system"}
from llama_index.llms.openai import OpenAI
from llama_index.core.llms import ChatMessage
llm = OpenAI(
model="@openai-prod/gpt-4o",
api_base="https://api.portkey.ai/v1",
api_key="PORTKEY_API_KEY"
)
messages = [
ChatMessage(role="system", content="You are a helpful assistant"),
ChatMessage(role="user", content="What is the capital of France?")
]
response = llm.chat(messages)
print(response.message.content)
```
## Works With All LlamaIndex Features
✅ **Query Engines** - All query types supported\
✅ **Chat Engines** - Conversational interfaces\
✅ **Agents** - Full agent compatibility\
✅ **Streaming** - Token-by-token streaming\
✅ **RAG Pipelines** - Retrieval-augmented generation\
✅ **Workflows** - Complex LLM workflows
### Streaming
```python theme={"system"}
from llama_index.llms.openai import OpenAI
llm = OpenAI(
model="@openai-prod/gpt-4o",
api_base="https://api.portkey.ai/v1",
api_key="PORTKEY_API_KEY"
)
# Stream completions
for chunk in llm.stream_complete("Write a short story"):
print(chunk.delta, end="", flush=True)
# Stream chat
messages = [ChatMessage(role="user", content="Tell me a joke")]
for chunk in llm.stream_chat(messages):
print(chunk.delta, end="", flush=True)
```
### Async Support
```python theme={"system"}
import asyncio
from llama_index.llms.openai import OpenAI
async def main():
llm = OpenAI(
model="@openai-prod/gpt-4o",
api_base="https://api.portkey.ai/v1",
api_key="PORTKEY_API_KEY"
)
# Async completion
response = await llm.acomplete("What is 2+2?")
print(response.text)
# Async streaming
async for chunk in await llm.astream_complete("Write a haiku"):
print(chunk.delta, end="", flush=True)
asyncio.run(main())
```
### RAG with Query Engine
```python theme={"system"}
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
from llama_index.llms.openai import OpenAI
# Set up LLM with Portkey
llm = OpenAI(
model="@openai-prod/gpt-4o",
api_base="https://api.portkey.ai/v1",
api_key="PORTKEY_API_KEY"
)
# Load and index documents
documents = SimpleDirectoryReader("data").load_data()
index = VectorStoreIndex.from_documents(documents)
# Query with Portkey-enabled LLM
query_engine = index.as_query_engine(llm=llm)
response = query_engine.query("What is the main topic?")
print(response)
```
## Advanced Features via Configs
For production features like fallbacks, caching, and load balancing, use Portkey Configs:
```python theme={"system"}
from llama_index.llms.openai import OpenAI
from portkey_ai import PORTKEY_GATEWAY_URL, createHeaders
llm = OpenAI(
model="gpt-4o", # Default model
api_base=PORTKEY_GATEWAY_URL,
api_key="PORTKEY_API_KEY",
default_headers=createHeaders(
config="pc_your_config_id" # Created in Portkey dashboard
)
)
```
### Example: Fallbacks
```python theme={"system"}
from llama_index.llms.openai import OpenAI
from portkey_ai import PORTKEY_GATEWAY_URL, createHeaders
config = {
"strategy": {"mode": "fallback"},
"targets": [
{"override_params": {"model": "@openai-prod/gpt-4o"}},
{"override_params": {"model": "@anthropic-prod/claude-sonnet-4"}}
]
}
llm = OpenAI(
model="gpt-4o",
api_base=PORTKEY_GATEWAY_URL,
api_key="PORTKEY_API_KEY",
default_headers=createHeaders(config=config)
)
# Automatically falls back to Anthropic if OpenAI fails
response = llm.complete("Hello!")
```
### Example: Load Balancing
```python theme={"system"}
config = {
"strategy": {"mode": "loadbalance"},
"targets": [
{"override_params": {"model": "@openai-prod/gpt-4o"}, "weight": 0.5},
{"override_params": {"model": "@anthropic-prod/claude-sonnet-4"}, "weight": 0.5}
]
}
llm = OpenAI(
model="gpt-4o",
api_base=PORTKEY_GATEWAY_URL,
api_key="PORTKEY_API_KEY",
default_headers=createHeaders(config=config)
)
# Requests distributed 50/50 between OpenAI and Anthropic
response = llm.complete("Hello!")
```
### Example: Caching
```python theme={"system"}
config = {
"cache": {
"mode": "semantic", # or "simple" for exact matches
"max_age": 3600 # Cache for 1 hour
},
"override_params": {"model": "@openai-prod/gpt-4o"}
}
llm = OpenAI(
model="gpt-4o",
api_base=PORTKEY_GATEWAY_URL,
api_key="PORTKEY_API_KEY",
default_headers=createHeaders(config=config)
)
# Responses cached for similar queries
response = llm.complete("What is machine learning?")
```
Set up fallbacks, retries, caching, load balancing, and more
## Observability
Portkey automatically logs all requests. Add custom metadata for better analytics:
```python theme={"system"}
from llama_index.llms.openai import OpenAI
from portkey_ai import PORTKEY_GATEWAY_URL, createHeaders
llm = OpenAI(
model="@openai-prod/gpt-4o",
api_base=PORTKEY_GATEWAY_URL,
api_key="PORTKEY_API_KEY",
default_headers=createHeaders(
metadata={
"_user": "user_123",
"environment": "production",
"feature": "rag_query"
},
trace_id="unique_trace_id"
)
)
```
Filter and analyze logs by metadata in the Portkey dashboard.
Track costs, performance, and debug issues
## Prompt Management
Use prompts from Portkey's Prompt Library:
```python theme={"system"}
from llama_index.llms.openai import OpenAI
from llama_index.core.llms import ChatMessage
from portkey_ai import PORTKEY_GATEWAY_URL, createHeaders, Portkey
# Render prompt from Portkey
client = Portkey(api_key="PORTKEY_API_KEY")
prompt_template = client.prompts.render(
prompt_id="pp-your-prompt-id",
variables={"topic": "AI"}
).data.dict()
# Use with LlamaIndex
llm = OpenAI(
model="@openai-prod/gpt-4o",
api_base=PORTKEY_GATEWAY_URL,
api_key="PORTKEY_API_KEY"
)
messages = [
ChatMessage(content=msg["content"], role=msg["role"])
for msg in prompt_template["messages"]
]
response = llm.chat(messages)
print(response.message.content)
```
Manage, version, and test prompts in Portkey
## Migration from Direct OpenAI
Already using LlamaIndex with OpenAI? Just update 3 parameters:
```python theme={"system"}
# Before
from llama_index.llms.openai import OpenAI
import os
llm = OpenAI(
model="gpt-4o",
api_key=os.getenv("OPENAI_API_KEY"),
temperature=0.7
)
# After (add 2 parameters, change 1)
llm = OpenAI(
model="@openai-prod/gpt-4o", # Add provider slug
api_base="https://api.portkey.ai/v1", # Add this
api_key="PORTKEY_API_KEY", # Change to Portkey key
temperature=0.7 # Keep existing params
)
```
**Benefits:**
* Zero code changes to your existing LlamaIndex logic
* Instant observability for all requests
* Production-grade reliability features
* Cost controls and budgets
## Next Steps
Set up providers, budgets, and access control
Configure fallbacks, caching, and routing
Track costs, performance, and usage
Add PII detection and content filtering
For complete SDK documentation:
Complete Portkey SDK documentation