> ## Documentation Index
> Fetch the complete documentation index at: https://docs.portkey.ai/docs/llms.txt
> Use this file to discover all available pages before exploring further.
# Prompt Caching
OpenAI now offers prompt caching, a feature that can significantly reduce both latency and costs for your API requests. This feature is particularly beneficial for prompts exceeding 1024 tokens, offering up to an 80% reduction in latency for longer prompts over 10,000 tokens.
**Prompt Caching is enabled for following models**
* `gpt-4o (excludes gpt-4o-2024-05-13)`
* `gpt-4o-mini`
* `o1-preview`
* `o1-mini`
Portkey supports OpenAI's prompt caching feature out of the box. Here is an examples on of how to use it:
```python theme={"system"}
from portkey_ai import Portkey
portkey = Portkey(
api_key="PORTKEY_API_KEY",
provider="@OPENAI_PROVIDER",
)
# Define tools (for function calling example)
tools = [
{
"type": "function",
"function": {
"name": "get_weather",
"description": "Get the current weather in a given location",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city and state, e.g. San Francisco, CA",
},
"unit": {"type": "string", "enum": ["celsius", "fahrenheit"]},
},
"required": ["location"],
},
}
}
]
# Example: Function calling with caching
response = portkey.chat.completions.create(
model="gpt-4",
messages=[
{"role": "system", "content": "You are a helpful assistant that can check the weather."},
{"role": "user", "content": "What's the weather like in San Francisco?"}
],
tools=tools,
tool_choice="auto"
)
print(json.dumps(response.model_dump(), indent=2))
```
```javascript theme={"system"}
import Portkey from 'portkey-ai'
const portkey = new Portkey({
apiKey: "PORTKEY_API_KEY", // defaults to process.env["PORTKEY_API_KEY"]
provider:"@PROVIDER" // Your OpenAI Provider Slug
})
// Define tools (for function calling example)
const tools = [
{
"type": "function",
"function": {
"name": "get_weather",
"description": "Get the current weather in a given location",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city and state, e.g. San Francisco, CA",
},
"unit": {"type": "string", "enum": ["celsius", "fahrenheit"]},
},
"required": ["location"],
},
}
}
];
async function Examples() {
// Example : Function calling with caching
completion = await openai.chat.completions.create({
messages: [
{"role": "system", "content": "You are a helpful assistant that can check the weather."},
{"role": "user", "content": "What's the weather like in San Francisco?"}
],
model: "gpt-4",
tools: tools,
tool_choice: "auto"
});
console.log(JSON.stringify(completion, null, 2));
}
Examples();
```
```python theme={"system"}
from openai import OpenAI
from portkey_ai import PORTKEY_GATEWAY_URL, createHeaders
import os
import json
client = OpenAI(
api_key=os.environ.get("OPENAI_API_KEY"),
base_url=PORTKEY_GATEWAY_URL,
default_headers=createHeaders(
provider="openai",
api_key=os.environ.get("PORTKEY_API_KEY")
)
)
# Define tools (for function calling example)
tools = [
{
"type": "function",
"function": {
"name": "get_weather",
"description": "Get the current weather in a given location",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city and state, e.g. San Francisco, CA",
},
"unit": {"type": "string", "enum": ["celsius", "fahrenheit"]},
},
"required": ["location"],
},
}
}
]
# Example: Function calling with caching
response = client.chat.completions.create(
model="gpt-4",
messages=[
{"role": "system", "content": "You are a helpful assistant that can check the weather."},
{"role": "user", "content": "What's the weather like in San Francisco?"}
],
tools=tools,
tool_choice="auto"
)
print(json.dumps(response.model_dump(), indent=2))
```
```javascript theme={"system"}
import OpenAI from 'openai';
import { PORTKEY_GATEWAY_URL, createHeaders } from 'portkey-ai'
const openai = new OpenAI({
apiKey: "OPENAI_API_KEY",
baseURL: PORTKEY_GATEWAY_URL,
defaultHeaders: createHeaders({
provider: "openai",
apiKey: "PORTKEY_API_KEY"
})
});
// Define tools (for function calling example)
const tools = [
{
"type": "function",
"function": {
"name": "get_weather",
"description": "Get the current weather in a given location",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city and state, e.g. San Francisco, CA",
},
"unit": {"type": "string", "enum": ["celsius", "fahrenheit"]},
},
"required": ["location"],
},
}
}
];
async function Examples() {
// Example : Function calling with caching
completion = await openai.chat.completions.create({
messages: [
{"role": "system", "content": "You are a helpful assistant that can check the weather."},
{"role": "user", "content": "What's the weather like in San Francisco?"}
],
model: "gpt-4",
tools: tools,
tool_choice: "auto"
});
console.log(JSON.stringify(completion, null, 2));
}
Examples();
```
### What can be cached
* **Messages:** The complete messages array, encompassing system, user, and assistant interactions.
* **Images:** Images included in user messages, either as links or as base64-encoded data, as well as multiple images can be sent. Ensure the detail parameter is set identically, as it impacts image tokenization.
* **Tool use:** Both the messages array and the list of available `tools` can be cached, contributing to the minimum 1024 token requirement.
* **Structured outputs:** The structured output schema serves as a prefix to the system message and can be cached.
### What's Not Supported
* Completions API (only Chat Completions API is supported)
* Streaming responses (caching works, but streaming itself is not affected)
### Monitoring Cache Performance
Prompt caching requests & responses based on OpenAI's calculations here:
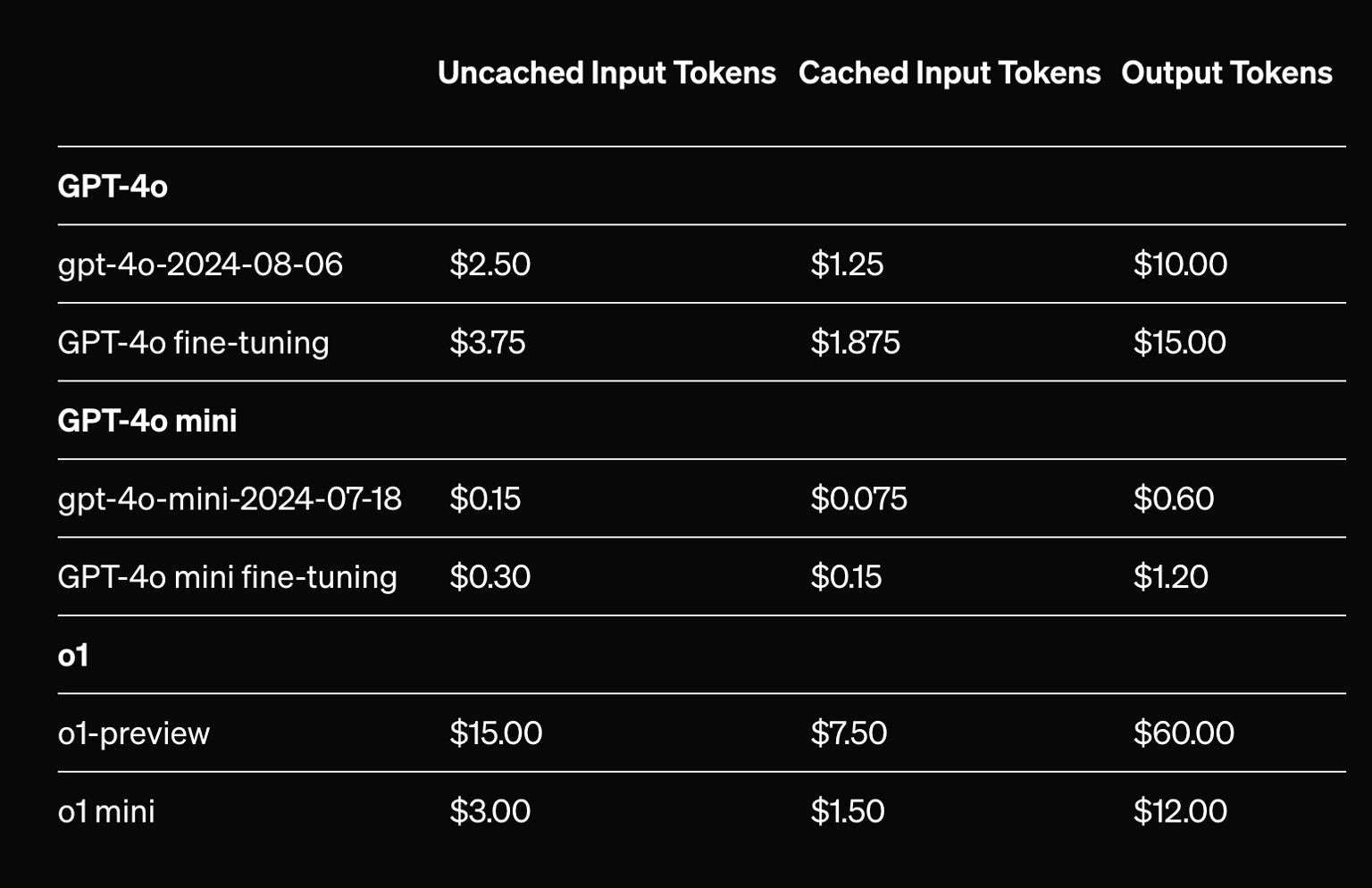 All requests, including those with fewer than 1024 tokens, will display a `cached_tokens` field of the `usage.prompt_tokens_details` [chat completions object](https://platform.openai.com/docs/api-reference/chat/object) indicating how many of the prompt tokens were a cache hit.
For requests under 1024 tokens, `cached_tokens` will be zero.
All requests, including those with fewer than 1024 tokens, will display a `cached_tokens` field of the `usage.prompt_tokens_details` [chat completions object](https://platform.openai.com/docs/api-reference/chat/object) indicating how many of the prompt tokens were a cache hit.
For requests under 1024 tokens, `cached_tokens` will be zero.
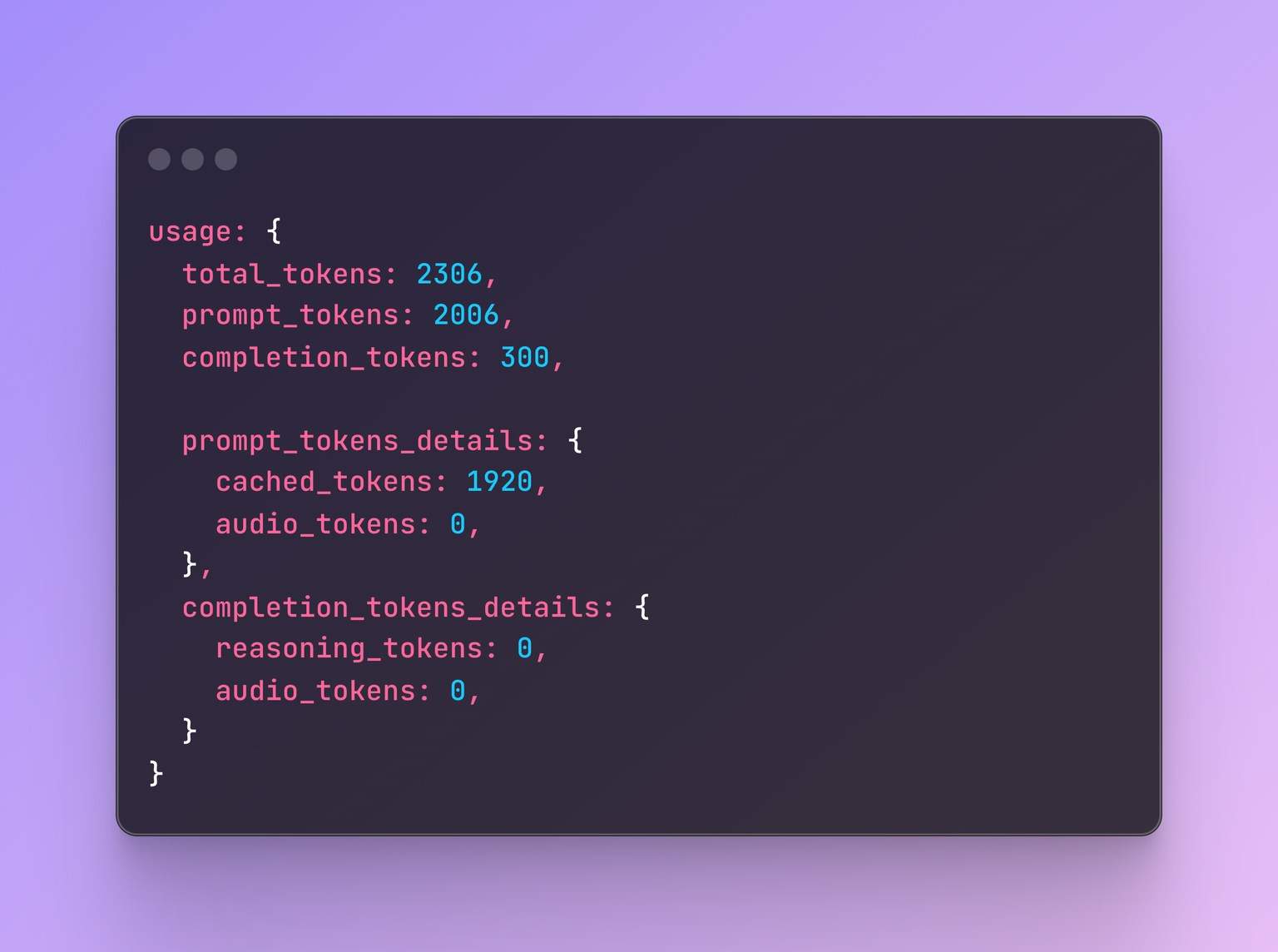
cached\_tokens field of the usage.prompt\_tokens\_details
**Key Features:**
* Reduced Latency: Especially significant for longer prompts.
* Lower Costs: Cached portions of prompts are billed at a discounted rate.
* Improved Efficiency: Allows for more context in prompts without increasing costs proportionally.
* Zero Data Retention: No data is stored during the caching process, making it eligible for zero data retention policies.