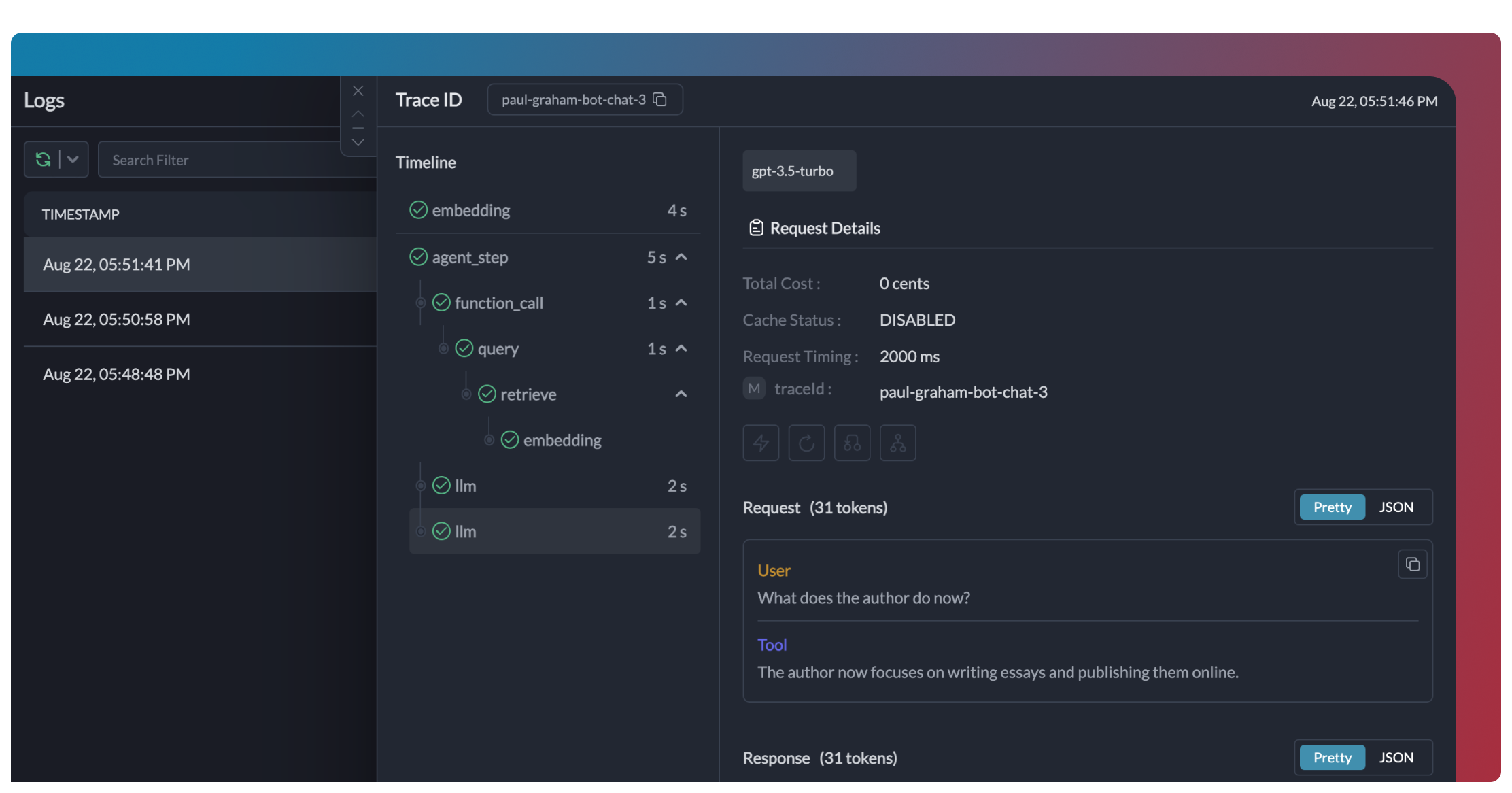
 Traces provide a hierarchical view of your agent's execution, showing the sequence of LLM calls, tool invocations, and state transitions.
```python theme={"system"}
# Add trace_id to enable hierarchical tracing in Portkey
portkey_client = AsyncPortkey(
api_key="YOUR_PORTKEY_API_KEY",
virtual_key="YOUR_LLM_PROVIDER_VIRTUAL_KEY",
trace_id="unique-session-id", # Add unique trace ID
metadata={"request_type": "user_query"}
)
```
Traces provide a hierarchical view of your agent's execution, showing the sequence of LLM calls, tool invocations, and state transitions.
```python theme={"system"}
# Add trace_id to enable hierarchical tracing in Portkey
portkey_client = AsyncPortkey(
api_key="YOUR_PORTKEY_API_KEY",
virtual_key="YOUR_LLM_PROVIDER_VIRTUAL_KEY",
trace_id="unique-session-id", # Add unique trace ID
metadata={"request_type": "user_query"}
)
```
 Portkey logs every interaction with LLMs, including:
* Complete request and response payloads
* Latency and token usage metrics
* Cost calculations
* Tool calls and function executions
All logs can be filtered by metadata, trace IDs, models, and more, making it easy to debug specific agent runs.
Portkey logs every interaction with LLMs, including:
* Complete request and response payloads
* Latency and token usage metrics
* Cost calculations
* Tool calls and function executions
All logs can be filtered by metadata, trace IDs, models, and more, making it easy to debug specific agent runs.
 Portkey provides built-in dashboards that help you:
* Track cost and token usage across all agent runs
* Analyze performance metrics like latency and success rates
* Identify bottlenecks in your agent workflows
* Compare different agent configurations and LLMs
You can filter and segment all metrics by custom metadata to analyze specific agent types, user groups, or use cases.
Portkey provides built-in dashboards that help you:
* Track cost and token usage across all agent runs
* Analyze performance metrics like latency and success rates
* Identify bottlenecks in your agent workflows
* Compare different agent configurations and LLMs
You can filter and segment all metrics by custom metadata to analyze specific agent types, user groups, or use cases.
 Add custom metadata to your PydanticAI agent calls to enable powerful filtering and segmentation:
```python theme={"system"}
portkey_client = AsyncPortkey(
api_key="YOUR_PORTKEY_API_KEY",
virtual_key="YOUR_LLM_PROVIDER_VIRTUAL_KEY",
metadata={
"agent_type": "weather_agent",
"environment": "production",
"_user": "user_123", # Special _user field for user analytics
"request_source": "mobile_app"
}
)
```
This metadata can be used to filter logs, traces, and metrics on the Portkey dashboard, allowing you to analyze specific agent runs, users, or environments.
Add custom metadata to your PydanticAI agent calls to enable powerful filtering and segmentation:
```python theme={"system"}
portkey_client = AsyncPortkey(
api_key="YOUR_PORTKEY_API_KEY",
virtual_key="YOUR_LLM_PROVIDER_VIRTUAL_KEY",
metadata={
"agent_type": "weather_agent",
"environment": "production",
"_user": "user_123", # Special _user field for user analytics
"request_source": "mobile_app"
}
)
```
This metadata can be used to filter logs, traces, and metrics on the Portkey dashboard, allowing you to analyze specific agent runs, users, or environments.
 This enables:
* Per-user cost tracking and budgeting
* Personalized user analytics
* Team or organization-level metrics
* Environment-specific monitoring (staging vs. production)
This enables:
* Per-user cost tracking and budgeting
* Personalized user analytics
* Team or organization-level metrics
* Environment-specific monitoring (staging vs. production)