 This setup enables Portkey's advanced features for Langchain.
## Key Portkey Features for Langchain
Routing Langchain requests via Portkey's `ChatOpenAI` interface unlocks powerful capabilities:
This setup enables Portkey's advanced features for Langchain.
## Key Portkey Features for Langchain
Routing Langchain requests via Portkey's `ChatOpenAI` interface unlocks powerful capabilities:
Use `ChatOpenAI` for OpenAI, Anthropic, Gemini, Mistral, and more. Switch providers easily with Virtual Keys or Configs.
Reduce latency and costs with Portkey's Simple, Semantic, or Hybrid caching, enabled via Configs.
Build robust apps with retries, timeouts, fallbacks, and load balancing, configured in Portkey.
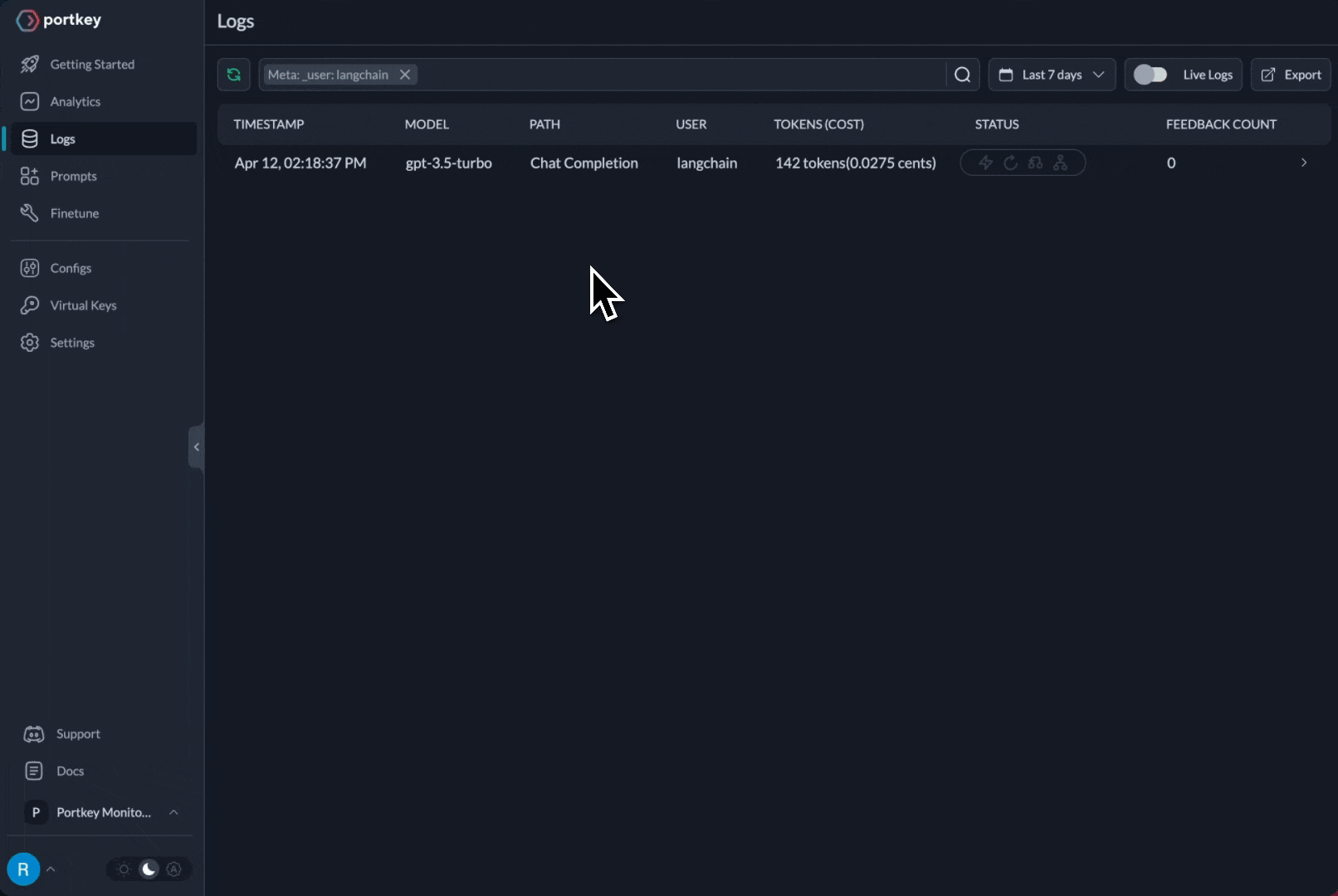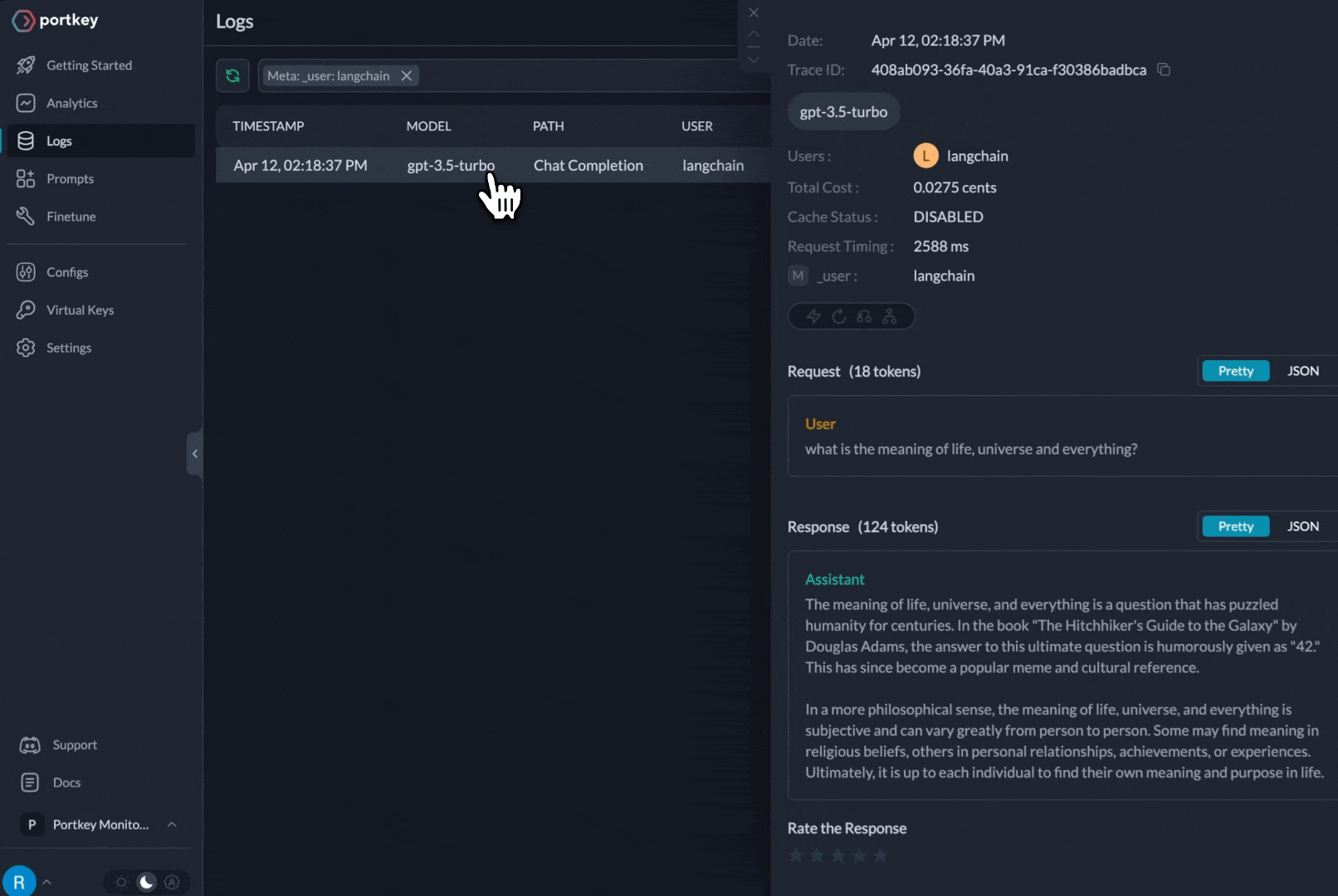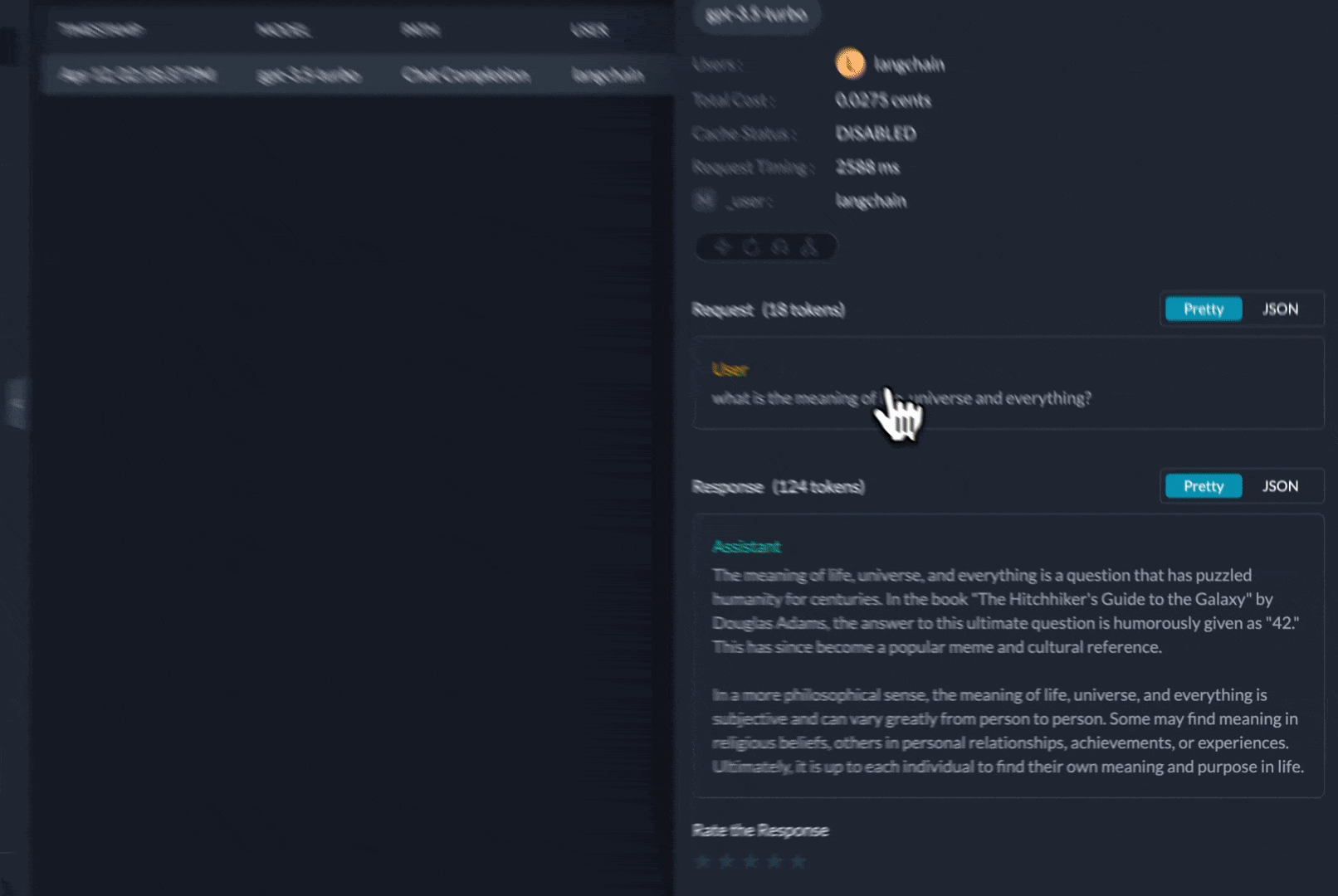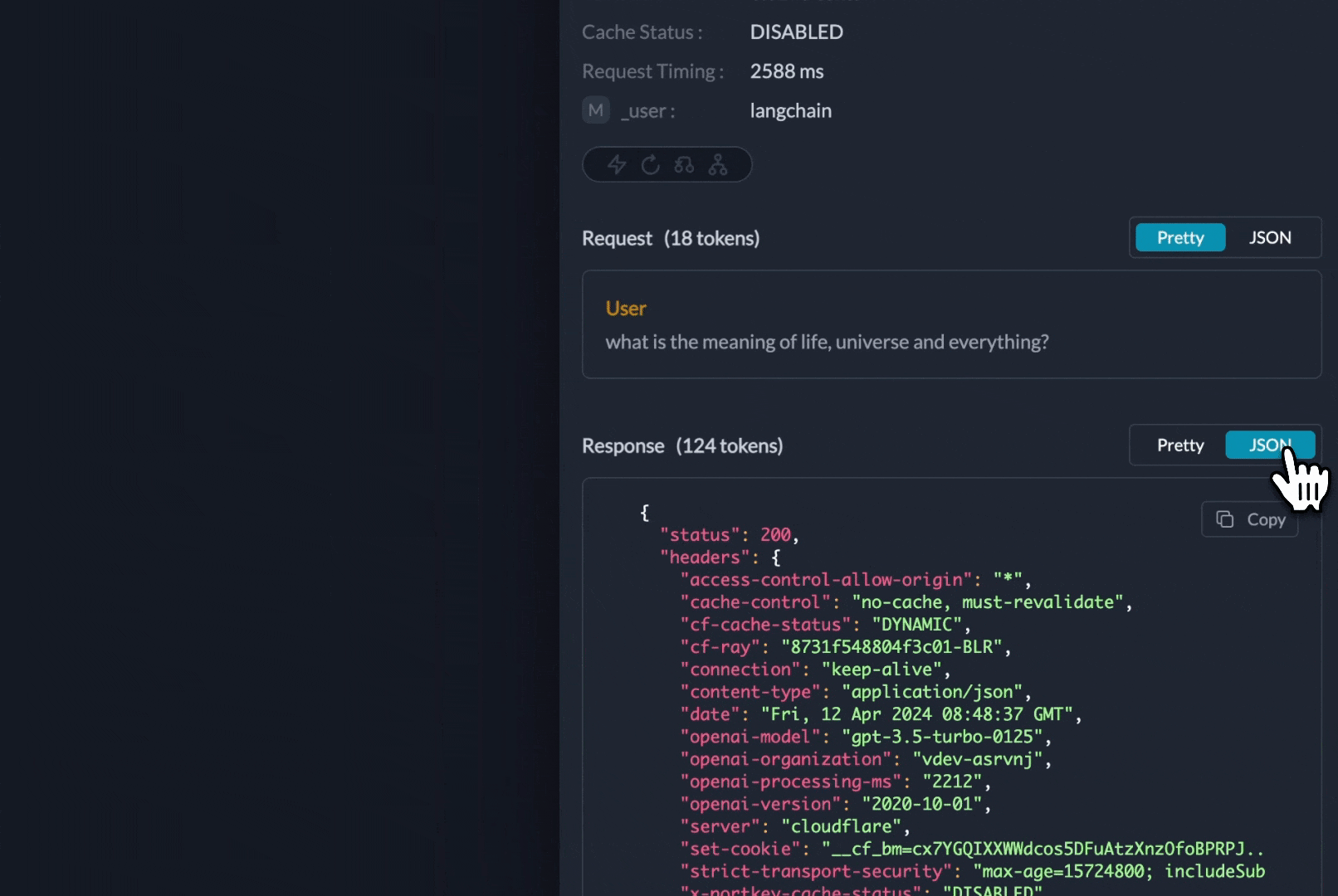
Get deep insights: LLM usage, costs, latency, and errors are automatically logged in Portkey.
Manage, version, and use prompts from Portkey's Prompt Library within Langchain.
Securely manage LLM provider API keys using Portkey Virtual Keys in your Langchain setup.
***
## 5. Prompt Management
Portkey's Prompt Library helps manage prompts effectively:
* **Version Control:** Store and track prompt changes.
* **Parameterized Prompts:** Use variables with [mustache templating](/product/prompt-library/prompt-templates#templating-engine).
* **Sandbox:** Test prompts with different LLMs in Portkey.
### Using Portkey Prompts in Langchain
1. Create prompt in Portkey, get `Prompt ID`.
2. Use Portkey SDK to render prompt with variables.
3. Transform rendered prompt to Langchain message format.
4. Pass messages to Portkey-configured `ChatOpenAI`.
```python theme={"system"}
import os
from langchain_openai import ChatOpenAI
from langchain_core.messages import SystemMessage, HumanMessage
from portkey_ai import PORTKEY_GATEWAY_URL, createHeaders, Portkey
PORTKEY_API_KEY = os.environ.get("PORTKEY_API_KEY")
client = Portkey(api_key=PORTKEY_API_KEY)
PROMPT_ID = "pp-story-generator" # Your Portkey Prompt ID
rendered_prompt = client.prompts.render(
prompt_id=PROMPT_ID,
variables={"character": "brave knight", "object": "magic sword"}
).data
langchain_messages = []
if rendered_prompt and rendered_prompt.prompt:
for msg in rendered_prompt.prompt:
if msg.get("role") == "user": langchain_messages.append(HumanMessage(content=msg.get("content")))
elif msg.get("role") == "system": langchain_messages.append(SystemMessage(content=msg.get("content")))
OPENAI_VIRTUAL_KEY = os.environ.get("OPENAI_VIRTUAL_KEY")
portkey_headers = createHeaders(api_key=PORTKEY_API_KEY, virtual_key=OPENAI_VIRTUAL_KEY)
llm_portkey_prompt = ChatOpenAI(
api_key="placeholder_key",
base_url=PORTKEY_GATEWAY_URL,
default_headers=portkey_headers,
model=rendered_prompt.model if rendered_prompt and rendered_prompt.model else "gpt-4o"
)
# if langchain_messages: response = llm_portkey_prompt.invoke(langchain_messages)
```
Manage prompts centrally in Portkey for versioning and collaboration.
***
## 6. Secure Virtual Keys
Portkey's [Virtual Keys](/product/ai-gateway/virtual-keys) are vital for secure, flexible LLM ops with Langchain.
**Benefits:**
* **Secure Credentials:** Store provider API keys in Portkey's vault. Code uses Virtual Key IDs.
* **Easy Configuration:** Switch providers/keys by changing `virtual_key` in `createHeaders`.
* **Access Control:** Manage Virtual Key permissions in Portkey.
* **Auditability:** Track usage via Portkey logs.
Using Virtual Keys boosts security and simplifies config management.
***
## Langchain Embeddings
Create embeddings with `OpenAIEmbeddings` via Portkey.
```python theme={"system"}
from langchain_openai import OpenAIEmbeddings
from portkey_ai import PORTKEY_GATEWAY_URL, createHeaders
import os
PORTKEY_API_KEY = os.environ.get("PORTKEY_API_KEY")
OPENAI_EMBEDDINGS_VIRTUAL_KEY = os.environ.get("OPENAI_EMBEDDINGS_VIRTUAL_KEY")
portkey_headers = createHeaders(api_key=PORTKEY_API_KEY, virtual_key=OPENAI_EMBEDDINGS_VIRTUAL_KEY)
embeddings_model = OpenAIEmbeddings(
api_key="placeholder_key",
base_url=PORTKEY_GATEWAY_URL,
default_headers=portkey_headers,
model="text-embedding-3-small"
)
# embeddings = embeddings_model.embed_documents(["Hello world!", "Test."])
```