
AI audit checklist for internal AI platform & enablement teams
A practical AI audit checklist for platform teams to evaluate access controls, governance, routing, guardrails, performance, and provider dependencies in multi-team, multi-model environments.

Internal AI platforms are becoming the backbone of how enterprises roll out GenAI across teams. As more departments adopt LLMs for research, experimentation, workflows, and production systems, platform and enablement teams end up owning a wide surface area: access, spend, routing, data handling, reliability, and compliance.
This expansion introduces a new kind of operational risk. AI systems are probabilistic, connected to multiple providers, and can shift behavior without changes in infrastructure. Models evolve, routing rules get updated, prompts drift, and usage patterns spike unexpectedly.
An AI audit checklist gives internal platform teams a systematic way to verify that their environment is governed, observable, cost-aware, and compliant while still enabling teams to build fast.
What makes AI audits different from traditional engineering audits
Traditional engineering audits focus on infrastructure, code quality, access, and operational readiness. AI audits extend far beyond that. AI systems behave differently from deterministic software, and the components that influence outcomes are broader, more dynamic, and often outside a team’s direct control.
An effective AI audit must therefore cover not just infrastructure, but the entire execution path: how models are selected, how requests are processed, how data is handled, how teams access the platform, and how consumption grows over time. It requires visibility into behavior, governance, and economics and not just system uptime.
AI Audit checklist area 1: Access & identity controls
AI platforms often support hundreds of internal users that is developers, analysts, researchers, product teams, and automated services. The first step in any AI audit is to review who has access to what, and whether that access matches current responsibilities and workloads.
Key items to audit:
• Model access policies per team and workspace
Confirm that each group can only use approved models, versions, and providers. As new models roll out, access should be intentionally granted as required.
• API key issuance, rotation, and deactivation
Inventory all user and service keys. Check if keys are rotated, tied to specific owners, and deactivated when someone leaves or roles change.
• Role-based access control for platform admins, builders, and consumers
Ensure that only the right people can modify configs, change routing, or alter logging and budget policies. Separation of duties is essential when many workloads rely on shared infrastructure.
• Workspace separation for departments and regulated workloads
Different teams like R&D, production, student apps, internal tools should have isolated environments to prevent accidental cross-impact.
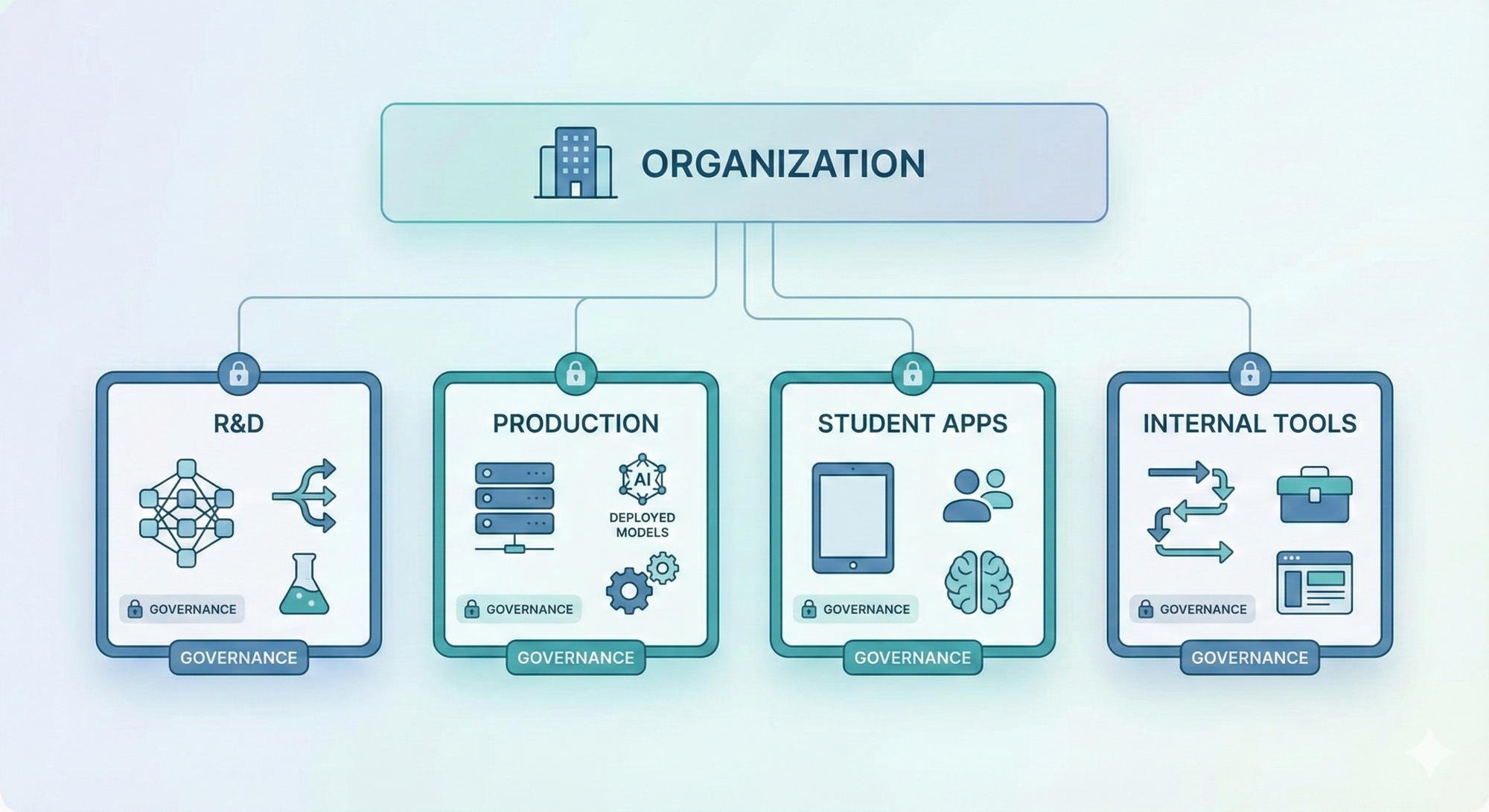
• Usage attribution using metadata and user-level keys
Every request should map back to a team, user, service, or application. Clear attribution makes cost management and incident investigations significantly easier.
Strong identity and access governance is the foundation of an auditable internal AI platform. Without it, the rest of the checklist becomes difficult to enforce consistently.
AI Audit checklist area 2: Usage governance & consumption controls
As internal usage expands, one of the fastest-growing risks is uncontrolled consumption. Different teams experiment at different scales, workloads shift quickly, and model pricing varies widely across providers.
Key items to review:
• Spend visibility across teams, workloads, and regions
Ensure every unit of spend can be traced back to a team, workspace, or application. Lack of LLM observability is the primary reason AI costs spike without warning.
• Budget policies and rate limits applied consistently
Budget and rate limits shouldn’t live on spreadsheets. They should be enforced at runtime by team, workspace, metadata tags, or specific services. Confirm that policies exist and actually govern requests.
• Alerts for anomalous token usage or sudden provider spikes
Spikes may indicate bugs, runaway agents, infinite loops, or misconfigured prompts. Alerts should catch unusual patterns early.
• Cost differences across models and their routing impact
Model selection often shifts over time. An audit checks whether models are being used where appropriate, and whether production workloads rely on the highest-cost options unnecessarily.
• Separation of experimentation and production spend
Experimental workloads can generate thousands of calls quickly. Ensure they’re isolated from production budgets, and governed by stricter rate limits or lower-cost models.
AI Audit checklist area 3: Request logging, observability & audit trails
For internal AI platforms, every request across every team and provider should be traceable. Without unified visibility, it becomes nearly impossible to diagnose failures, audit behavior, or understand how applications are using LLMs in practice.
Key items to review:
• Centralized logging for all LLM calls across providers
All prompts, responses (as permitted), metadata, and routing decisions should land in a single place. Fragmented logs create blind spots during investigations.
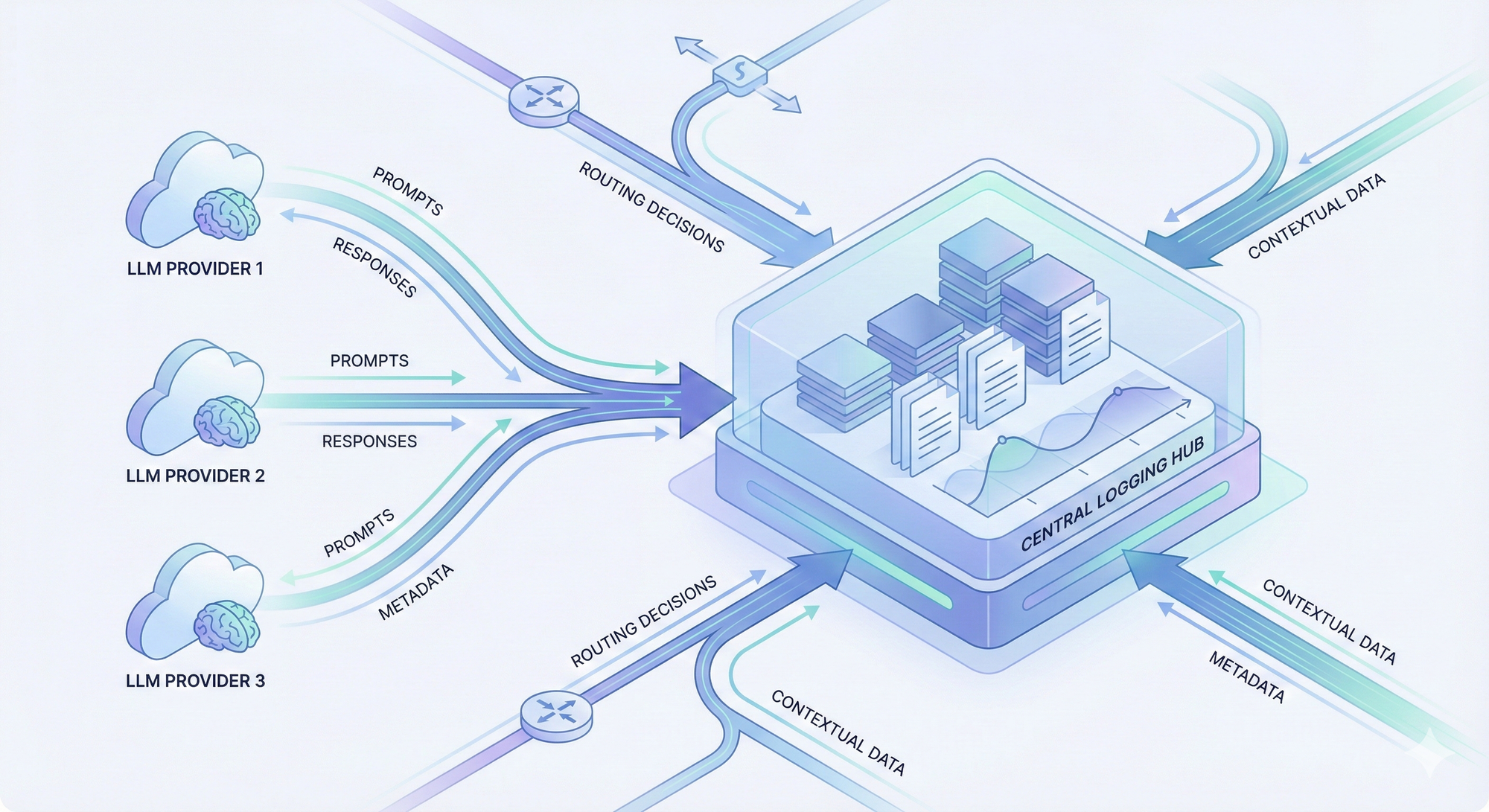
• Ability to reconstruct end-to-end execution for any request
You should be able to answer: Which model was selected? What fallback happened? Why was a retry triggered? What metadata was attached?
• Workspace-level and org-level logging policies
Teams should have the flexibility to control log detail, but governance must ensure that no workload bypasses required logging.
• Traceability for retries, fallbacks, and routing logic
LLM requests often involve multiple hops. An audit checks that these are captured cleanly so teams can understand behavior under load or during provider issues.
• Full audit trail for platform configuration changes
With audit logs, track who changed what — routing rules, budgets, guardrails, cache TTLs, keys — and when. This is essential for debugging and compliance.
AI Audit checklist area 4: Model governance & routing behavior
As model catalogs expand and providers ship updates frequently, internal AI platforms need a clear policy for how models are approved, deployed, and routed. An audit ensures that the models teams rely on are safe, supported, and consistently used across environments.
Key items to review:
• Approved models list and deprecation workflow
Teams should operate only against vetted models. The audit checks whether outdated or unapproved models are still in use, and whether a formal deprecation process exists.
• Routing rules across teams and applications
Different workloads may optimize for latency, cost, or accuracy. Review whether routing rules reflect these priorities and whether teams adhere to them.
• Fallback paths and error handling
Providers fail or rate-limit. An audit verifies fallback routing, error response flows, and retry strategies so no critical workload depends on a single point of failure.
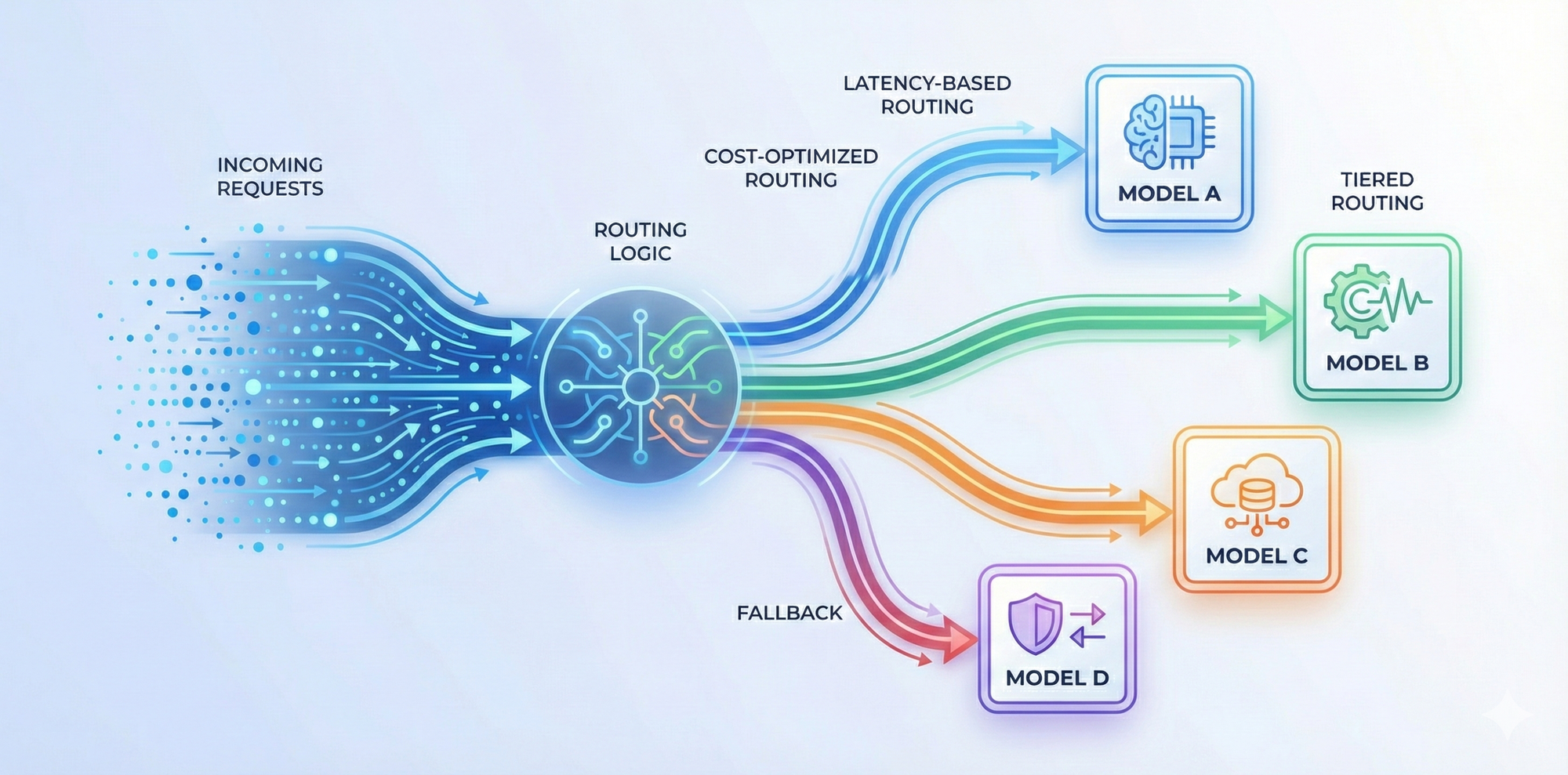
• Circuit breakers and protection against degraded providers
If a model or provider slows down or misbehaves, routing should adapt automatically. Check whether circuit breakers exist and whether they’re tested regularly.
• Performance and latency drift detection
Models improve or regress over time. Audit whether teams are monitoring drift in latency, quality, or token efficiency and whether that influences routing decisions.
AI Audit checklist area 5: Safety, guardrails & data handling
Internal AI platforms must ensure that every workload adheres to consistent safety and data policies. The audit verifies that guardrails and data policies are correctly implemented and consistently enforced.
Key items to review:
• Input and output filtering for sensitive data
Check whether prompts containing PII, PHI, or regulated data are being filtered, masked, or rejected. Output filters should prevent unsafe or policy-violating content from reaching applications.
• Redaction and data minimization controls
Verify that logs don’t store unnecessary sensitive data and that redaction policies are applied uniformly across workspaces.
• Enforcement of data residency and region rules
Teams should not be able to route regulated workloads to unapproved regions. Confirm that region-level routing policies are enforced at runtime, not just documented.
• Prompt safety and response moderation policies
Ensure that safety layers toxicity, jailbreak detection, misinformation checks are active, up to date, and standardized across apps.
• Guardrail consistency across teams and environments
Workspaces should not implement divergent or ad-hoc guardrails. Audit whether the same rules apply across development, testing, and production.
• Data retention and deletion policies
Review retention timelines, deletion workflows, and how consistently they’re followed. AI logs often carry sensitive content; retention must be intentional.
AI Audit checklist area 5:Workspace governance
Key items to review:
• Workspace isolation for teams, environments, and regulated workloads
Teams working on experiments shouldn’t share configs or logs with production workloads. Check whether workspaces are cleanly separated for dev, staging, prod, research, or compliance-bound applications.
• Version control for configs, prompts, and routing rules
Prompts, guardrails, and model selection logic change frequently. An audit evaluates whether these changes are versioned, peer-reviewed, and documented not edited in place.
• Rollback capability for unsafe or incorrect changes
Teams should be able to revert a bad config quickly. An audit checks whether rollback workflows exist and whether teams use them consistently.
• Ownership clarity for each workspace and config set
Every workspace should have defined owners who are responsible for routing rules, budgets, prompts, and guardrails. Lack of ownership is a common source of misconfiguration.
AI Audit checklist area 5: Performance, reliability & scaling
High-volume internal AI platforms must deliver consistent performance across providers, workloads, and teams. As usage scales, reliability issues can surface in unexpected ways latency spikes, token inefficiencies, provider outages, and cascading retries.
Key items to review:
• Latency benchmarks across providers and models
Ensure teams are tracking real latency, not just provider-stated numbers. Drift in latency or throughput may indicate routing issues, provider degradation, or missing caching opportunities.
• Error rates, retry patterns, and provider-specific failures
Review error logs to understand where failures cluster. Excess retries often point to poor routing rules or provider instability.
• Caching effectiveness and TTL governance
Confirm that caching is saving cost and reducing latency not introducing stale responses or incorrect TTLs. Check cache hit ratios for major workloads.
• Throughput handling and batching performance
For high-volume workloads, batching becomes critical. Audit whether batching is configured correctly and whether it’s improving throughput without compromising correctness.
• Circuit breakers and failover behavior under stress
Provider outages or quota issues shouldn’t interrupt production workloads. Review how automatically (and gracefully) the platform reroutes traffic under load.
• SLA adherence and monitoring
Teams should know whether provider SLAs are being met. Significant deviations need review, especially when tied to business-critical workflows.
AI Audit checklist area 6: Vendor, provider & procurement dependencies
Key items to review:
• Provider distribution and single-vendor concentration risk
Check how much of your internal AI traffic is tied to one provider. Heavy concentration increases vulnerability to outages, price changes, or policy shifts.
• Region availability and data residency compliance
Teams should not be routing workloads to unauthorized regions. Verify which regions each provider supports and how traffic maps to those regions across workspaces.
• Dependency on proprietary features
Some workloads rely on provider-specific APIs, embeddings, or safety layers. Audit whether critical systems are locked into features that limit portability.
• Tracking pricing changes and cost deltas across providers
Model pricing shifts frequently. Audit whether the platform is monitoring changes and adjusting routing or model selection accordingly.
Pulling it all together: A reusable AI audit template for platform teams
A simple way to operationalize this is to establish a quarterly or semi-annual audit cycle, with clear owners and standardized artifacts. Each cycle should answer a few core questions:
• Are access, workspace, and identity boundaries still accurate?
Teams change roles frequently, and misaligned permissions accumulate quickly.
• Are consumption, budgets, and rate limits under control?
Unexpected spend patterns are often the first sign of misconfiguration or drift.
• Are logs, traces, and audit trails complete and usable?
If an incident occurs, teams must be able to reconstruct what happened.
• Are routing, model usage, and performance aligned with current needs?
Model catalogs and latency characteristics shift over time; governance should keep pace.
• Are safety, data handling, and guardrails consistently enforced?
As more teams build AI features, consistency becomes harder — and more critical.
• Are provider dependencies intentional and resilient?
Vendor strategy should support reliability and cost goals, not surprise them.
Getting ready for the AI Audit
Internal AI platforms succeed when governance grows in step with adoption. As more teams experiment, ship features, and move workloads to production, the surface area that needs to be monitored and audited expands quickly.
A structured audit checklist gives platform and enablement teams a clear way to stay ahead ensuring access is controlled, spend is predictable, safety is consistent, and routing behaves the way it should.
Platform teams use Portkey's AI Gateway to bring consistency to multi-provider AI environments with unified access control, policy enforcement, routing governance, observability, and cost oversight all in one place. Instead of stitching together logs, configs, budgets, and provider settings manually, Portkey gives teams a single layer to manage how AI is used across the organization.
If you’re building or scaling an internal AI platform and want clearer governance, predictable spend, and production-grade reliability, Portkey can help you get there faster. Let’s talk.