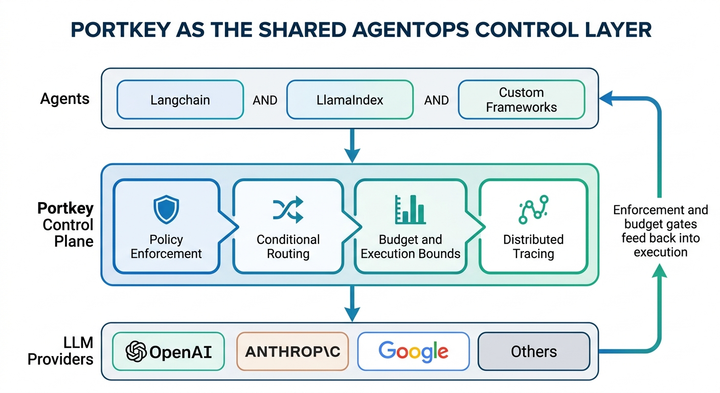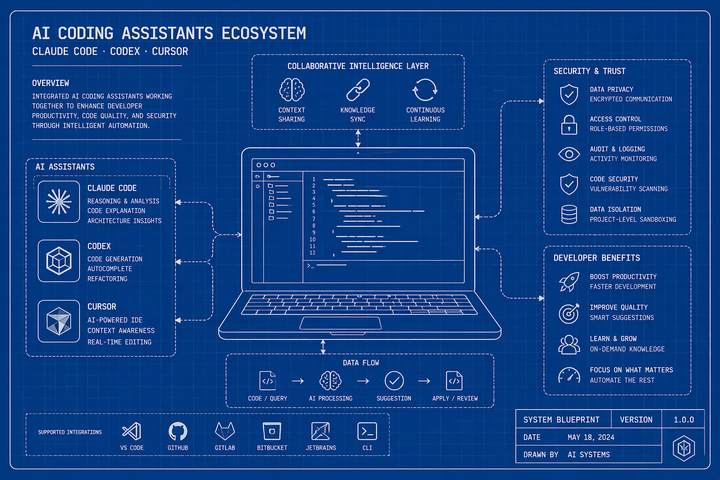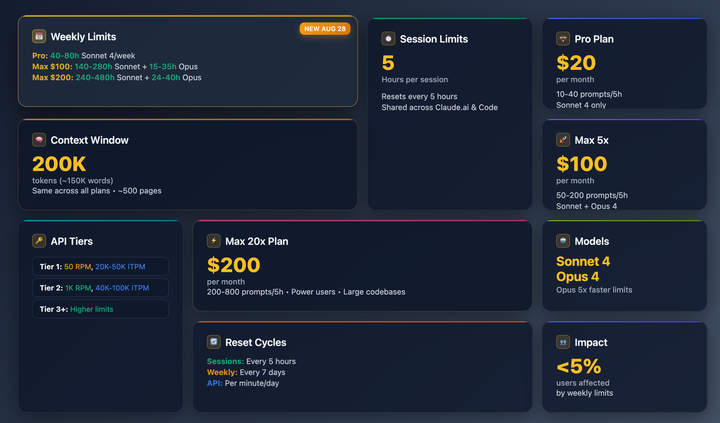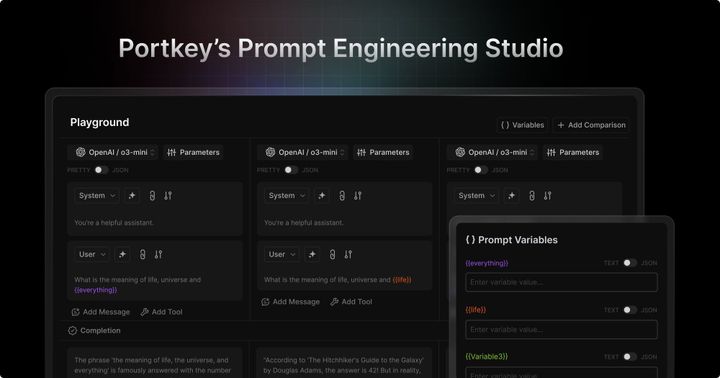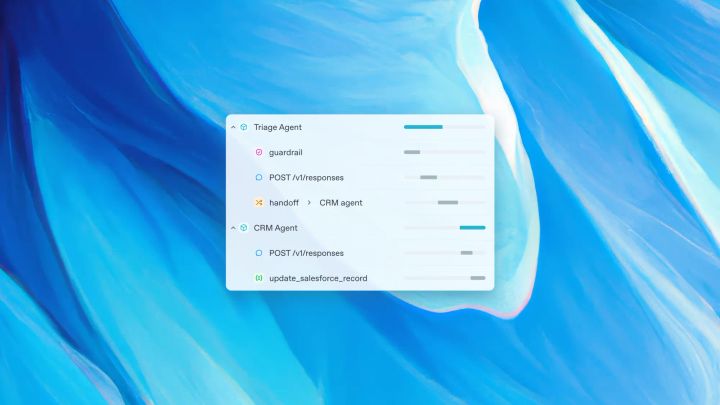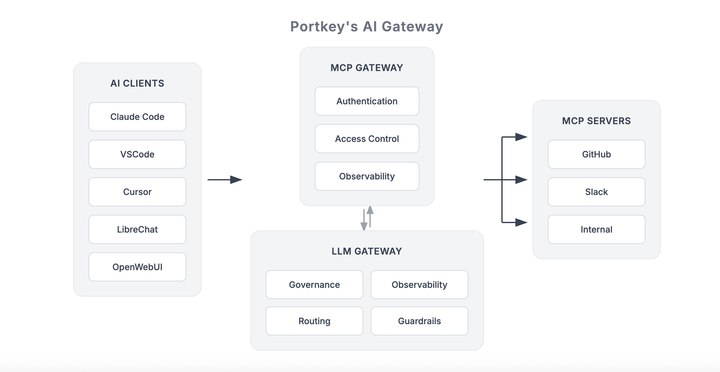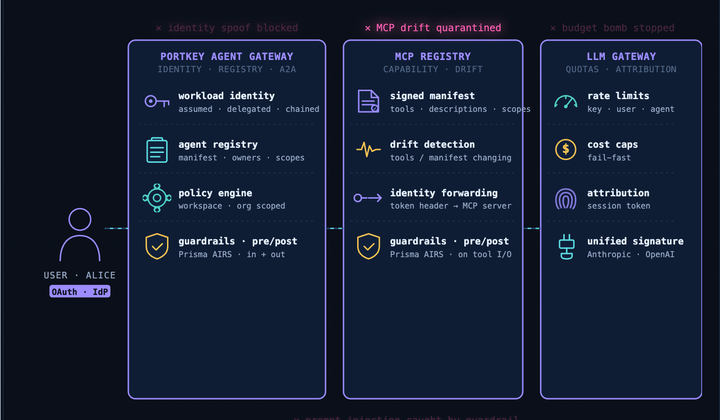
Why Every Agent Vulnerability is a Trust Boundary Failure
Consider these scenarios
* An MCP server quietly returning extra tool descriptions
* Prompt injection through a calendar invite
* An Agent invokes a tool that the principal should not have access to
* Cost overruns
It isn't the model that failed. It isn't the tool that failed. What failed