AI cost observability: A practical guide to understanding and managing LLM spend
A clear, actionable guide to AI cost observability—what it is, where costs leak, the metrics that matter, and how teams can manage LLM spend with visibility, governance, and FinOps discipline.

In most organizations, model access has scaled faster than cost visibility. Teams know their total monthly spend but not which model, prompt, or workspace is responsible for it. This lack of granularity makes optimization reactive rather than strategic.
AI cost observability bridges that gap. It brings clarity to the most opaque part of AI operations, showing how, where, and why tokens are consumed. When done right, it turns cost from a post-facto finance report into a real-time operational signal.
That’s why we built the MCP Gateway: a centralized control layer to run MCP-powered agents in production.
Check it out!
What cost observability really means
AI cost observability goes beyond a monthly usage report or a provider invoice. It provides a real-time, granular view of how model spend is generated across your systems.
Instead of tracking cost at the provider level, it breaks it down into the units that actually matter for operations, tokens, prompts, users, tools, and workflows.
AI cost observability should answer three questions:
- Where is spend coming from?
Which models, prompts, routes, agents, or teams are driving usage? - Why is it happening?
Are costs rising because inputs are longer, retries are increasing, or a workflow changed? - Is the spend justified?
Does the output quality, latency, or business value align with what you’re paying?
Unlike generic billing dashboards, cost observability ties financial signals to context. It allows engineering, platform, FinOps, and product teams to view cost through the same lens, one that reflects how LLMs actually behave in production.
This makes optimization predictable rather than speculative. When you can see spend per request, per agent step, or per workspace, it becomes far easier to detect anomalies, choose the right models, and enforce governance policies without slowing teams down.
Where costs leak in LLM systems
Most AI teams don’t overspend because of one big issue, they overspend because of dozens of small, invisible leaks that add up over time. These leaks usually sit deep inside prompts, workflows, retries, or agent behavior, making them impossible to detect without proper telemetry.
Here are the most common sources:
1. Long contexts that quietly inflate tokens
Teams often concatenate conversation history, system prompts, or retrieved documents without trimming or compressing them. Even a few hundred extra tokens repeated across thousands of requests can cascade into a significant monthly cost.
2. Retries and auto-failover patterns
Backoff retries, provider errors, or aggressive failover strategies can multiply cost per request especially if they route to a more expensive fallback model.
3. Unbounded tool use in agents
Multi-step agents that call tools recursively, fetch external data, or replan frequently can generate surprisingly high token consumption. Without agent-level tracing, these costs remain hidden.
4. Silent model or version changes
Switching from one version to another (or being auto-upgraded by a provider) can increase price-per-token without anyone noticing.
5. Caching misses or misconfiguration
A cache that’s too small, incorrectly keyed, or disabled for specific workflows can eliminate an easy 30–90% cost saving.
6. Shadow usage and shared credentials
Provider keys reused across teams lead to usage spikes with no clear owner — a common issue in early AI platform setups.
7. Unoptimized prompts
Redundant instructions, verbose outputs, and lack of response constraints cause runaway token generation on both input and output sides.
These leaks are rarely obvious, and without visibility into how each request behaves, organizations end up reacting to spend after it happens instead of managing it proactively. This is where cost observability becomes essential.
Core pillars of AI cost observability
These pillars ensure that cost becomes a measurable, explainable part of your AI stack.
1. Instrumentation
Cost observability starts with capturing the right signals. This means logging token counts, model metadata, latency, retries, routing decisions, and guardrail outcomes for every request, all tied to a unique trace or span. Without instrumentation, cost remains a provider-side number with no actionable context.
2. Attribution
Once captured, cost needs to be mapped to the right owners. Attribution links every dollar spent to a workspace, model, project, user, agent, or tool. This prevents shadow usage and creates accountability across teams. Good attribution makes it clear who is consuming what and why.
3. Correlation
By connecting spend to signals like latency, quality, safety pass rate, or grounding accuracy, teams can evaluate whether paying more actually leads to better outcomes. Correlation also reveals inefficiencies such as rising cost per successful request or cost spikes tied to model drift.
4. Forecasting
With accurate historical data, teams can predict and plan. Forecasting helps detect unusual spikes, estimate future budgets, and evaluate whether usage patterns are sustainable. It shifts AI cost management from reactive to proactive and helps teams avoid end-of-month surprises.
5. Governance
Governance brings guardrails and controls on top of visibility. This includes budgets, per-workspace limits, anomaly alerts, routing rules, and enforcement policies that ensure spend stays within defined boundaries. Governance turns cost LLM observability into an operational safety net.
Together, these pillars transform token-level telemetry into a complete cost management framework, one that supports both engineering and finance teams as AI adoption scales across the organization.
Metrics that matter
Good cost observability is about surfacing the right metrics that make spend predictable and explainable. The goal is to help engineering, platform, and finance teams speak the same language when evaluating AI usage.
These are the metrics that consistently matter in production:
1. Cost per request
The foundational unit of AI spend. It shows how much each prompt-response cycle costs and makes it easy to spot expensive workflows or routes. Breakdowns by model, provider, and workspace help diagnose anomalies quickly.
2. Cost per user or per workspace
Shows how spend is distributed across the organization. This is essential for showback, budgeting, and understanding which teams or products drive usage. It also uncovers shadow users or unexpected workloads.
3. Cost per project or product surface
Links spend to business value. Whether it’s a customer-facing chatbot, an internal agent, or a research workflow, this metric helps teams understand which initiatives justify their cost and which may need optimization.
4. Token efficiency and “cost per successful outcome”
A more meaningful measure than token count alone. This connects cost to performance by tracking:
- Tokens per accurate output
- Tokens per grounded answer
- Tokens per completed agent task
Efficiency metrics help teams compare models beyond price-per-token by factoring in real outcomes.
5. Cached vs uncached savings
One of the clearest indicators of optimization ROI. A cache hit rate dashboard shows how much spend is being avoided through response reuse. Even a small increase in hit rate can drive significant monthly savings.
6. Budget burn rate
How quickly each team or workspace is consuming its allocated budget.
Burn rate helps identify sudden spikes, unmanaged usage, or workflows that need throttling.
7. Cost anomalies and variance
Alerts and dashboards that highlight:
- Sudden increases in request volume
- Unexpected model switches
- Retries or error loops
- Token explosions caused by prompt changes
Anomaly detection ensures teams don’t find out about cost overruns at the end of the month.
8. Model comparison dashboards
Side-by-side views of cost vs latency vs quality across providers. This helps choose the most efficient model for each use case and supports routing strategies based on performance or budget constraints.
Strategies to improve cost efficiency
Once teams have visibility into how tokens are being consumed, the next step is improving efficiency without compromising performance.
1. Apply caching where it makes sense
Caching responses for common queries, workflows, or agent substeps can reduce cost by 30–90% without affecting accuracy. High-impact areas include:
- FAQs and support flows
- Deterministic tool results
- Agent “setup” steps or planning phases
The key is to tune cache TTLs, surface hit/miss metrics, and structure prompts so they yield consistent caching keys.
2. Batch requests to reduce overhead
Batching multiple inputs into a single LLM call reduces repeated system prompts and shared context tokens. It’s one of the easiest ways to lower cost while improving throughput.
3. Optimize context length
Long context windows often hide the biggest cost spikes.
Teams can reduce input tokens by:
- Trimming conversation histories
- Summarizing intermediate steps
- Using structured memory instead of raw transcripts
- Limiting retrieved documents to top-k relevant chunks
Small reductions in input length compound into large monthly savings.
4. Choose models intelligently with routing
Different models have different trade-offs and not every request needs a frontier-level LLM. Routing strategies help decide when to use:
- Fast, inexpensive models for routine tasks
- Larger models for reasoning-heavy or high-stakes queries
- Rerouting when quality thresholds aren’t met
Dynamic routing preserves performance while minimizing unnecessary cost.
5. Improve prompt hygiene
Poor prompts can significantly inflate output tokens.
Teams can reduce cost by:
- Removing redundant instructions
- Using stricter output constraints (e.g., JSON only)
- Keeping few-shot examples short and relevant
- Versioning and comparing prompts over time
Prompt reviews often deliver immediate savings.
6. Budget and alerting controls
Even with good optimization, teams need guardrails.
Budgets, per-workspace limits, and cost alerts prevent runaway spend caused by:
- Bad deployments
- Infinite loops in agents
- Unexpected usage spikes
- Provider-side changes
Controls ensure spend remains predictable and aligned with business expectations.
Integrating cost observability with FinOps
As AI usage grows across an organization, LLM spend needs the same financial discipline that cloud infrastructure already operates under. FinOps provides that framework but it only works when teams have real visibility into how and where tokens are consumed.
Cost observability gives finance, platform, and engineering teams a shared source of truth. It connects technical signals (tokens, prompts, retries, routing decisions) to financial outcomes, making AI spend predictable instead of reactive. With clear attribution to workspaces, teams, and projects, organizations can run showback or chargeback models, reduce shadow usage, and encourage responsible consumption.
Integrating cost observability with FinOps creates a single accountability loop across departments, ensuring that AI efforts remain efficient, governed, and aligned with business value as they scale.
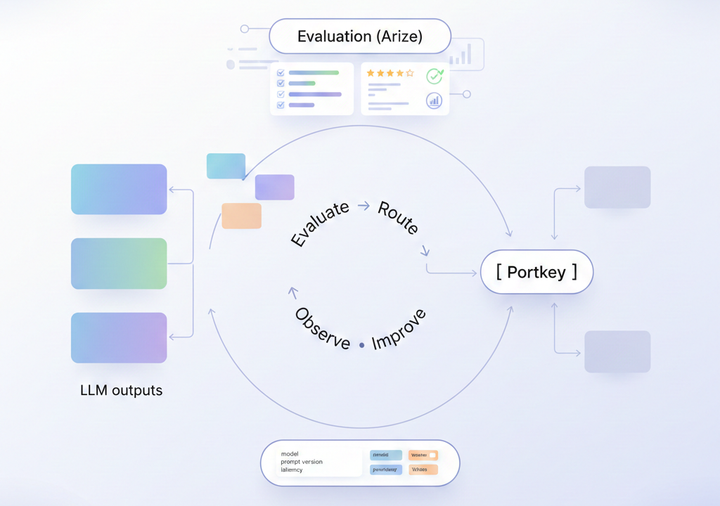
How Portkey enables cost observability
Portkey brings cost visibility directly into the model execution layer, which means every request carries the metadata needed to understand spend in real time. Token counts, retries, routing decisions, guardrail outcomes, and provider-level pricing are all captured automatically giving teams an itemized view of cost for every workspace, model, and user.
Because Portkey standardizes telemetry across all providers, organizations can compare model efficiency, detect anomalies, and forecast budgets without stitching together multiple dashboards. Budgets, limits, and alerts help keep usage controlled, while caching and routing insights highlight areas where efficiency can be improved immediately.
For teams operating multiple AI products or supporting multiple departments, Portkey becomes the source of truth that links engineering behavior, financial reporting, and operational governance, making cost observability part of the platform, not a separate tool.
Bringing cost observability into your AI operations
As organizations scale their AI initiatives, understanding token-level spend becomes just as important as monitoring latency or reliability. With the right visibility and controls, cost becomes a manageable dimension of your AI stack, one that supports informed decisions, responsible usage, and sustainable growth.
Portkey's AI Gateway gives teams a unified, provider-agnostic layer for cost observability, capturing token counts, per-request spend, budgets, anomalies, and routing insights across all models and workspaces.
If you're building AI products at scale and want clearer visibility into how every token is consumed, Portkey can help. Book a detailed walkthrough or sign up and get started today.