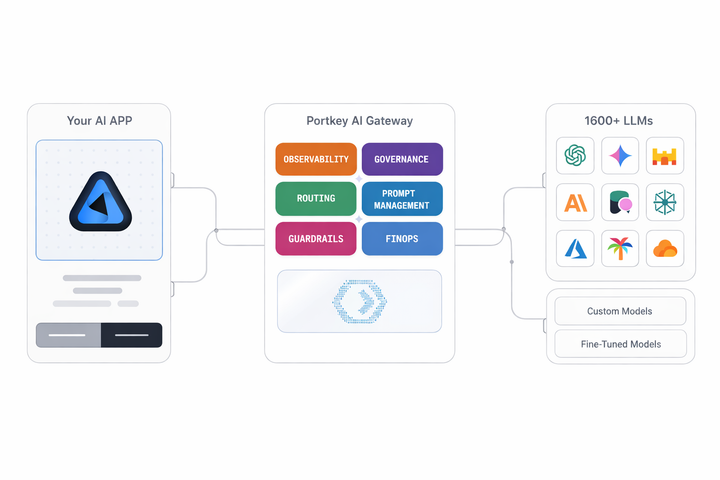
What is an LLM Gateway? Understand how LLM Gateways help organizations run LLMs as shared infrastructure with consistent governance, security, and observability.
Using Prompt Chaining for Complex Tasks Master prompt chaining to break down complex AI tasks into simple steps. Learn how to build reliable workflows that boost speed and cut errors in your language model applications.
FinOps practices to optimize GenAI costs and maximize efficiency Learn how to apply FinOps principles to manage your organization's GenAI spending. Discover practical strategies for budget control, cost optimization, and building sustainable AI operations across teams. Essential reading for technology leaders implementing enterprise AI.
Elevate Your ToolJet Experience with Portkey AI Integrate Portkey with ToolJet to unlock observability, caching, API management, and routing, optimizing app performance, scalability, and reliability.
Chain-of-Thought (CoT) Capabilities in O1-mini and O1-preview Explore O1 Mini & O1 Preview models with Chain-of-Thought (CoT) reasoning, balancing cost-efficiency and deep problem-solving for complex tasks.
OpenAI - Fine-tune GPT-4o with images and text OpenAI’s latest update marks a significant leap in AI capabilities by introducing vision to the fine-tuning API. This update enables developers to fine-tune models that can process and understand visual and textual data, opening up new possibilities for multimodal applications. With AI models now able to "see"
OpenAI’s Prompt Caching: A Deep Dive This update is welcome news for developers who have been grappling with the challenges of managing API costs and response times. OpenAI's Prompt Caching introduces a mechanism to reuse recently seen input tokens, potentially slashing costs by up to 50% and dramatically reducing latency for repetitive tasks. In