Building Production-Ready RAG Apps
Hasura helps you build robust RAG data pipelines by unifying multiple private data sources (relational DB, vector DB, etc.) and letting you query the data securely with production-grade controls.
LLMs have been around for some time now and have shown that they are great for tasks like content/code generation, conversations, brainstorming, etc. The only thing limiting us at the moment is our creativity and knowledge cutoff.
Knowledge Cutoff?
Yes, LLMs are frozen in time. At the time of writing this post, ChatGPT’s most recent knowledge cutoff date is September of 2021. Which means, if you ask it any questions after the cutoff date, it is likely to give a highly unreliable answer. Not just that, a tool like ChatGPT will also not have the context of your propreitary data and knowledge. If you ask it something about your internal or real-time data, which it has never seen, it will most likely just make up an answer, also called hallucinating.
On top of this, you are also limited by the LLM's context (or token) length - you can only send a certain amount of tokens in each prompt. For example, let's say you want to manually understand your codebase and answer any question on it - you can’t understand all the details from just a few functions or pages. Likewise, LLMs can’t answer accurately with limited context in all cases.
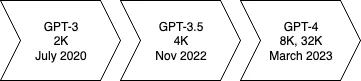
As Moore’s law has it, the context window for LLMs has also been steadily increasing across providers. OpenAI's GPT-4 now has 4x the context window of the GPT-3 model. (And goes upto 32k tokens if you're lucky!)
Anthropic also released a 100k context window model, Claude which can process ~240 pages of API docs in a single prompt!
However, it's important to note that bigger context window doesn't solve all problems. Recent research shows that a longer context can also decrease model performance.
All in all, building production-grade LLM apps on top of your data is challenging! So, what's the best way ahead? One trick is, Retrieval Augmented Generation or RAG.
RAG fetchs the most relevant context from the data based on the user query, so that LLMs can generate their answer based on the context and give grounded contextual responses.
We’re still in the early days of Gen AI and the tech is quickly evolving. While retrieving the right context and adhering to the context length is a critical component to the quality of results, you also have to deal with many more such decisions:
- What is the best vector DB in terms of cost and performance?
- What is the best chunking strategy?
- How do we avoid malicious attacks for different LLM data query patterns?
- What is the best model in terms of cost and performance?
- And then issues around reliably serving the app itself – how to debug when something goes wrong? How to monitor the model’s performance?
- ..and many more
All of which force engineers to spend a lot of time outside of building the core product.
What is the core product here though, and what is the surrounding tech? Here's how we think about LLM application stack:
- The First Layer – What you're actually building for your customers, e.g., chatbot to resolve issues with online orders.
- The Second Layer – The business logic that determines the execution, e.g., how the chatbot responds to incomplete order complaints.
- The Third & Fourth Layers – The foundational layers with context-augmented LLMs and data sources.
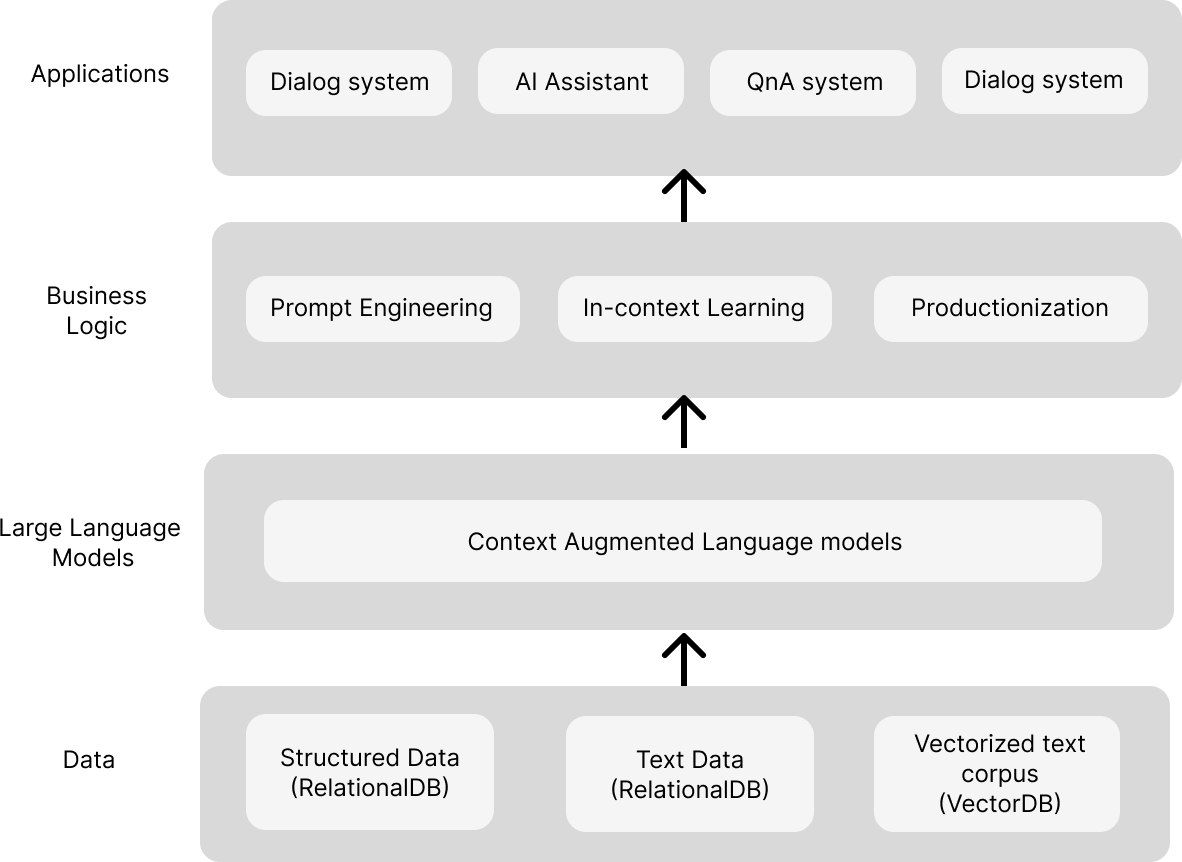
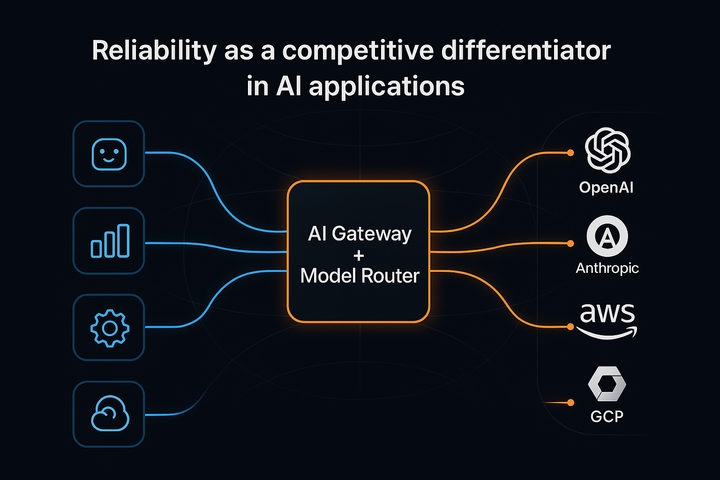
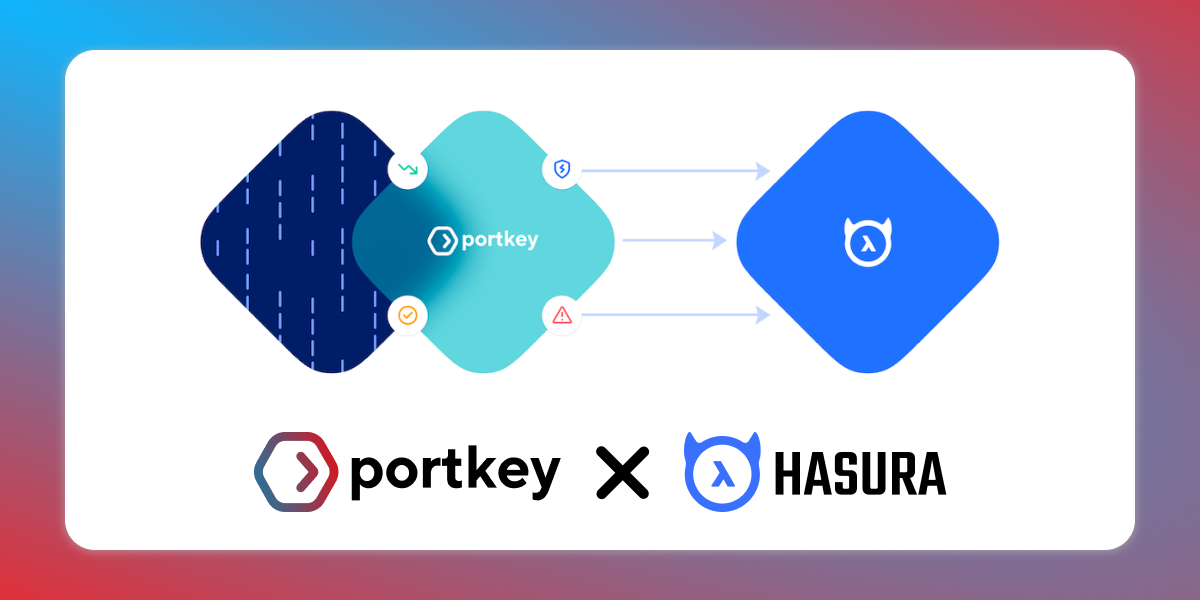
You will spend a considerable amount of time at the 3rd & 4th layers when it comes to productionizing the app and making it secure. Which is where, the combination of Hasura & Portkey can give you an advantage and save crucial time spent constructing data APIs and setting up LLMOps.
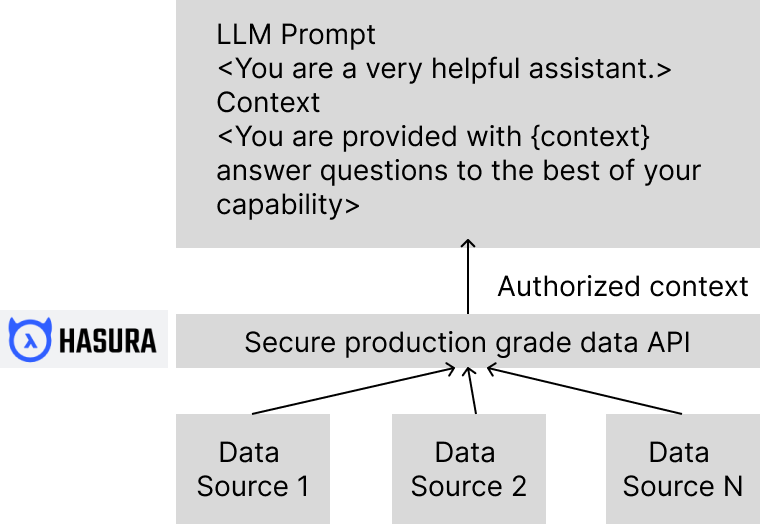
Hasura's Data APIs to Streamline Data Retrieval & Access
Data-driven applications have always required secure data access. RAG apps bring in new data query challenges:
- Time-consuming
Building data APIs for multiple data sources with authentication and authorization, like role-based access control, is time-consuming and not optimized for performance, scalability, or reliability. - Security is not easy
Securely querying vector databases is challenging. Vector databases are not connected to the application data model, making it difficult to query vectors for specific entities or apply access permissions. - Integration is complex
Vector data stores with additional metadata that require syncing data between application and vector databases. There is a high risk of the vector database going out of sync, leading to stale results.
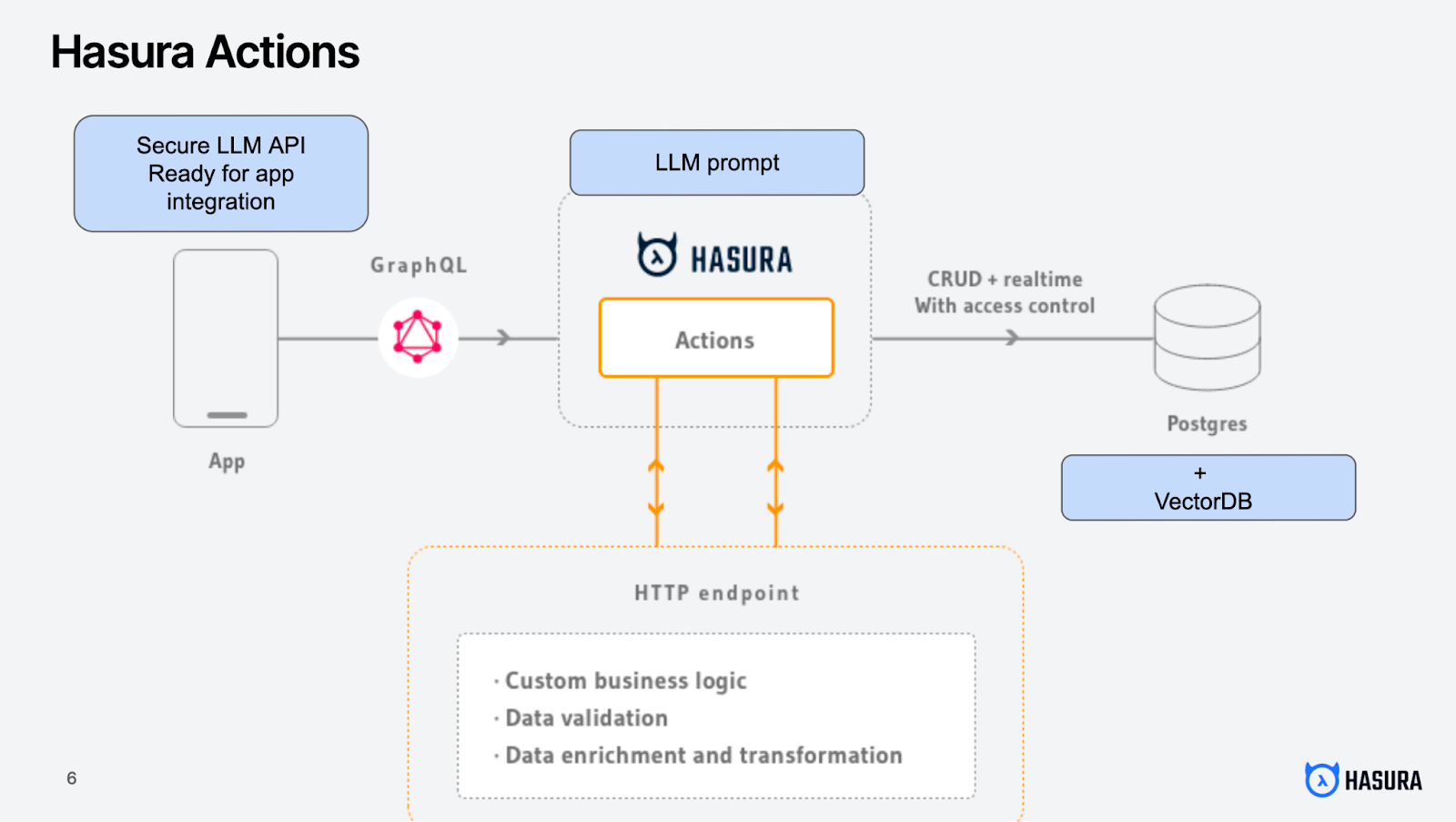
Hasura enables you to build production-grade data APIs in no time, unifying your multiple private data sources to give you secure, unified query capabilities with authentication and role-based access control.
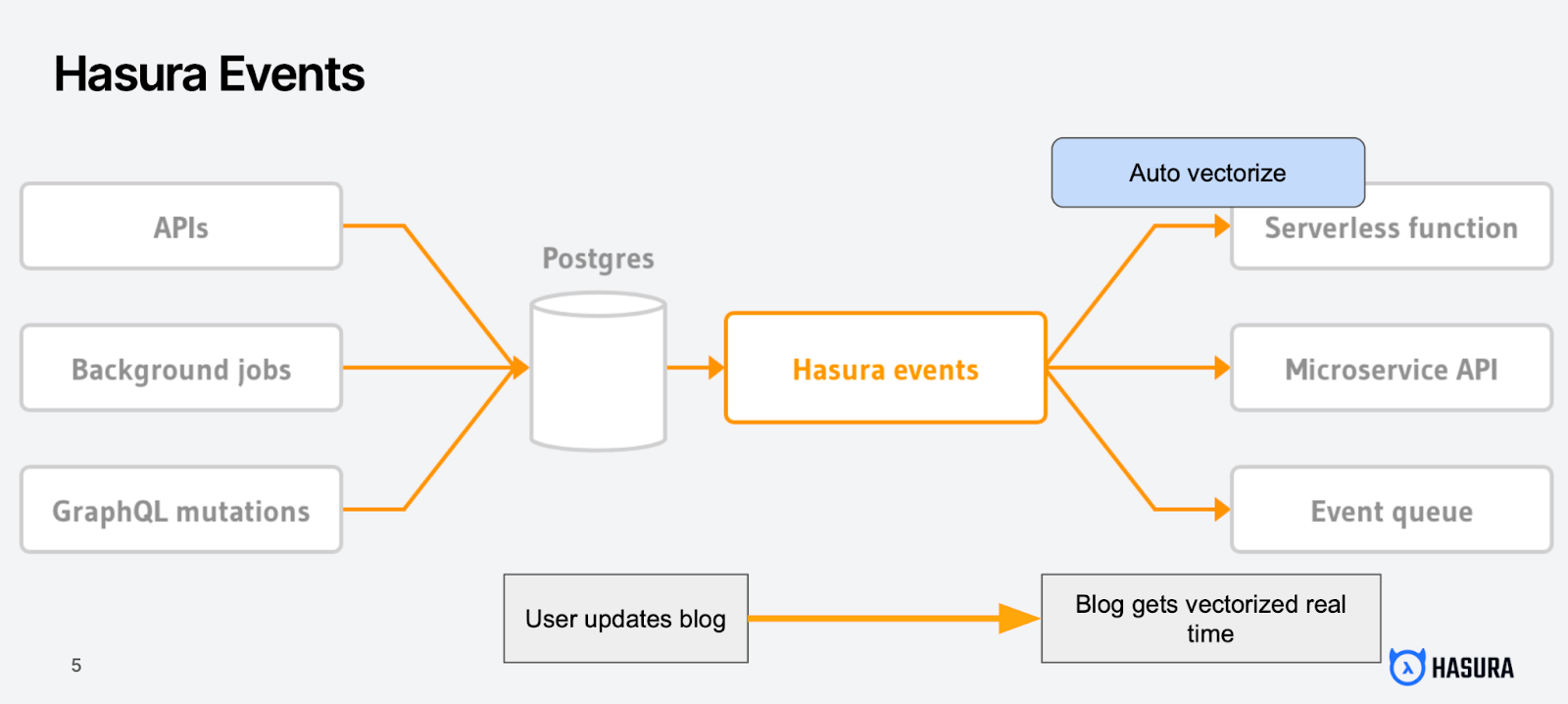
Hasura can help you to keep your data stores in sync with Event and Scheduled Triggers to automatically vectorize data whenever a CRUD event happens on your data.
Easily convert any business logic into a secure API using Hasura Actions, including your LLM queries.
Portkey's LLMOps Platform to Productionize LLM APIs
Portkey, in simple words, brings the DevOps principle of reliability to the LLM world – it adds production capabilities to your RAG app extremely easily without you having to change anything.
It does that by helping you answer four questions about your app:
- How can I see all my RAG calls, and identify which are failing?
- What is my latency and how can I reduce it?
- How can I stay compliant and keep my LLM calls secure?
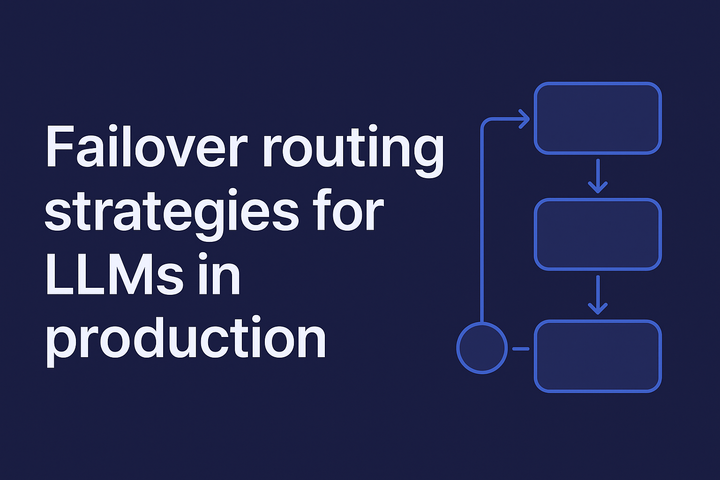
- How can I ensure reliability when any upstream component fails?
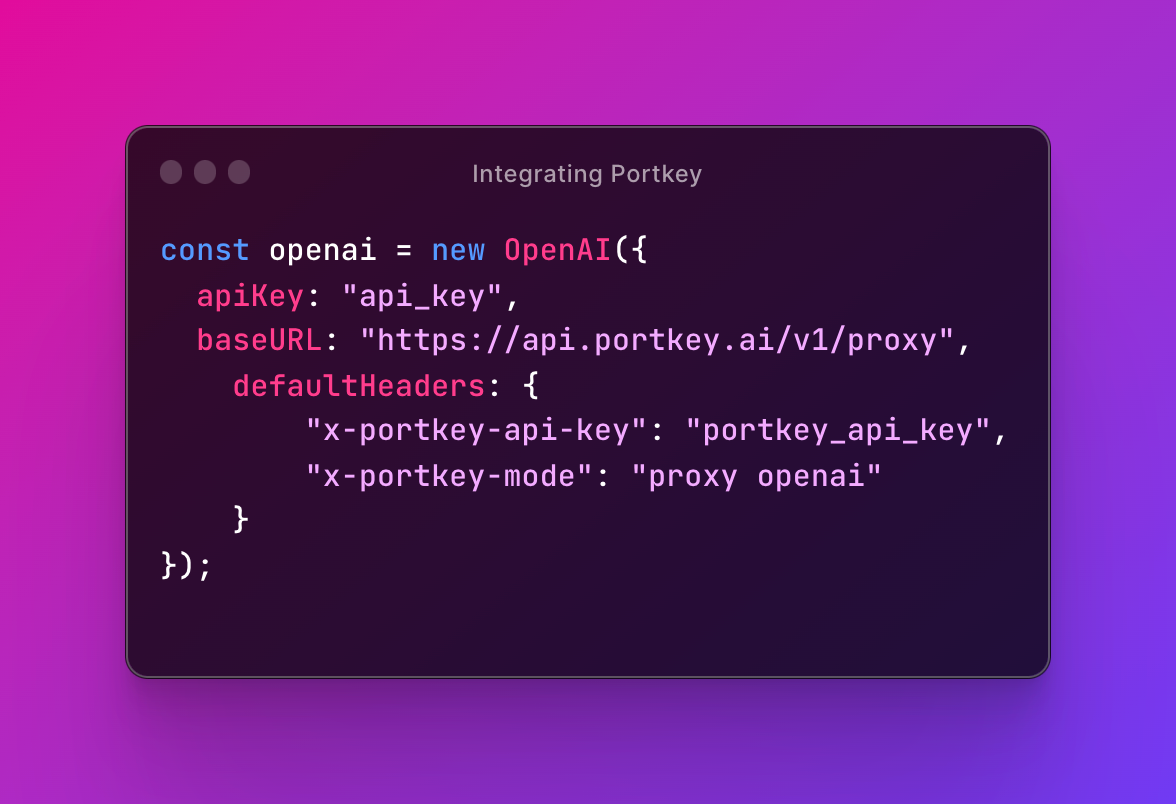
Portkey operates as a gateway between your app and your LLM provider, and makes your workflows production-grade with its observability and reliability layers.
Portkey provides:
Observability Layer
- Logging: Portkey logs all requests by default so you can see the details of a particular call and debug easily.
- Tracing: Trace various prompt chains to a single ID and analyze them better.
- Custom Tags: Add production-critical tags to requests that you can segment and categorize later for deeper insights into how your app is being used.
Reliability Layer
- Automated Fallbacks and Retries: Ensure your application remains functional even if a primary service fails.
- Load Balancing: Efficiently distribute incoming requests among multiple models to reduce latencies and maintain rate-limiting thresholds.
- Semantic Caching: Reduce costs and latency by intelligently caching requests. (20% of requests can become 20x times faster).
All of this, in your existing code, with just one line of change to integrate Portkey.
In the next Portkey X Hasura collaboration, we will take you through the process of actually building a production-grade RAG app and share the trade-offs involved!
Follow us on X to stay updated. 📫