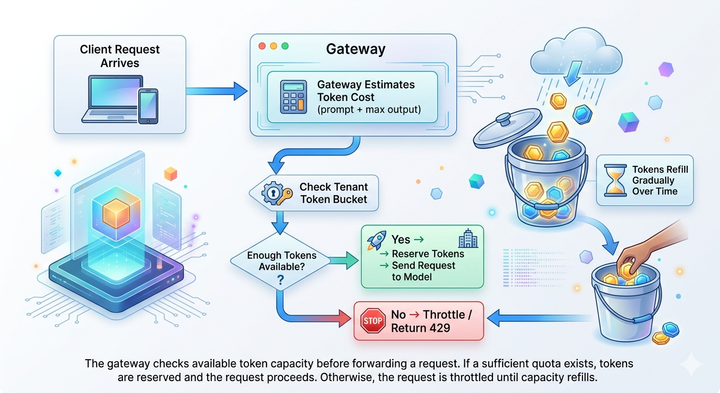
Building the world's fastest AI Gateway - stream transformers
In January of this year, we released unified routes for file uploads and batching inference requests. With these changes, users on Portkey can now:
- Upload a single file for asynchronous batching and use it across different providers without having to transform the file to the model-specific format
- Upload a single file containing data for fine-tuning and use it to fine-tune different models from different providers
Getting into it
All this looks straightforward, but since Portkey's AI gateway is built to be served from edge locations (the compiled binary is ~ 500kb), the memory footprint is expected to remain within bounds.
But file handling on the fly is a tricky thing to solve. Here are a few cases we encountered while initially scoping out the feature
multipart/formdatatoapplication/octet-streamtransforms- OpenAI's files POST endpoint expects the request to have a form-data body, there's the actual file in it, plus fields like
purposewhich are used for validating the file content, but this is not true for other large model provider platforms. While AWS Bedrock/S3 expects a file stream (with content-length known), Anthropic does not store files at all; instead, they accept request bodies < 32MiB for batch requests. - Transforming the batch response on the fly
- For OpenAI, once a batching request is completed, the response can be received as an application/octet-stream response. Compare this with S3, which sends a binary stream, and with Cohere, which only sends the signed URL chunks and expects each chunk to be downloaded manually! This adds additional complexity to the transformation process.
The end users should not be concerned with all this complexity, portkey abstracts away these under the hood and lets the users interact with a consistent API signature
Streaming transformers
At the heart of Portkey is transformations. Portkey not only transforms JSON payloads for inference calls, but also transforms between the following content types for various use cases
{
APPLICATION_JSON: 'application/json',
MULTIPART_FORM_DATA: 'multipart/form-data',
EVENT_STREAM: 'text/event-stream',
AUDIO_MPEG: 'audio/mpeg',
APPLICATION_OCTET_STREAM: 'application/octet-stream',
BINARY_OCTET_STREAM: 'binary/octet-stream',
GENERIC_AUDIO_PATTERN: 'audio',
PLAIN_TEXT: 'text/plain',
HTML: 'text/html',
GENERIC_IMAGE_PATTERN: 'image/',
}
The gateway simultaneously consumes the stream and transforms chunks and uploads to the end provider, all while validating the individual rows in the chunks
Deep dive, unifying routes for AWS Bedrock
1. Upload file
The gateway receives the payload through the /v1/files route
app.post('/v1/files', requestValidator, filesHandler('uploadFile', 'POST'));
We create the necessary amazon v4 signature to handle a multipart file upload where the final upload size is not known, the code handling auth can be found here.
Then to do the actual multipart file upload, we perform the following steps:
- Initiate multi part upload
- Read chunks into memory and transform them
- Upload each part
- Finish the upload and clear resources
2. Create the batching request and fetch the batch completion status
This is pretty straightforward; we just have to transform the application/json payload and hit the bedrock endpoints
3. Get batch output
GET /v1/batch/output is a Portkey-specific unified route that is not available in end providers. We provide this to simplify the process of creating batches and consuming batch outputs
We create a bi-directional stream as we do while uploading files to s3 and downloading, plus transform the file on the fly.
Check out the relevant code here
Additional notes:
- All of the code described above is open source and can be found here. We strive to maintain Portkey as the fastest AI gateway out there
- The enterprise version of the gateway also provides an option for immediate batching, where Portkey handles the batching on your behalf. Everything from rate limits, retries, and error handling is taken on by Portkey, and you'd only need to upload the files containing the row data for inference. For more details, check out the documentation