Buyer’s guide to LLM observability tools 2026
A complete guide to evaluating LLM observability tools for 2026; from critical metrics and integration depth to governance, cost, and the build-vs-buy decision for modern AI teams.
Observability for LLM systems has evolved from a debugging utility to a business function. When AI applications scale from prototypes to production, every model call represents real cost, latency, and reliability risk. Teams now need more than basic logs, they need full visibility into how models perform, drift, and behave in real-world conditions.
But with this shift comes a question every AI platform team faces sooner or later:
Should we build our own observability stack or buy a specialized tool?
The visibility gap and what LLM observability should cover
While the adoption of LLMs has experienced a significant boost, running LLM applications in production has proven to be more challenging compared to traditional ML applications. This difficulty arises from the massive model sizes, intricate architecture, and non-deterministic outputs of LLMs. Furthermore, troubleshooting issues originating in LLM applications is a time-consuming and resource-intensive task due to the black-box nature of their decision-making processes.
Regular observability tools are insufficient for modern LLM apps or agents due to their complex multi-provider and agentic flow, as well as constant hallucinations, compliance gaps, cost spikes, and changing output quality, which makes LLM observability a core business function of AI. Here we are listing down the six core pillars your observability system must be able to do:
- Handle runtime metrics such as latency, success rates, error codes, and costs incurred by token usage.
- Ensure quality by checking accuracy, detecting hallucinations, eval coverage, and grounding.
- Maintain ongoing governance, including logs, access controls, guardrails, PII checks, and audit trails.
- Track how much the provider, model, user, and workspace have spent with built-in budgets and alerts.
- In case of failures, it must monitor slowdowns, retries, failovers, and behavioral changes over time.
- As the AI’s outputs are influenced by prompts, data, and agent actions, they guide the AI's behavior, contextual understanding, and ability to perform tasks. Thus, LLM observability must also trace agents, data sources, and user prompts.
All of these factors make observability an important business function for AI stacks, as it provides a holistic view of IT systems and enables learning about the current state based on the environment and the data it generates.
Enterprises must decide whether to invest time making a custom observability stack or use a third-party tool that already has the necessary features. By examining both options, you can determine which one suits your needs in terms of time, money, and features. In the following sections, we will explore this. Let's get started.
The “Build” path: When teams try to create LLM observability in-house
Building LLM observability in-house enables teams to tailor monitoring to their specific needs using tools like OpenTelemetry for traces and logs, as well as Grafana, ELK, or BI platforms for dashboards.
Building your own LLM observability systems provides your team with strong control over your data and security, keeping all sensitive information within your infrastructure. This is especially important for industries with strict compliance requirements, such as healthcare, finance, or government, where maintaining privacy and meeting regulatory standards are crucial.
This also provides your team with a customised solution, enabling you to tailor features such as security rules, integrations, dashboards, and model tuning to match the exact needs of your internal systems. This flexibility ensures the system grows and adapts as your organization evolves, enabling smoother workflows and a unified internal ecosystem.
Additionally, an in-house solution lets you scale instantly without waiting for vendor approvals or external resource allocation.
The challenges of building an LLM observability In-house
Companies starting with only a few models may consider building an in-house monitoring tool as a cost-effective way to test out the value of their models.
While this approach offers flexibility and full control, it often requires significant development effort, such as logging and tracing schemas, ongoing maintenance of custom SDKs, normalizing metrics across different models, providers, and building pipelines to track lineage, drift, and guardrails.
Even with this, the dashboards require constant monitoring across all AI workflows as the complexity and quantity of models increase, and an in-house monitoring tool may no longer be sufficient with the limited coverage for specific LLM components, such as prompt evals, hallucination tracking, and cost attribution.
Most organizations spend 6–12 months just to create a basic version, and ongoing updates are also necessary to accommodate the evolving models and workloads. Hallucination detection and agent tracing also require enterprise-level AI expertise, making it tedious.
The “Buy” path: What off-the-shelf solutions offer
A ready LLM observability solution provides teams with a turnkey solution to monitor, analyze, and optimize AI models. By eliminating the need for in-house infrastructure, it enables faster deployment, seamless scalability, and comprehensive insights into model performance, reliability, and usage—allowing teams to focus on improving AI outcomes rather than managing tooling with fewer resources and lower cost.
Such platforms work across models and comes with a purpose-built telemetry for LLMs and agents. It offers ready dashboards for latency, cost, drift, and quality, along with built-in eval frameworks for hallucinations, grounding, and other LLM-specific behaviors.
These platforms integrate seamlessly with LLM gateways, routers, and model providers, enabling smarter routing decisions based on real performance data such as costs and governance. This leads to more efficient usage, better quality outputs, and a reliable LLM stack.
It can be set up in days instead of months. It evolves with automatic updates, with new models and capabilities. This requires less ongoing maintenance, versioning, and compatibility checks while you still own the entire system.
What to consider when buying an LLM observability solution
When buying an observability tool, it's important to evaluate how the solution fits your specific environment, whether you need open-source or commercial options, and your organization's future goals.
Key dimensions for evaluation
- Metrics:
- Data types: Does it support the essential pillars of observability (logs, metrics, and traces)?
- Querying & visualization: How easy is it to query data, create meaningful dashboards, and set up alerts effectively?
- Integrations:
- Ecosystem compatibility: Does it offer out-of-the-box integrations for your existing infrastructure, languages, databases, and third-party services?
- Open standards: Does it support open standards like OpenTelemetry for vendor-neutral data collection?
- Scale:
- Performance: Can the system handle your current data volume and projected future growth without performance degradation?
- Data retention: Does it provide flexible data retention policies to meet both compliance requirements and performance needs?
- Governance:
- Data quality & control: Are there mechanisms for tagging, sampling, and controlling the quality and volume of data ingested to avoid "garbage in, garbage out"?
- Access control: Does it offer robust role-based access control (RBAC) to manage who can view, edit, or delete data and configurations?
- Costs:
- Pricing model: Is the pricing predictable (e.g., based on data volume, hosts, or usage), and are there transparent cost-management tools?
- Total cost of ownership (TCO): Beyond the sticker price, consider the operational costs of maintenance, training, and potential overages.
- Privacy and Security:
- Compliance: Does the solution help you meet relevant industry and regulatory compliance standards (e.g., GDPR, HIPAA, SOC 2)?
- Data handling: How are sensitive data and PII handled, masked, or encrypted both in transit and at rest?
- Deployment Options:
- Flexibility: Does it offer options for SaaS, self-hosted, or hybrid deployment models to match your operational preferences and security requirements?
- Cloud compatibility: If cloud-native, is it compatible with your specific cloud provider (e.g., AWS, Azure, GCP)?
Platforms like Portkey are adaptable and can support your future technology stack. They also provide flexible deployments, open standards support, and enterprise-grade security, making it a reliable choice for scaling AI applications.
Build or buy an LLM observability platform
Why Portkey is a strong option for enterprises looking for LLM observability
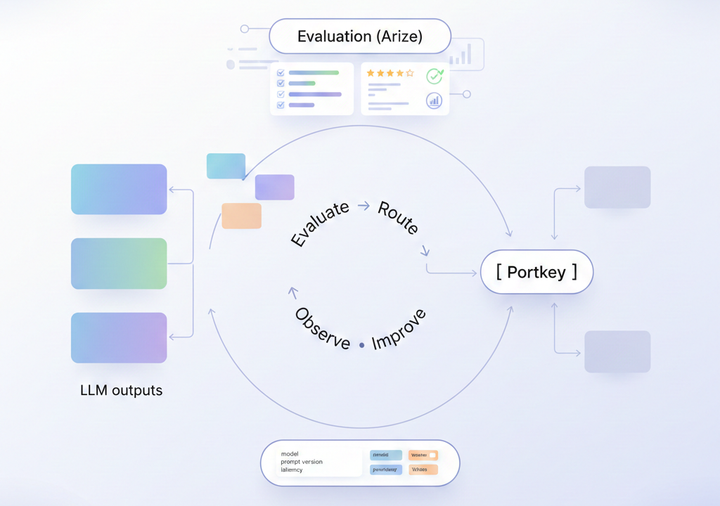
Recognised as Cool Vendor in LLM Observability, Portkey provides visibility above the AI gateway.
Portkey's Observability exists for teams that want enterprise-grade observability without taking on the engineering overhead of building and scaling it internally.
It provides:
- Unified tracing across models, providers, and agents
- Structured logs that capture prompts, completions, token counts, cost, latency, and guardrail outcomes
- Built-in quality, safety, and reliability signals
- Team and department-level governance with budgets, rate limits, RBAC
Teams using Portkey don’t have to stitch together custom pipelines, dashboards, and schemas or maintain compatibility across changing model APIs. Instead, they start with a production-ready observability layer that evolves with the ecosystem.

If you’re exploring LLM observability, Portkey can help you get there faster, with less operational overhead.
Want to see how this works in practice? Book a demo with our team.