

Claude Sonnet 4.5 vs GPT-5: performance, efficiency, and pricing compared.
A head-to-head comparison of Claude Sonnet 4.5 and GPT-5, covering coding, reasoning, math, tool use, cost, and ecosystem integrations , with insights on where each model is best suited for enterprise use.
Claude Sonnet 4.5 and GPT-5 are the newest flagship models from Anthropic and OpenAI. Both were released in 2025 with a focus on stronger reasoning, coding ability, and agentic workflows.
Claude Sonnet 4.5 offers long-context handling, advanced coding skills, and memory features while keeping the same pricing as its predecessor. GPT-5 extends OpenAI’s suite with improved multi-step reasoning, reduced hallucinations, and deeper integration with tools and APIs.
This comparison looks at performance, efficiency, integrations, and limitations to help teams understand where each model is best suited.
To compare new models with prompts, use Portkey's AI gateway and compare LLMs across providers.
Check this out!
Quick overview of both models
Claude Sonnet 4.5
- The latest upgrade in Anthropic’s Claude line, building on Sonnet 4 and Opus models.
- Can maintain autonomous operation over extended tasks — Anthropic claims over 30 hours of sustained work.
- New API enhancements include:
- Smart context window management, which avoids abrupt cutoffs by generating up to the token limit and indicating why it stopped.
- Automatic tool-history pruning, to prevent tool calls from eating up token budgets unnecessarily.
- Cross-conversation memory (via a local memory file) so the model can remember persistent facts across sessions.
- Communication style is refined to be more direct and concise; summaries after tool calls are optional to keep the conversational flow smoother.
- It retains the same pricing as Sonnet 4 (input and output token rates unchanged) even with these upgrades.
- Through Amazon Bedrock / Vertex AI, Sonnet 4.5 supports 1 million token context for large-scale jobs.
GPT-5
- GPT-5 is OpenAI’s newest flagship, oriented toward coding, tool orchestration, and agentic workflows.
- The model supports more advanced tool usage:
- It can chain dozens of tool calls in sequence or in parallel, handling errors and orchestration more robustly.
- It offers a verbosity parameter and “minimal reasoning” mode to better control output style and depth.
- In the API, GPT-5 is made available in variants (regular, mini, nano), each with adjustable reasoning levels (minimal, low, medium, high) to balance speed vs depth.
- Token limits: input up to ~272,000 tokens, output including internal reasoning up to ~128,000 tokens.
- GPT-5’s system architecture is unified: a fast “default” reasoning path, a deeper reasoning path, and a router to decide dynamically which mode to use.
Use these latest models in LibreChat via Portkey and learn how teams are running LibreChat securely with RBAC, budgets, rate limits, and connecting to 1,600+ LLMs all without changing their setup.
To join, register here →
Model performance
Software engineering
Coding
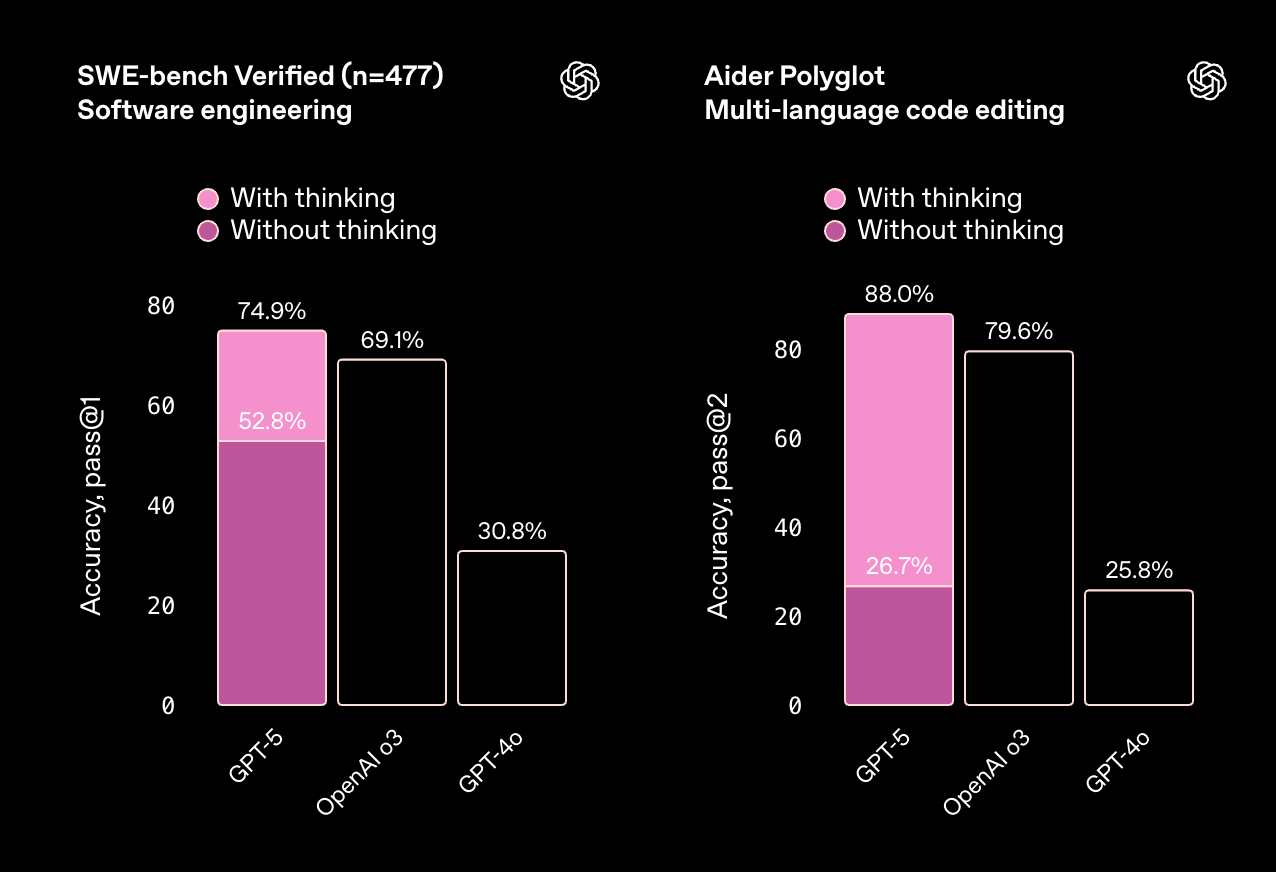
The coding benchmarks highlight two distinct strengths. Claude Sonnet 4.5 delivers steady, high accuracy across tasks without requiring special modes or tuning, which makes it reliable for production workflows. GPT-5, on the other hand, shows a bigger jump when its “thinking” mode is enabled — meaning it can reach very strong results, but performance depends more on how you configure and run it.
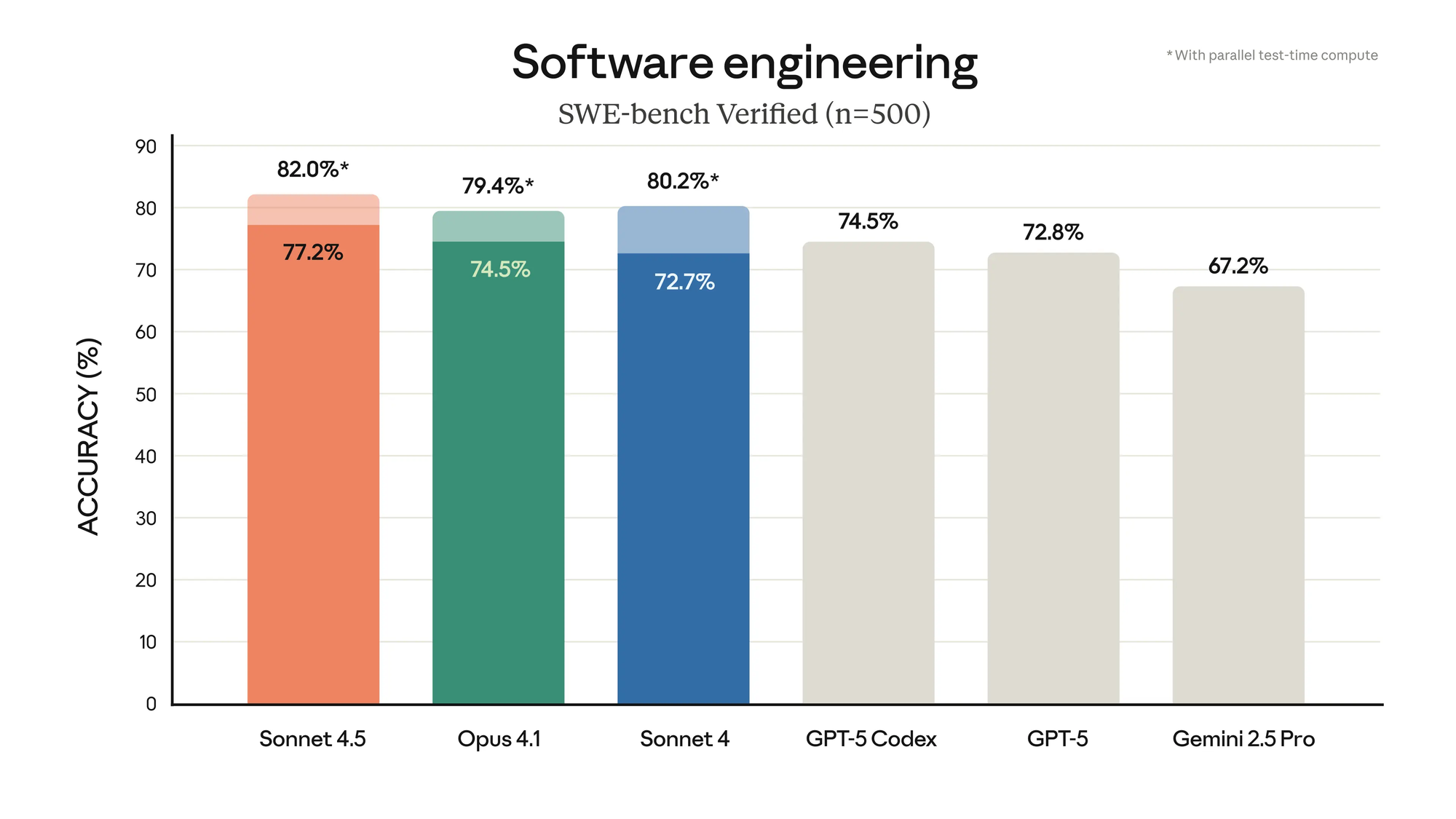
Another clear difference is consistency. Sonnet 4.5’s performance doesn’t vary much between test conditions, while GPT-5 ranges widely between standard and reasoning-enabled runs. For teams prioritizing predictability, that stability matters. For those willing to tradeoff speed or cost for deeper reasoning, GPT-5’s adaptive path can pay off, especially in multi-language code editing where it takes a clear lead.
Agentic coding and tool use
- Claude Sonnet 4.5 demonstrates more stability across agentic workloads. On benchmarks like Terminal-Bench and t2-bench, it consistently executes tool calls and command-line interactions without major drop-offs. This makes it well-suited for workflows where reliability and error-resilience matter more than peak reasoning depth.

- GPT-5 shines when extended reasoning is enabled. In multi-turn instruction following and browsing tasks, its “thinking” mode pushes accuracy significantly higher, though the baseline without it can lag. This suggests GPT-5 is more powerful when you configure it for deeper reasoning, but less predictable in lightweight runs.
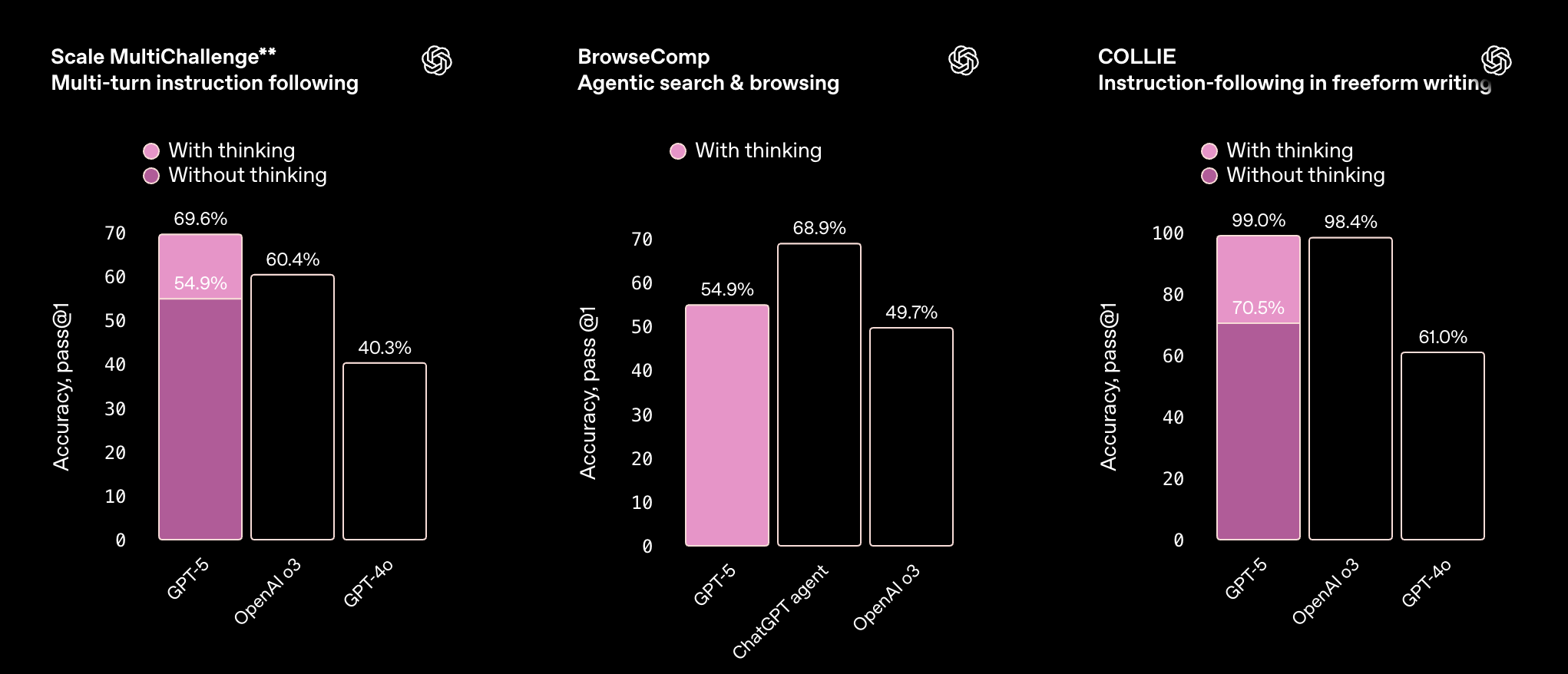
In practical terms, Sonnet 4.5 behaves like a “safe default” for long-running agents and external toolchains, while GPT-5 is better optimized for situations where reasoning complexity fluctuates and developers want fine-grained control over the trade-off between speed and accuracy.
Reasoning
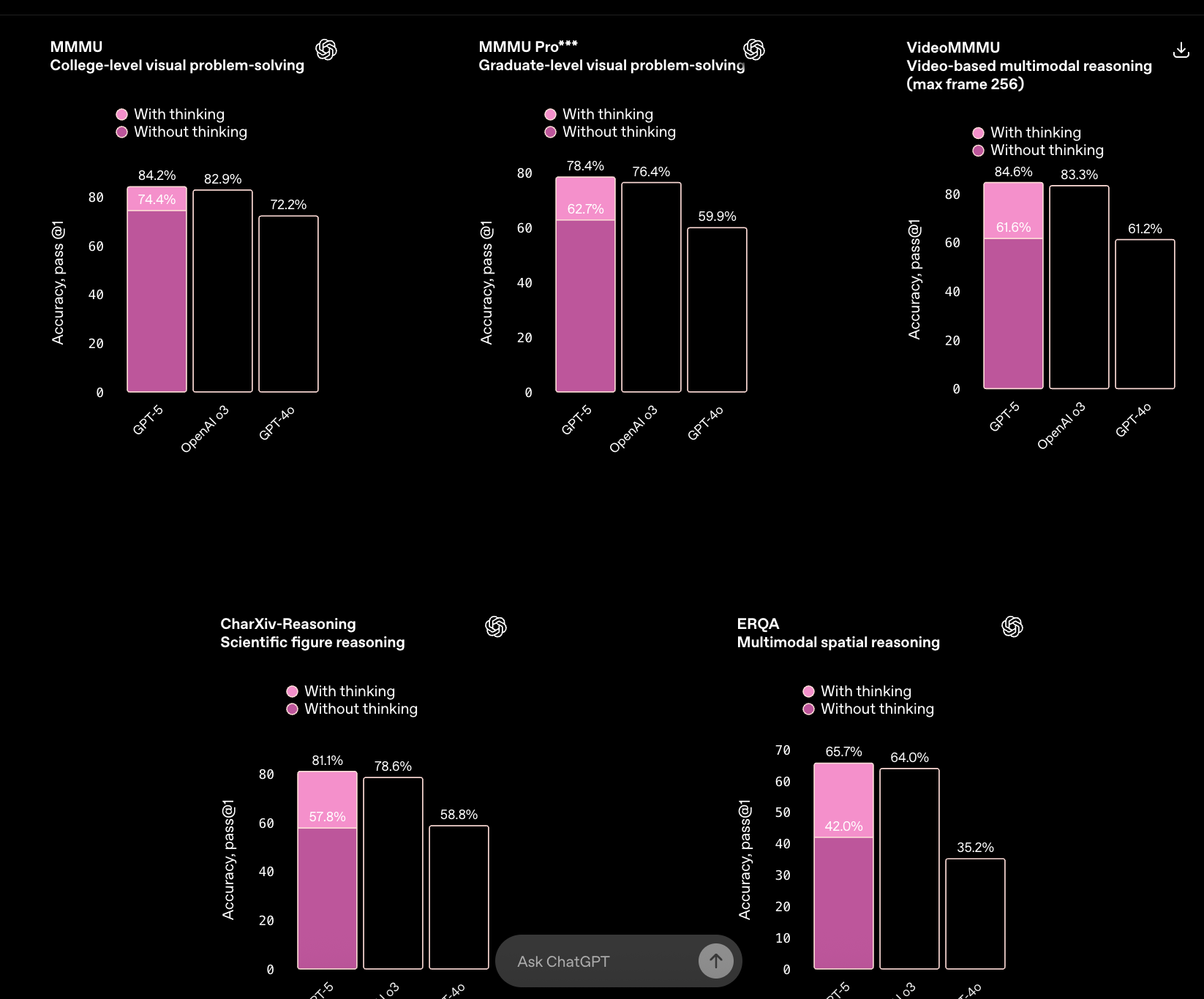
On reasoning-heavy benchmarks, both models push well beyond their predecessors but in slightly different ways.
- GPT-5 benefits heavily from its “thinking” mode, which boosts results across scientific reasoning, multimodal tasks, and spatial problems. This allows it to handle complex, multi-step chains of logic more effectively than when running in standard mode. The tradeoff: without reasoning enabled, accuracy can fall off sharply.
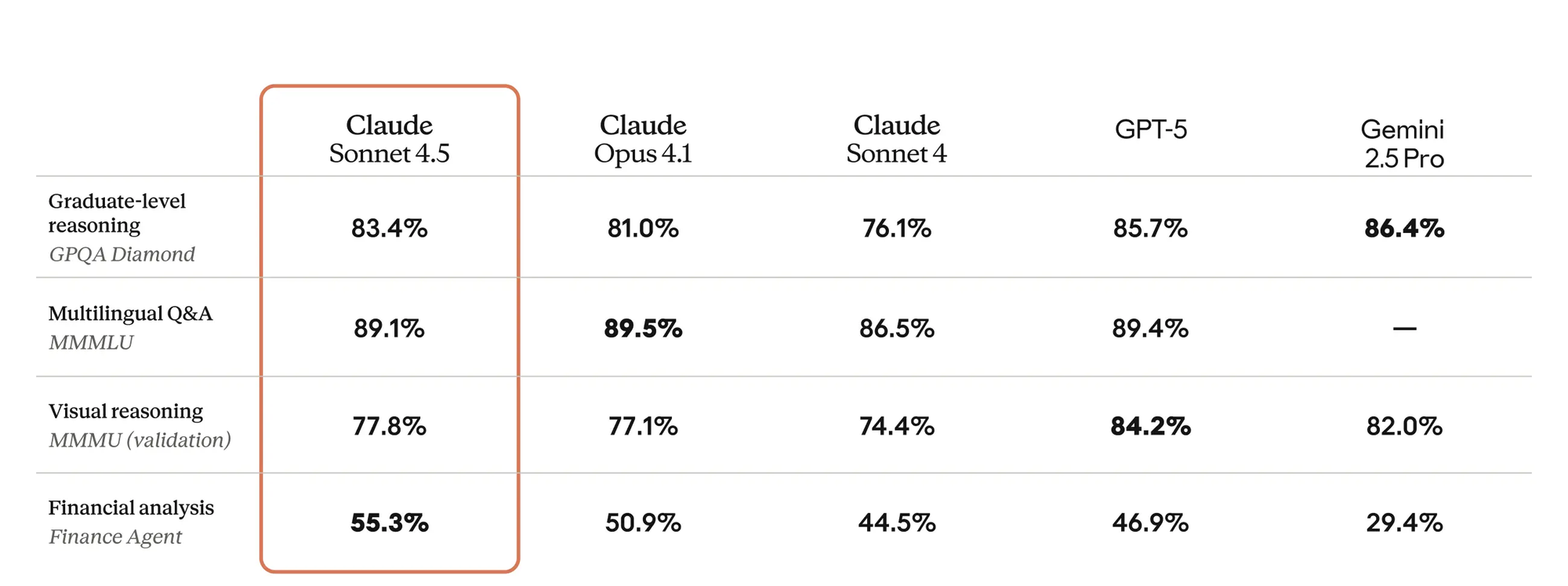
- Claude Sonnet 4.5 shows steady strength in graduate-level reasoning and multilingual Q&A. It doesn’t require special modes to maintain accuracy, which makes it reliable in production settings where predictability matters. Its edge is particularly visible in tasks like financial analysis, where stability and structured reasoning outweigh raw creativity.
Claude Sonnet 4.5 is the model you can trust for consistently high reasoning output in text-heavy enterprise workflows, while GPT-5 is the one you turn to when multimodal reasoning and deep scientific logic are critical, provided you configure it correctly.
Math
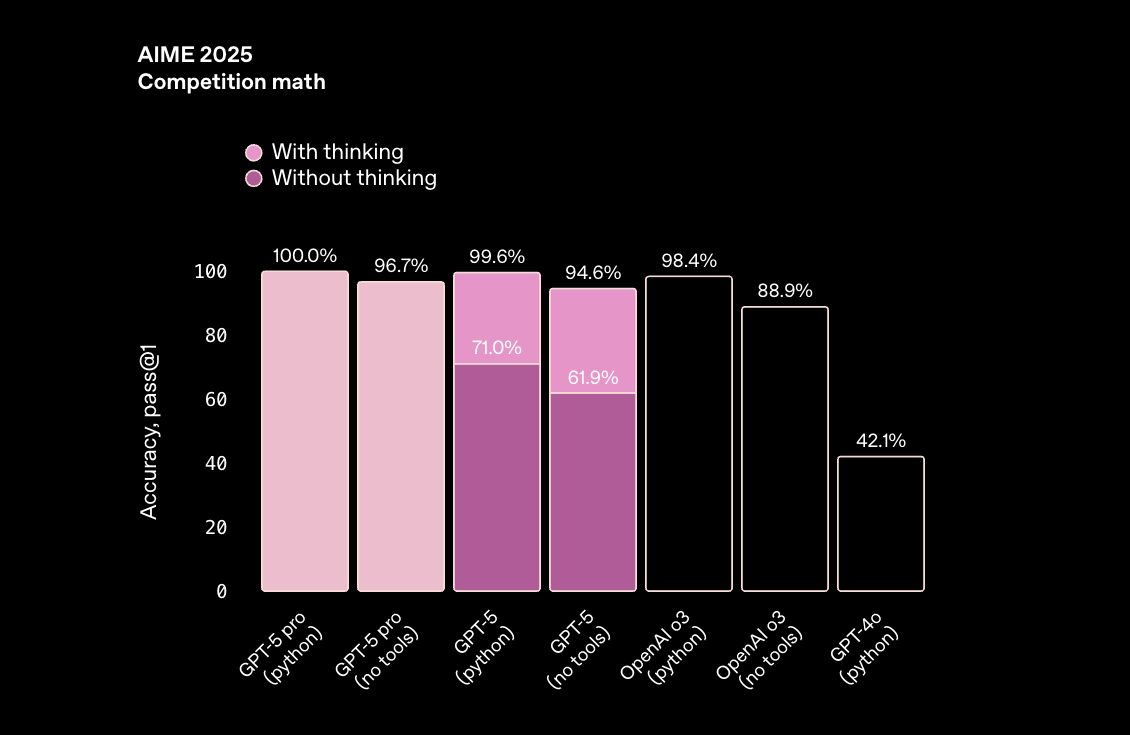
- Claude Sonnet 4.5 is remarkably consistent. It reaches top performance whether solving problems directly or when paired with Python tools, showing that its reasoning pipeline is strong enough without heavy reliance on tool access. For enterprise workflows where tool execution isn’t always available or desirable, this consistency is valuable.

- GPT-5 also achieves near-perfect math accuracy, but only when its reasoning and tool integrations are fully enabled. Without them, accuracy drops more sharply, which highlights how much the model leans on its adaptive reasoning path to achieve top results.
Cost & Efficiency
Pricing
Claude Sonnet 4.5
- $3 per million input tokens, $15 per million output tokens.
- For very large inputs (>200K tokens), rates rise to $6 per million input and $22.5 per million output.
- Anthropic also supports caching and batch discounts that can significantly reduce cost in repeated or bulk scenarios.
GPT-5
- $1.25 per million input tokens, $10 per million output tokens.
- Multiple variants are available (e.g. GPT-5 mini, GPT-5 nano) with even lower per-token rates, but the base GPT-5 is the closest comparison to Sonnet 4.5.
- OpenAI offers caching discounts as well, which cut input costs for repeated tokens.
Takeaway: GPT-5 is cheaper on both input and output tokens in raw pricing. Sonnet 4.5 can close the gap in some workloads via caching/batching, but out-of-the-box GPT-5 has the cost advantage.
Efficiency
- Context window: GPT-5 supports up to ~400K tokens (272K input + 128K output), while Claude Sonnet 4.5 is optimized for ~200K, with memory features to extend continuity across sessions.
- Compute scaling: GPT-5 dynamically adjusts reasoning depth — lightweight prompts run on a faster, cheaper path; complex prompts invoke deeper reasoning. This adaptive approach makes it more efficient in mixed workloads.
- Latency: Claude Sonnet 4.5 is tuned for stable, predictable response times. GPT-5 may introduce variable latency depending on reasoning depth, but offers more levers (reasoning effort, verbosity) to trade accuracy for speed when needed.
Example cost comparison
| Scenario | Claude Sonnet 4.5 ($) | GPT-5 ($) |
|---|---|---|
| Short query (1k input, 500 output) | 0.0105 | 0.0063 |
| Medium task (5k input, 2k output) | 0.0450 | 0.0263 |
| Large analysis (50k input, 20k output) | 0.4500 | 0.2625 |
| Very large context (200k input, 50k output) | 1.3500 | 0.7500 |
Insight: GPT-5 is consistently cheaper across scenarios, especially as input size grows. Claude Sonnet 4.5’s predictable latency and reliability may offset this in production settings, but on pure token economics, GPT-5 has the edge.
What should you pick?
Claude Sonnet 4.5 and GPT-5 represent the best of what Anthropic and OpenAI are building — but they’re optimized for different priorities. Claude is tuned for predictability, stability, and integration readiness, making it easier to adopt in production without extensive configuration. GPT-5 delivers more raw flexibility and power, with deeper reasoning, larger context windows, and fine-grained controls, though at the cost of variability in speed, accuracy, and setup overhead.
For most enterprises, the answer is not about picking one. The strongest strategies combine models, using Claude where consistency and safety matter most, and GPT-5 where adaptive reasoning and multimodal depth bring clear advantages. In practice, teams increasingly pursue a multi-provider approach, ensuring they can balance cost, performance, and reliability without being locked to a single vendor.
👉 If you’re evaluating how to run both models side by side in production, consider testing them through a unified gateway to compare performance, cost, and reliability under your own workloads.


