

DSPy in Production

This is a guest post by Ganaraj, based on the talk he gave at the LLMs in Prod Meetup in Bangalore.
AI has fundamentally changed the way we build apps. I transitioned from being a coder to a creative prompter. This shift from coding to creative prompting might seem like a dream come true. However, the nerd inside me was unhappy.
Enter DSPy
DSPy changes this dynamic entirely. Instead of obsessing over prompt crafting, it allows me to focus on what I do best: programming. I'm moving from writing prompts to actually programming AI pipelines.

What's DSPy All About?
At its core, DSPy is a framework for optimizing how we work with LLMs. Instead of manually crafting the perfect prompt, DSPy lets us focus on building AI pipelines:
- You define the flow of your AI program.
- You set up metrics to measure what "good output" looks like for your task.
- DSPy handles the optimization of prompts and weights automatically.
It separates the flow of your program (modules) from the parameter using optimizer (LLM-driven algorithms). Optimizer can tune the prompts and the weights of your LLM calls, based on a metric you want to maximize.
"Don't bother figuring out what special magic combination of words will give you the best performance for your task. Just develop a scoring metric then let the model optimize itself." - Battle at IEEE
Why This Matters
DSPy stands out in three crucial areas:
a) LLM-agnostic: You can switch between models without changing the entire system. Moving from GPT-4 to Mistral-7B doesn't mean rewriting my app from scratch.
b) Complexity management: It breaks down tasks into manageable chunks, each with its own optimization.
c) Automated optimization: No more manual prompt tweaking
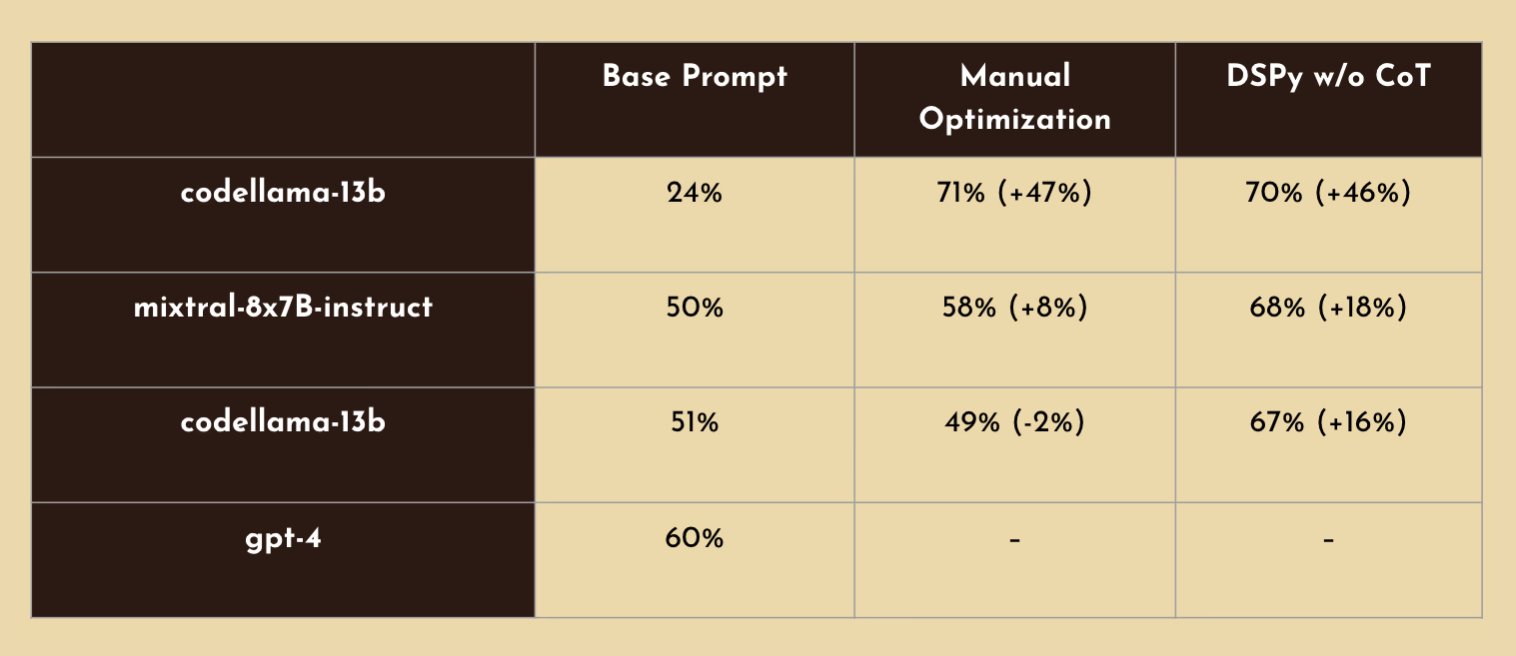
"DSPy allowed us to beat GPT-4 performance on this task of extracting data from messy tables, at 10x lower cost per table and 10x lower manual effort" - Gradient AI
DSPy in Action: The Zoro UK Case Study
I work as a Lead Architect at Zoro UK, where we've scaled DSPy to production. We use DSPy to solve complex challenges in e-commerce - specifically, normalizing product attributes across millions of items from hundreds of suppliers.
One of our biggest problems is that we have more than 300 plus suppliers, and they all supply similar kinds of stuff, For example, a simple attribute like thread length can be represented in various ways by different suppliers - some might use '25.4 mm', others '25.4 M', and some might use inches.
To address this challenge, we (the engineering team) orchestrated a system using DSPy:
LLM Sorter Service
At the heart of the system, this service leveraged DSPy's capabilities. It implemented a tiered approach:-
- A smaller model (e.g., Mistral) for deciding if a set of attribute values needs to be sorted by LLM. In simple cases, we can just go with alpha-numeric sort. So LLM doesn't need to be involved, thereby saving cost.
- A more powerful model (e.g., GPT-4) for complex, nuanced attribute value sorting.
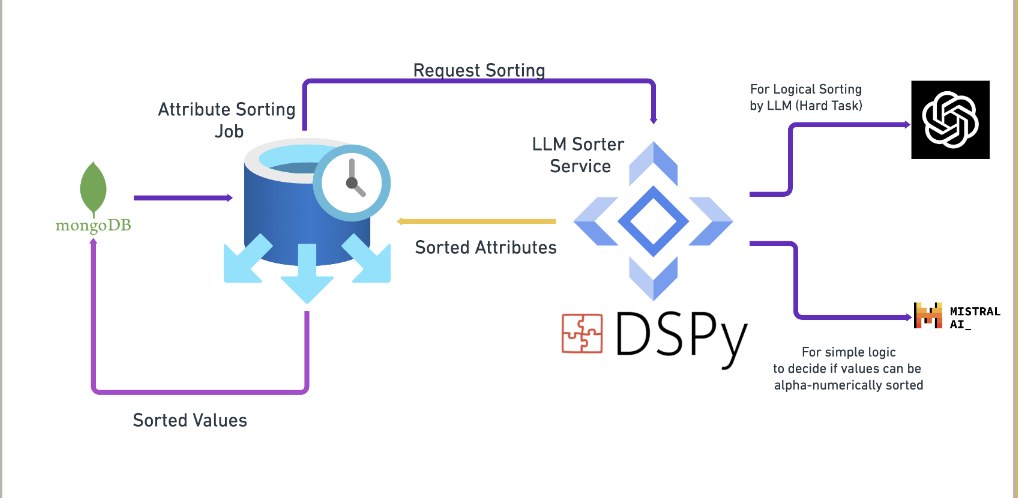
Workflow:
- The Attribute Sorting Job extracts raw attribute data from MongoDB.
- The LLM Sorter Service processes these attributes using the appropriate model based on task complexity.
- DSPy's optimization features continuously refine the processing based on defined metrics.
- Processed and standardized attributes are then fed back into MongoDB.
We first started with one model, and then for some use cases, that was not enough. So we just switched it over to OpenAI GPT-4, and it started working as well!
Hear more from my recent talk at Portkey's LLMs in Prod event in Bengaluru:
- Slides: https://ggl.link/dspy-in-prod
- Smrthi project with translations produced using DSPy: https://www.smrthi.com/
- Awesome DSPy repo: https://github.com/ganarajpr/awesome-dspy
Metrics in DSPy
One of the most intriguing aspects of DSPy is its approach to metrics. Defining the right metric is about more than just accuracy; it's about encapsulating the nuanced goals of your AI system into a quantifiable measure. This process forces clarity of thought that often leads to better system design overall.
Metrics can range from simple measures like accuracy, exact match, or F1 score to more sophisticated approaches such as cosine similarity or deep eval, depending on the complexity of the task.
FAQs with DSPy
1) How does DSPy enhance scalability in production?
DSPy's optimizers automatically adapt your pipeline to handle increased data volume and complexity, reducing the need for manual prompt engineering as your system scales.
2) What's DSPy's approach to model portability?
DSPy allows seamless switching between models (e.g., GPT-4 to Llama 3.1) without rewriting your core logic, crucial for adapting to changing production requirements or cost structures.
3) How does DSPy help manage costs in large-scale deployments?
By optimizing prompts and potentially using smaller models more effectively, DSPy can significantly reduce API calls and associated costs in high-volume production environments.
4) How does DSPy handle performance monitoring and observability in live systems?
You can use AI Gateways like Portkey to have an observability layer on top of DSPy.
Check out the Portkey x DSPy cookbook for more . Link to docs
5. What's the typical compile-time overhead in a production setting?
Compile time varies based on complexity. For reference, a moderately complex program might take anywhere from 5mins-1hr depending on the number of examples and iterations used.
What’s next?
For those working on AI systems, especially in production environments, it's time to look at DSPy. The challenges it addresses - scalability, consistency, and adaptability - are only going to become more pressing as AI continues to permeate every aspect of our digital infrastructure. The future of programming isn't about arguing with AI—it's about orchestrating it, and with tools like DSPy, we're well-equipped to lead this transformation.
Join the community of AI builders at Portkey's Dsicord

