

What Makes Enterprise LLMs Different from General-Purpose AI Tools
What makes enterprise LLMs different from consumer AI? Explore architecture choices, RAG pipelines, security guardrails, and cost control at scale.
An enterprise LLM is a large language model engineered for real business operations: it connects to private company data, runs inside security and regulatory constraints, and integrates with internal systems like CRMs, ticketing, data warehouses, and workflow engines.
That’s fundamentally different from consumer AI, which is optimized for general-purpose assistance in largely public contexts – often sending prompts to external services without your organization’s permissions model, audit needs, or system-to-system responsibilities.
🧠 GenAI spending reached $37B in 2025, which is a 3.2x increase from $11.5B in 2024. This clearly proves that enterprise adoption has moved from experimentation to execution.
Today’s challenge isn’t whether to use LLMs, but how to deploy, monitor, and control them reliably – especially as usage evolves from simple chatbots into agentic workflows that autonomously execute multi-step business processes.
That’s exactly what this post will cover. You’ll learn how modern enterprises ground models with RAG, choose the right deployment architecture, implement security guardrails, and monitor performance and cost in production.
How RAG connects LLMs to your organization’s knowledge
Retrieval-Augmented Generation (RAG) connects an enterprise LLM to your internal knowledge at runtime. Instead of relying solely on what the model learned during pretraining, RAG retrieves relevant documents from company sources (such as wikis, policies, tickets, and databases) at query time and injects them into the prompt. The result is responses grounded in current, proprietary data rather than static training corpora.
For enterprises, this is critical. RAG reduces hallucinations by anchoring outputs in authoritative sources, keeps answers up to date without costly retraining cycles, and allows flexible integration across multiple knowledge systems. As documentation changes, the model improves instantly without requiring parameter updates.
Fine-tuning still has value for encoding specialized terminology, tone, or domain nuance. But most organizations prefer RAG for its lower operational overhead and adaptability.
In production, observability becomes essential. When outputs degrade, teams must know whether retrieval failed, context was ignored, or hallucination occurred despite strong grounding.
Deployment models for enterprise LLM infrastructure
Enterprises typically choose between three core deployment approaches, each with distinct trade-offs around speed, cost, and control.
Popular LLMs
LLM APIs from providers like OpenAI, Anthropic, and Google offer the fastest path to production. Teams gain instant access to frontier models with minimal infrastructure overhead, no GPU management, and continuous model improvements.
The downside is ongoing token-based costs and the reality that data flows outside organizational boundaries, often requiring careful legal, compliance, and security review.
Self-hosted open-weight models
Self-hosted open-weight models like Llama provide full data sovereignty, predictable infrastructure costs, and deeper customization. But they demand significant upfront GPU investment, MLOps expertise, scaling infrastructure, and ongoing performance tuning.
For many organizations, the operational complexity outweighs the cost benefits, especially as model capabilities evolve rapidly.
Hybrid
Most large enterprises land on hybrid, using commercial APIs for general reasoning and high-quality language tasks, combined with self-hosted or private models for sensitive workflows, regulated data, or latency-critical use cases.
💭 Strategically, the industry has shifted hard toward buying rather than building. According to Menlo Ventures, 76% of AI use cases are now purchased instead of developed in-house, up from 47% just a year earlier. At the same time, there’s no “one-model-fits-all” winner. Portkey’s analysis of 2 trillion tokens shows multi-provider adoption surged from 23% to 40% in just 10 months, reinforcing that production teams are no longer relying on a single model vendor.
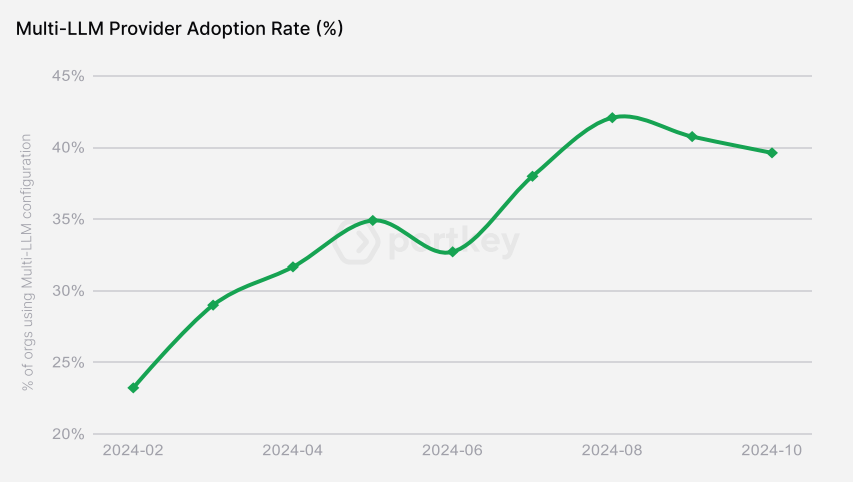
A graph from Portkey’s analysis showing rapid growth in multi-model usage in production environments.
This multi-model reality introduces operational complexity because every provider has different APIs, rate limits, performance characteristics, pricing structures, and failure behaviors. Without abstraction, teams end up hardcoding provider logic into applications, making reliability, optimization, and vendor switching painful.
That’s why modern enterprise stacks increasingly rely on gateway such as Portkey’s AI Gateway.
The Gateway normalizes access across 1600+ models, enables routing based on cost or latency, and provides failover when providers degrade, while centralizing governance and monitoring.
Security controls and guardrails in production
For most enterprises, security remains the primary barrier between successful pilots and full-scale LLM deployment. When models interact with proprietary data, trigger business workflows, or generate customer-facing outputs, failure modes move from “incorrect answer” to real financial, legal, and reputational risk. That’s why enterprise AI stacks rely on guardrails:
- At the input level, guardrails inspect and filter prompts before they reach the model, blocking prompt injection attempts, detecting and redacting Personally Identifiable Information (PII), and preventing sensitive data from being exposed downstream.
- At the output level, responses are validated before delivery, with content filtering for harmful or off-policy outputs and strict format enforcement using JSON schemas or RegEx patterns to ensure machine-readable reliability.
- At the workflow level, systems monitor conversation flows over time to detect abuse patterns, data leakage risks, or policy drift across multi-step workflows.
Enterprises also need to implement concrete security controls like the following to support compliance:
- Zero-retention policies to ensure data isn’t stored after processing.
- Dynamic data masking within RAG pipelines to protect sensitive fields while preserving context for reasoning.
- Encryption in transit and at rest to secure every hop across APIs, vector databases, and internal services.
In regulated industries, automation alone isn’t enough. High-stakes decisions in finance, healthcare, and legal workflows require human-in-the-loop controls, with confidence scoring or risk thresholds that determine when an LLM can act autonomously and when outputs must be escalated for review and approval.
Platforms like Portkey operationalize this with 60+ real-time guardrail checks, including PII redaction, prompt-injection defense, and content filtering applied consistently across all teams, models, and environments, with full audit logging for governance and compliance.
Monitoring LLM behavior and controlling costs
Monitoring LLMs in production looks fundamentally different from traditional application performance monitoring. Models are probabilistic and non-deterministic, which means that the same prompt can produce different outputs, and performance can drift quietly over time without triggering conventional error alerts.
LLM observability
Effective LLM observability starts with foundational metrics like latency, error rates by provider, and token usage per request. But raw performance data isn’t enough. Teams also need to track output quality signals – relevance, correctness, and groundedness – to understand whether the model is actually using retrieved knowledge and producing business-acceptable results.
This becomes especially critical in RAG-based systems. When answers go wrong, tracing reveals the real failure point: did retrieval surface the wrong documents, did the model ignore high-quality context, or did it hallucinate despite strong grounding? Without this visibility, teams can’t improve accuracy or justify scaling usage.
Cost optimization
Cost optimization builds directly on this observability layer. With performance and quality data across models, enterprises can implement intelligent routing, sending simple queries to lower-cost models while reserving frontier models for complex reasoning.
Semantic caching further cuts spend by eliminating repeated calls for similar requests across high-volume workflows.
Governance
Governance completes the loop. Budget limits, usage attribution by team or application, and real-time spend tracking prevent uncontrolled growth.
🌟 These strategies reinforce each other. For instance, one high-scale platform reduced costs by over $500K through optimized routing and caching using Portkey, while automated fallback logic recovered nearly 500,000 failed requests. With Portkey, this platform turned LLM experimentation into dependable, cost-efficient infrastructure.
Evaluating your enterprise LLM architecture
Enterprise LLM success is determined by how well your architecture aligns with risk, scale, and long-term flexibility. The strongest teams build for provider independence from day one, using unified APIs and gateway layers that let them adopt better models, optimize costs, and scale without constant replatforming. That adaptability is quickly becoming a competitive advantage.
This is where Portkey fits in – an open-source, enterprise-grade control plane for deploying, securing, monitoring, and optimizing LLMs across any provider or model.
Stop duct-taping LLM integrations and build a production-ready AI stack with Portkey's enterprise platform today so you can ship faster, safer, and at a fraction of the cost!
Ship Faster with Portkey
Everything you need to build, deploy, and scale AI Agents
FAQs on enterprise LLM implementation
What steps are involved in building an enterprise-grade LLM system?
Most successful teams follow a structured progression:
- Define a clear business use case and success metrics.
- Select a deployment model based on data sensitivity and compliance needs.
- Implement RAG for knowledge grounding (or fine-tuning for specialized language or tone).
- Configure security guardrails to control risk and establish monitoring for quality, reliability, and cost.
In practice, the majority of enterprises begin with commercial APIs paired with RAG, rather than training or hosting models from scratch, to reach production faster with lower operational burden.
What’s driving interest in Small Language Models (SLMs)?
SLMs are emerging as a powerful complement to large frontier models. They require far less compute, deliver faster inference, and are easier to audit and secure for specific tasks.
For narrowly scoped workflows (such as classification, extraction, routing, or compliance checks), smaller task-optimized models can outperform larger general-purpose LLMs while dramatically reducing cost and latency.
Which providers dominate enterprise LLM usage today?
Enterprise adoption has consolidated around a few major platforms. According to Menlo Ventures, Anthropic leads with roughly 40% market share, followed by OpenAI at 27% and Google at 21% – together accounting for nearly 88% of enterprise LLM API usage. This concentration reinforces the need for multi-provider strategies and flexible infrastructure.
What’s stopping many LLM projects from reaching production?
The biggest reasons LLM initiatives don't reach production are security and risk concerns. Other common challenges include unclear ROI measurement, organizational readiness gaps, and integration complexity.
When these issues are solved, returns are substantial – Typedef AI reports an average ROI of 3.7x, with top performers exceeding 10x.
How do agentic systems differ from traditional LLM apps?
Agentic architectures allow models to plan, decide, and execute multi-step workflows across systems, triggering APIs, querying databases, and taking actions autonomously.
What are high-impact enterprise use cases today?
The highest returns are coming from workflows where LLMs reduce manual review and decision latency.
In finance, teams use enterprise LLMs for continuous compliance checks, fraud pattern detection, large-scale contract analysis, and automating high-volume customer support.
In HR, models streamline operations by screening candidates, guiding new hires through onboarding, answering policy questions, and clearly explaining benefits, improving both efficiency and employee experience.

