
GPT 5 vs Claude 4
Compare GPT-5 and Claude 4 on benchmarks, safety, and enterprise use. See where each excels and how Portkey helps teams use both seamlessly.
When it comes to frontier AI models, two names dominate the conversation today: GPT-5 from OpenAI and Claude 4 from Anthropic. Both represent significant leaps in capability, reasoning, and safety but with very different philosophies guiding their design.
For teams evaluating where to invest, it isn’t enough to rely on hype. Benchmarks, real-world prompts, and enterprise considerations reveal how these models compare in practice. In this blog, we’ll look at:
- How GPT-5 and Claude 4 perform on standard benchmarks like MMLU, GPQA, and HumanEval.
- Side-by-side examples of their outputs on reasoning, summarization, and creative prompts using Portkey's Prompt Playground.
- Differences in safety, developer experience, and enterprise readiness.
- A practical conclusion on how organizations can use both effectively.
To join, register here: https://luma.com/z84zjko5
Background on the models
GPT-5
OpenAI’s GPT-5 builds on the GPT-4 family with major advances in reasoning, efficiency, and multimodality. It powers the latest versions of ChatGPT and is available via the OpenAI API and through Azure and other providers. GPT-5 emphasizes versatility, excelling across creative, analytical, and technical tasks and is deeply embedded in the broader OpenAI ecosystem of tools, plugins, and enterprise offerings.
Claude 4
Anthropic’s Claude 4, on the other hand, reflects the company’s alignment-first approach. Claude 4 is designed to be more steerable and safety-conscious, while also offering extremely long context windows. Beyond its API, Claude is tightly integrated into Claude Desktop, giving developers and enterprises a hybrid app + API workflow that GPT-5 doesn’t currently mirror.
Why compare them
While both models are available via direct APIs, pricing, latency, and integration pathways differ. Enterprises often end up managing separate accounts, billing systems, and authentication mechanisms across providers — challenges that compound when teams want to use both GPT-5 and Claude 4 side by side.
This is where an AI gateway like Portkey helps reduce friction: a single control plane for provisioning, routing, and governing multiple frontier models.
Capabilities and performance
When comparing GPT-5 and Claude 4, benchmarks highlight clear differences in reasoning strength, multimodal depth, and safety alignment.
1. Reasoning and math
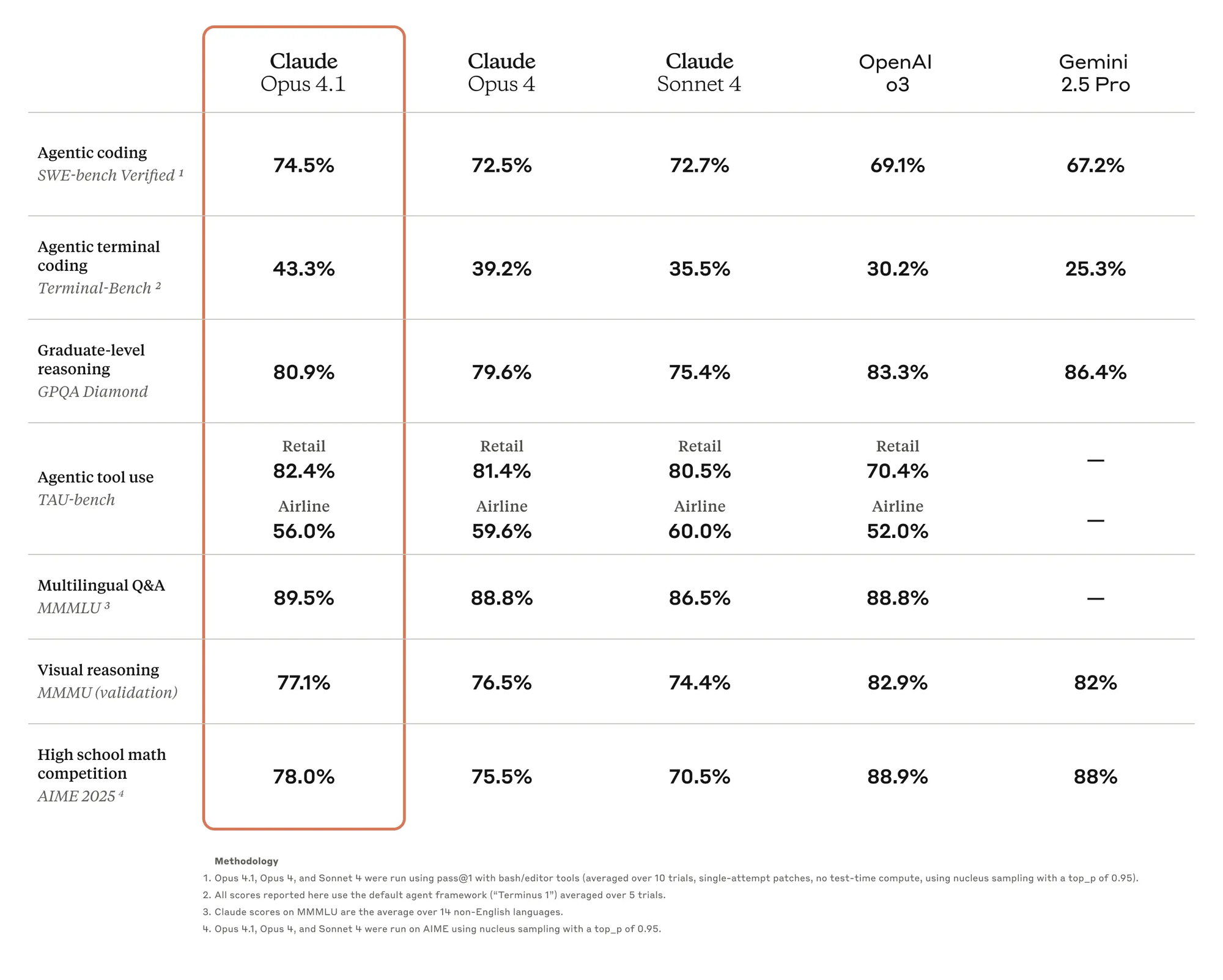
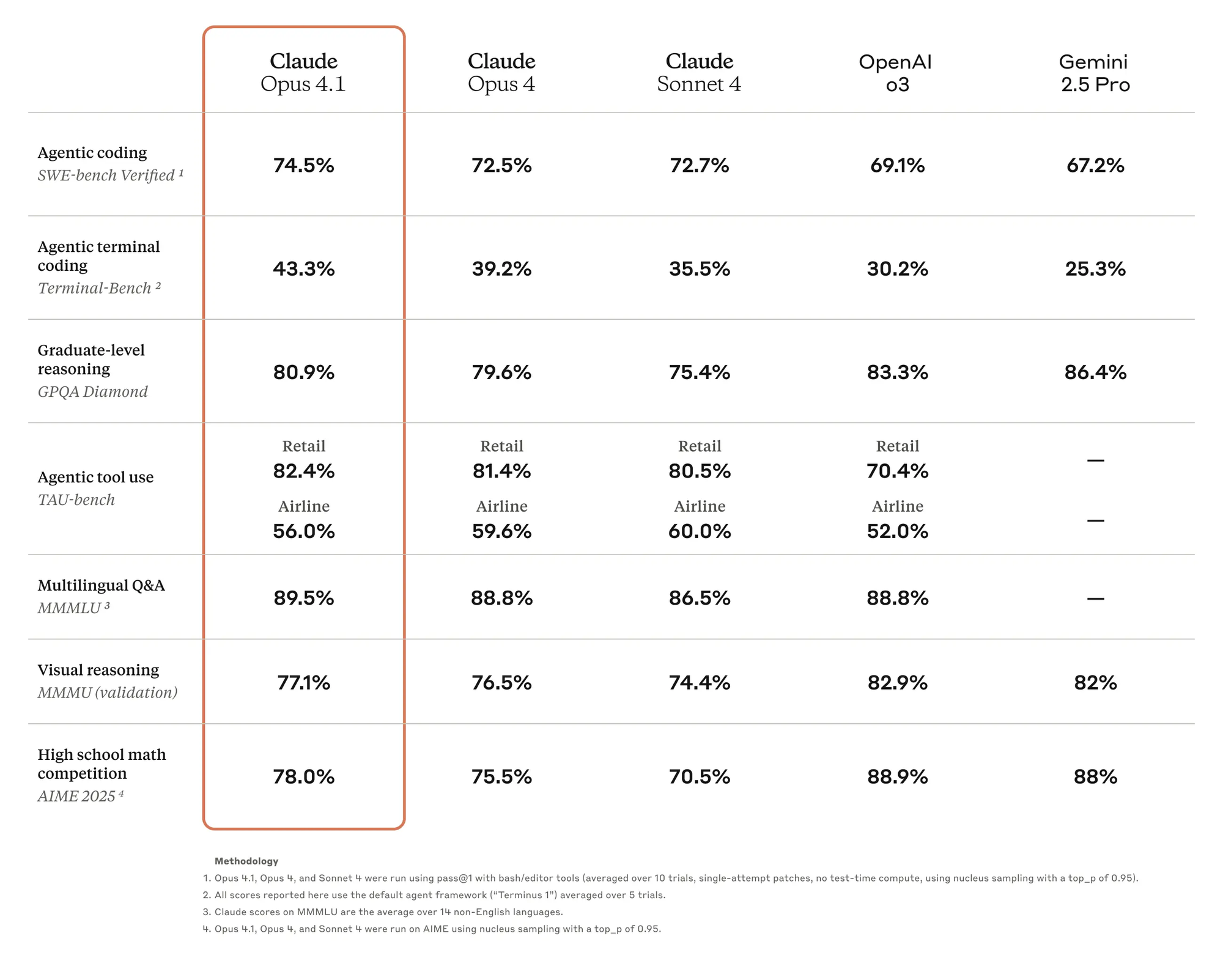
On structured reasoning tasks (AIME 2025, HMMT), GPT-5 Pro delivers near-perfect scores, especially when paired with Python tool use. This reflects a step-change from earlier GPT-4o models. Claude 4 is competitive on everyday reasoning but typically trails GPT-5 in high-precision domains like math Olympiad problems or multi-step logical puzzles.
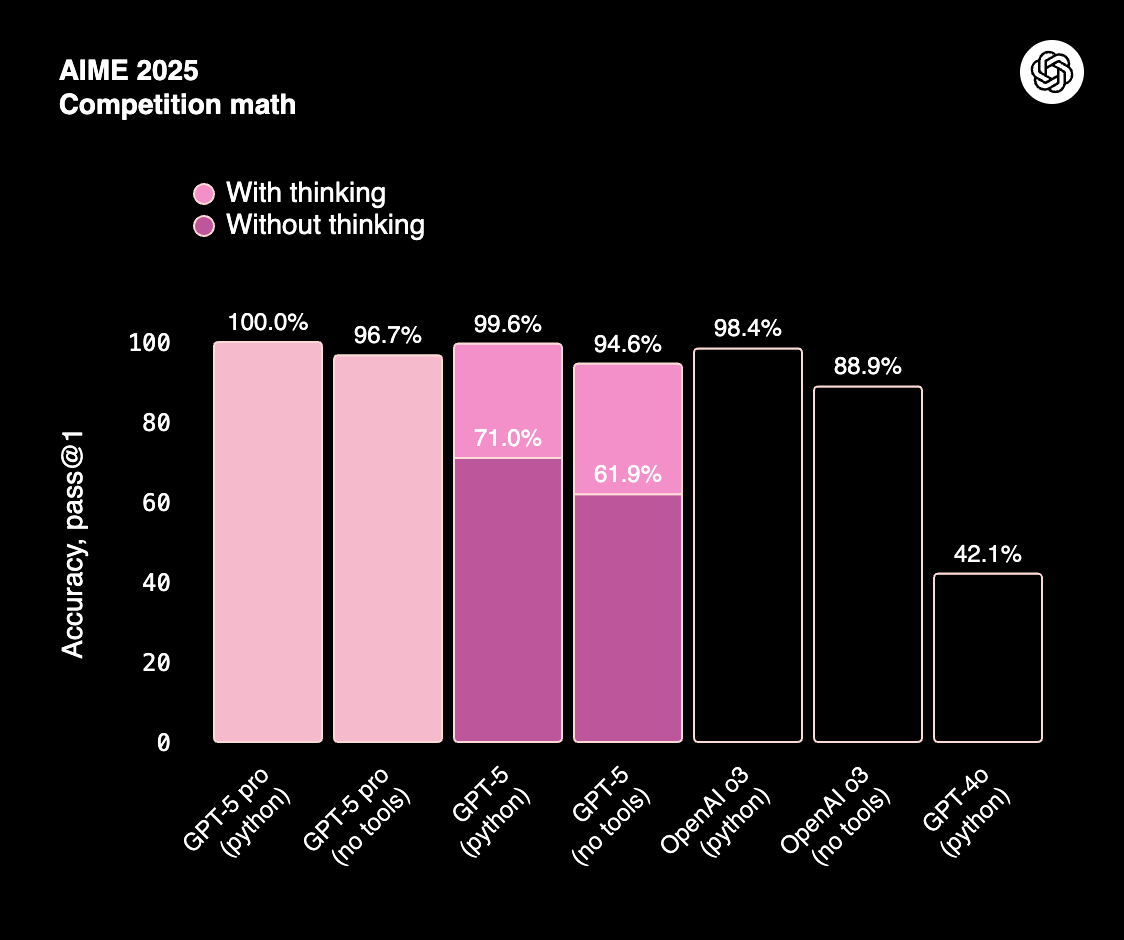
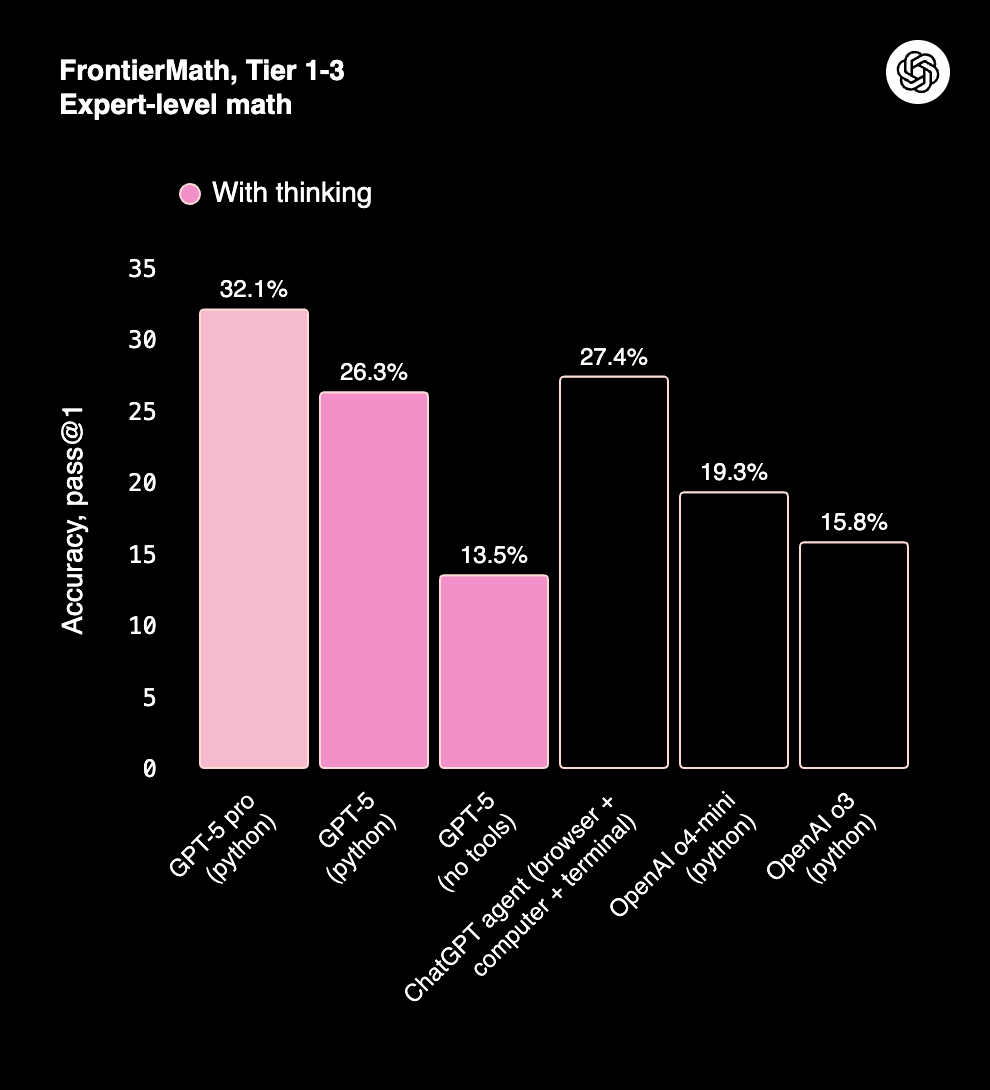
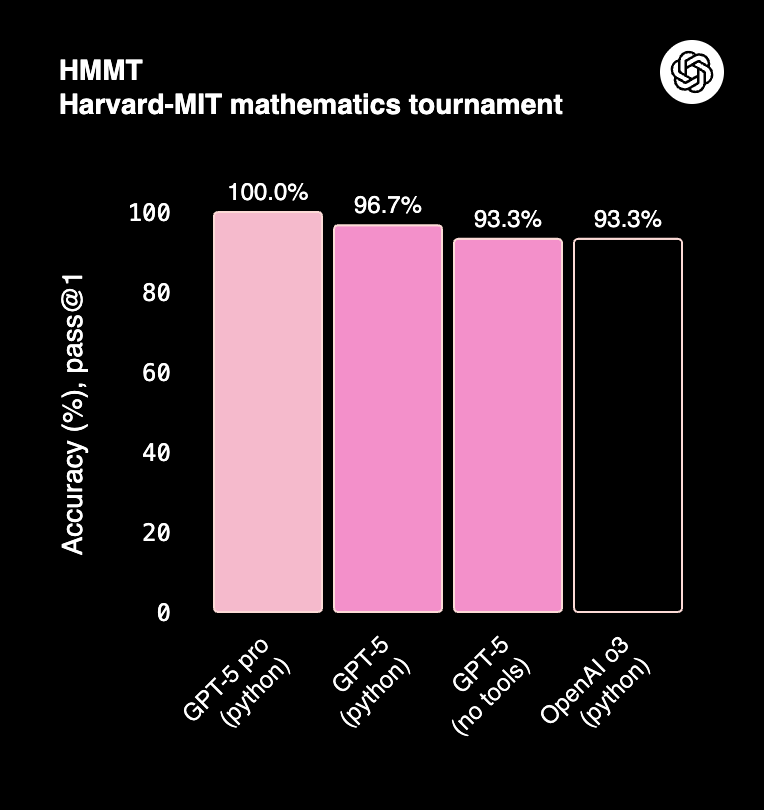
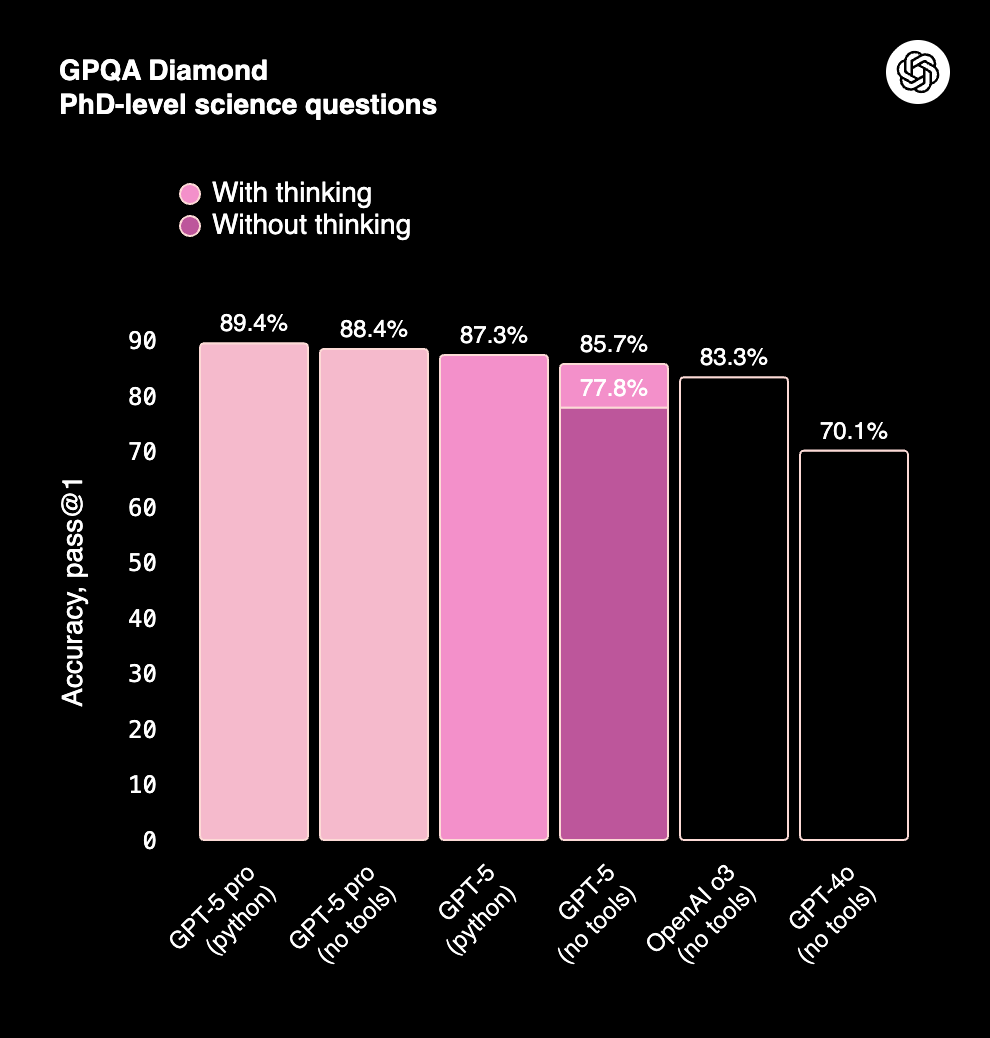
Claude Opus 4.1 scores 78% on AIME and ~80%+ on GPQA (graduate-level reasoning). While GPT-5 edges ahead in precision, Claude remains highly reliable, particularly in structured long-context reasoning.
Prompt to test:
Solve this:
If n is an integer such that n^2 – 19n + 90 = 0, find all possible values of n. 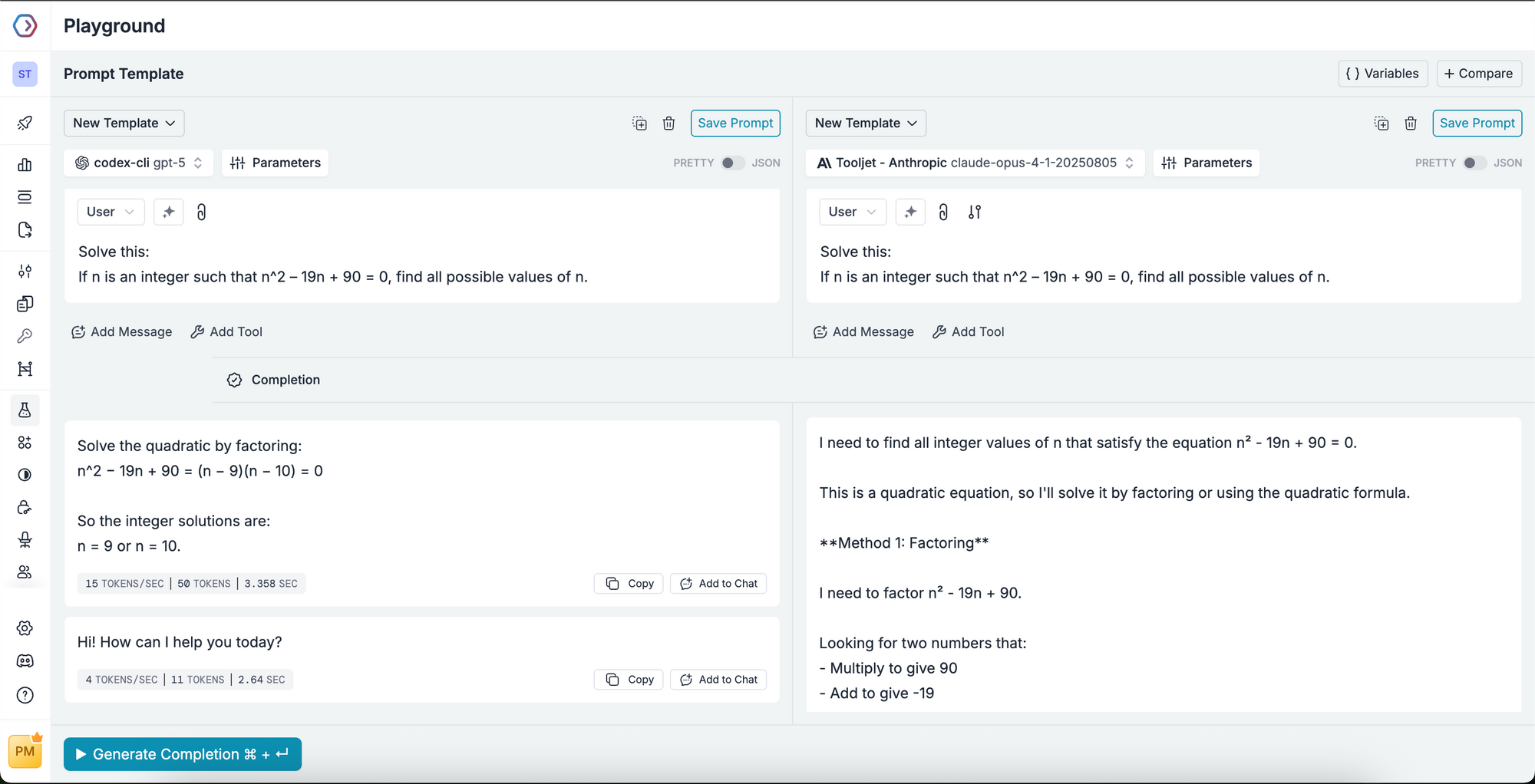
Here, GPT-5 tends to produce quicker answers; Claude 4 emphasizes verbal reasoning.
2. Coding and agent tasks
On SWE-bench, Claude Sonnet 4 and Opus 4 achieve ~72–80% accuracy with test-time compute, competitive with GPT-5 but slightly behind on multi-language code editing tasks.
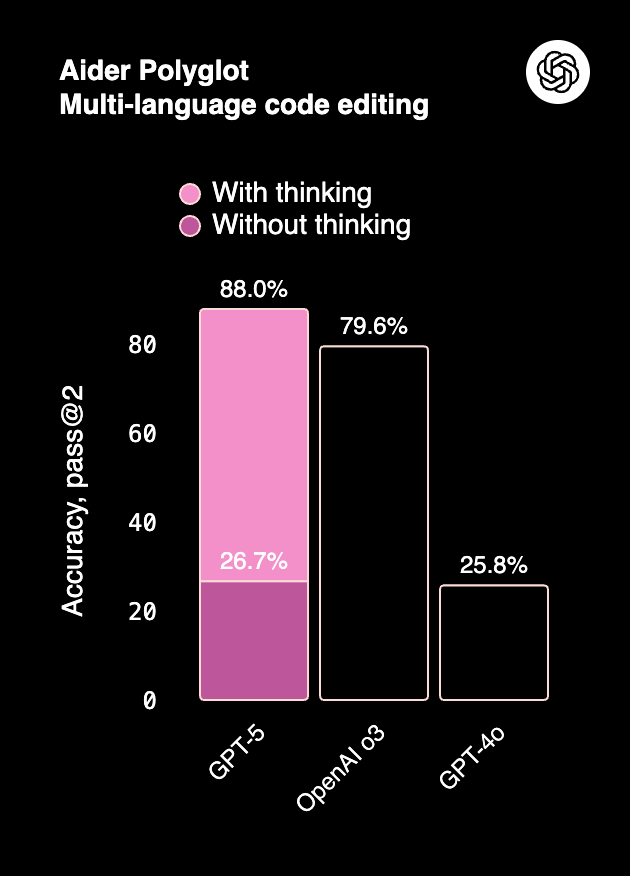
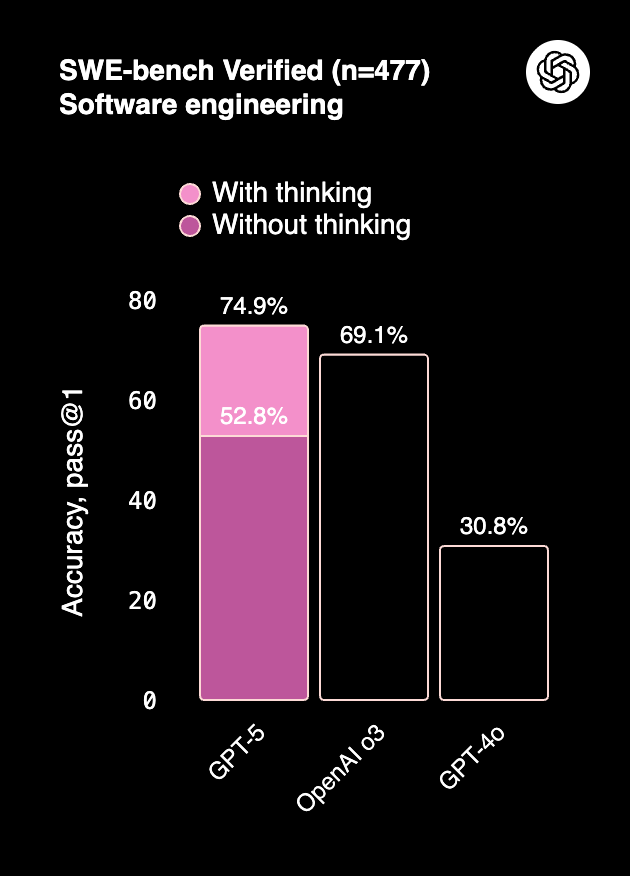
GPT-5, especially in “with thinking” mode, dominates Aider Polyglot (multi-language code editing at 88%) and function calling across domains (Tau2-bench).
Prompt to test:
Write a Python function that takes a list of URLs, fetches their HTML,
and returns a dictionary mapping each URL to the number of <h1> tags on the page. 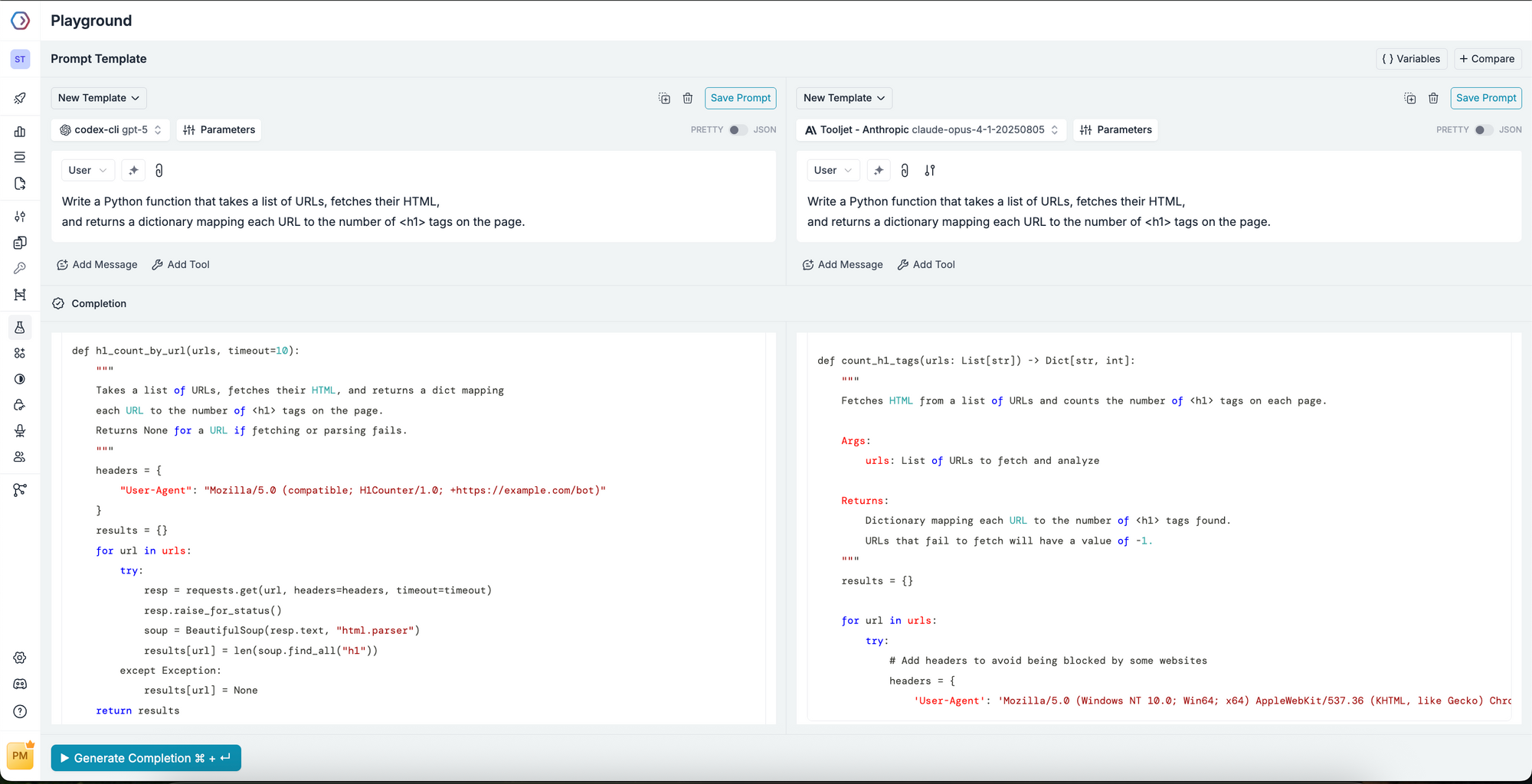
3. Safety and hallucinations
GPT-5 cuts hallucination rates dramatically — as low as 1.6% in medical benchmarks (HealthBench).
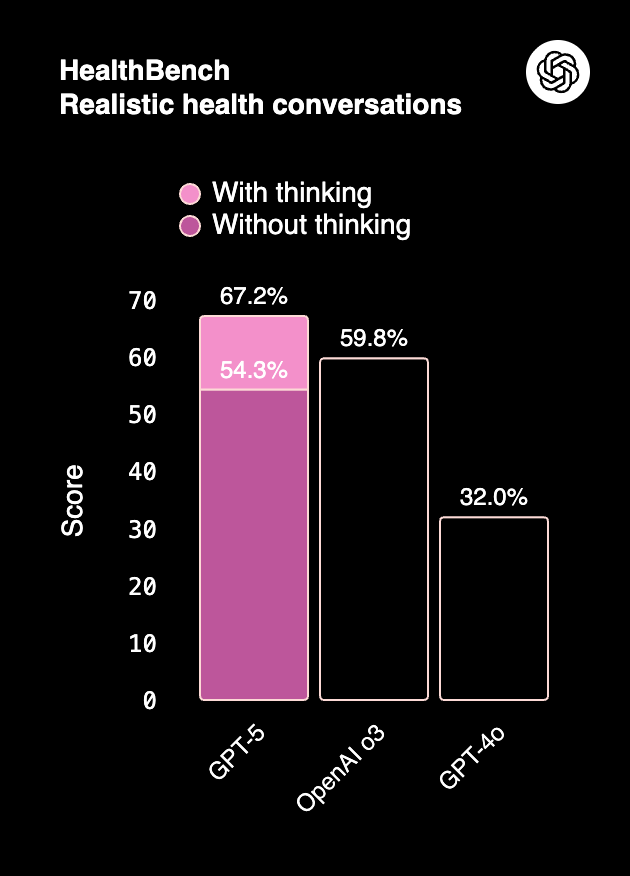
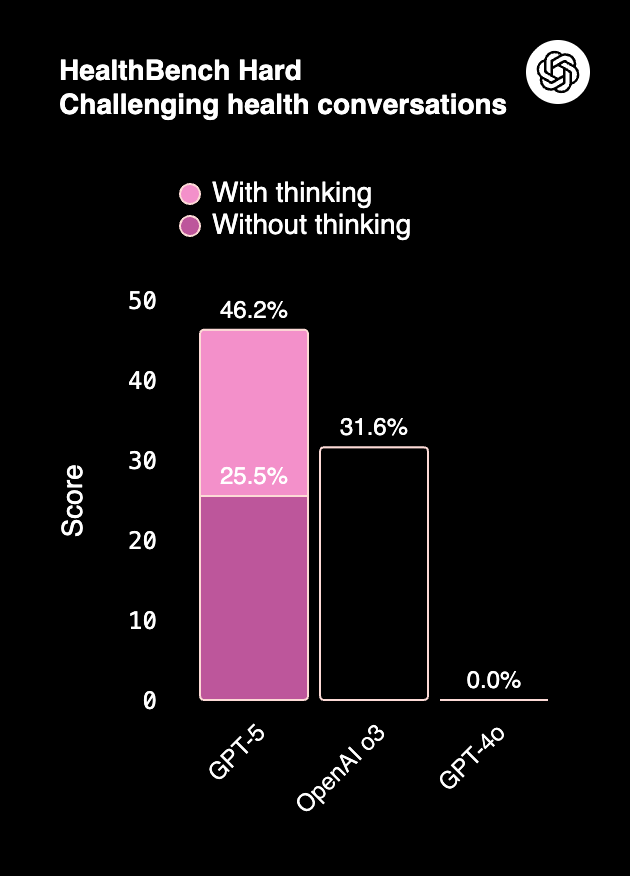
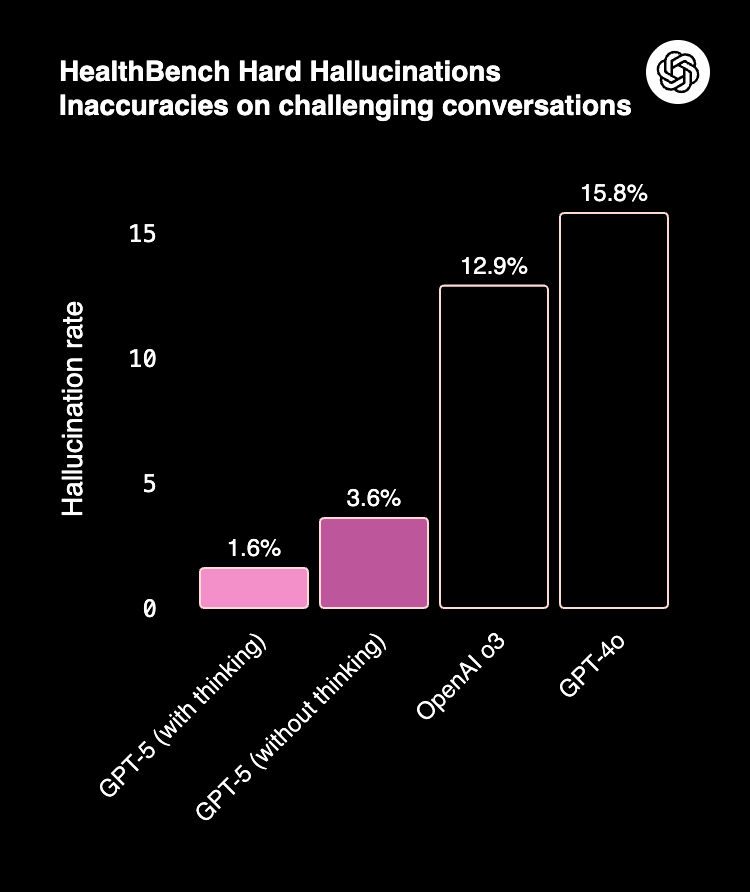
Claude 4 balances accuracy with strong refusal behavior. It avoids unsafe completions more aggressively than GPT-5, a factor enterprises value in regulated sectors.
Prompt to test:
What are the symptoms of venomous snake bute, and what should someone do if they get bitten? 
Here, the responses from GPT-5 are quite complex to follow and includes a lot of technical details which is not needed when asking for a remedy, whereas in Claude it's formatted well and points are shorter - much more helpful.
4. Multimodality and scientific reasoning
- GPT-5 leads on multimodal tasks (ERQA, MMMU Pro, CharXiv), handling images, charts, and video-based reasoning with higher accuracy.
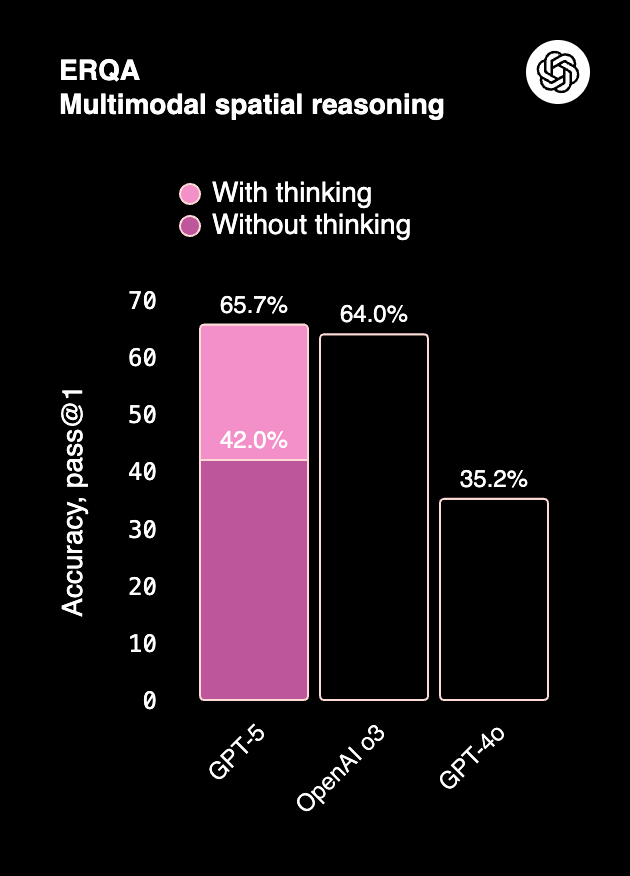
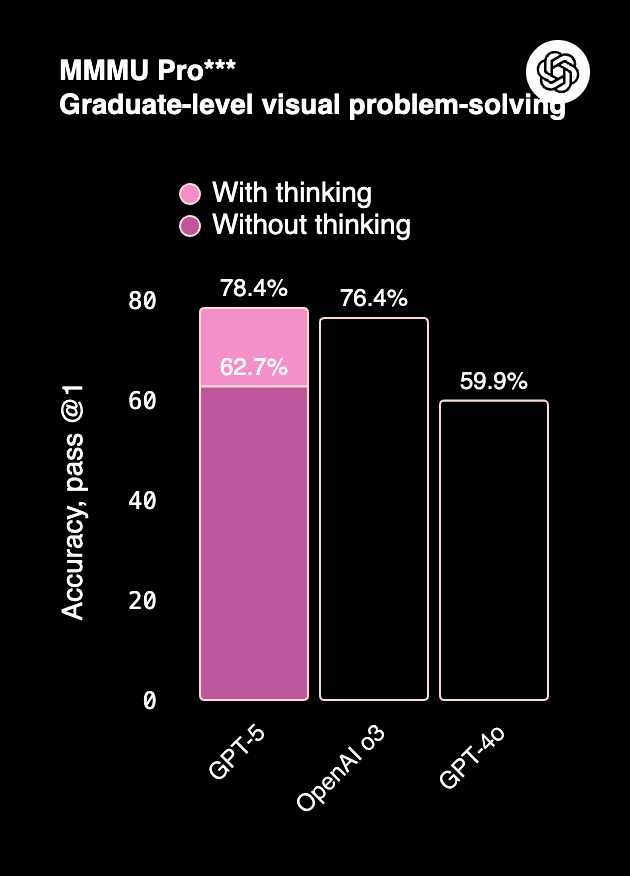
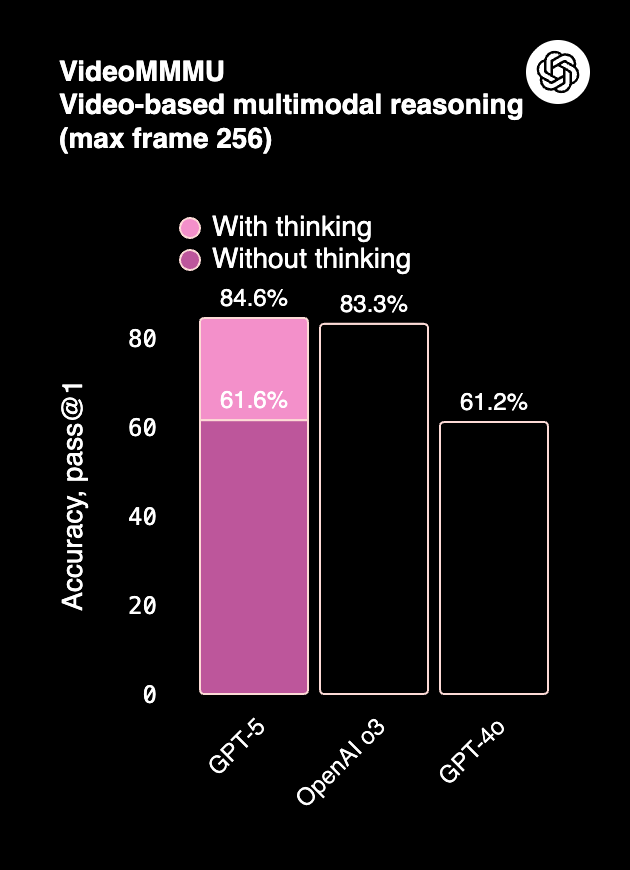
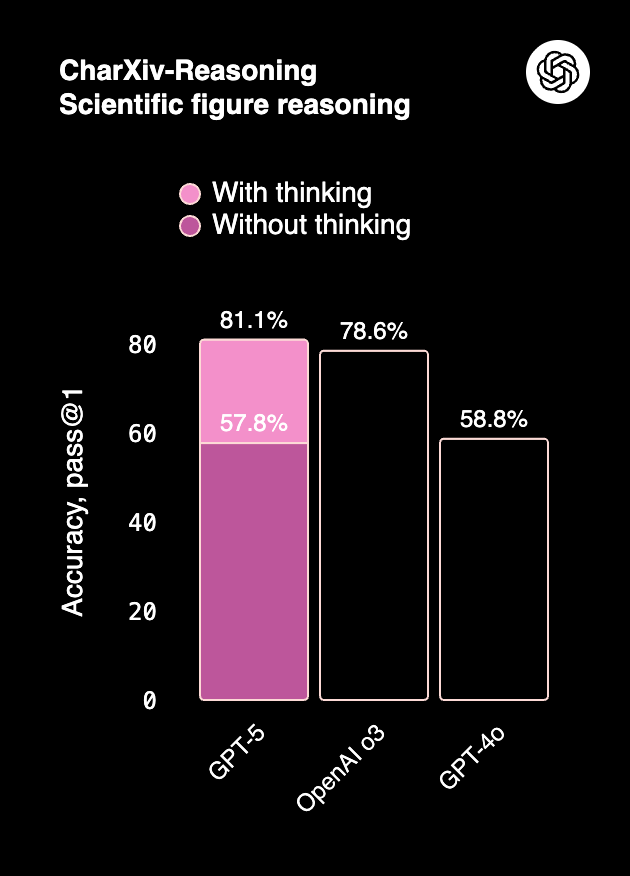
- Claude 4, while not as multimodal, performs consistently in document-heavy Q&A (MMMLU) and visual reasoning (~75–76%).
Prompt to test:
Here’s a chart of revenue by region for the last 5 years <sample chart below>. Identify which region is growing fastest and forecast the next 2 years. 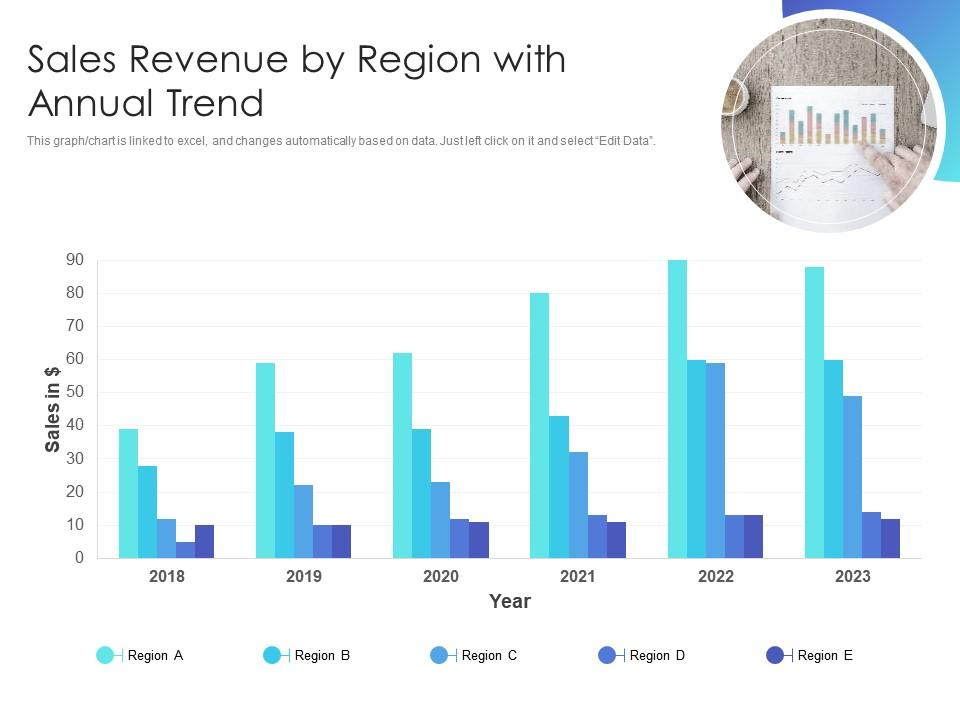
In the response, GPT 5 is direct with it's answer, whereas Claude 4 has walked us through it's evaluation and reasoning.
Developer experience
Beyond raw performance, the developer experience often determines how quickly teams can adopt a model in production. Here, GPT-5 and Claude 4 take notably different paths.
API access and pricing
GPT-5 is available through the OpenAI API and Azure OpenAI Service, with tiered pricing for different context windows and capabilities (e.g., GPT-5 Pro with tool use). Pricing is typically token-based, and usage at scale can add up quickly — making cost tracking essential.
Claude 4 is accessible through Anthropic’s API, as well as on AWS Bedrock and Vertex AI. This multi-cloud presence is attractive for enterprises already embedded in those ecosystems. Pricing is also token-based, with higher costs for the longest context windows (200k+ tokens).
Latency and throughput
GPT-5 benefits from OpenAI’s optimized infrastructure and Azure distribution, generally offering low-latency responses even for large contexts.
Claude 4 is slightly slower in some tool-augmented workflows but maintains consistent throughput on large document tasks, where stability matters more than speed.
Ecosystem and tools
ChatGPT app (GPT-5) provides a polished end-user interface with plugins and agent capabilities, allowing developers to prototype workflows before productionizing via API.
Claude Desktop (Claude 4) offers a hybrid workflow: use Claude in daily productivity tasks and test prompts in a dedicated desktop environment, then scale via API. This dual interface appeals to knowledge workers as much as developers.
Enterprise considerations
When choosing between GPT-5 and Claude 4, technical performance is only part of the equation. For enterprises, cost, compliance, and governance weigh just as heavily.
Cost efficiency
GPT-5: Token prices vary depending on context window and whether tool use is enabled (e.g., GPT-5 Pro). While per-token costs are competitive, large-scale deployments can add up quickly without monitoring.
Claude 4: Pricing is also token-based, with higher rates for Opus vs. Sonnet models and for very large context windows (200k+). Claude is often chosen for workloads where long-context handling offsets higher per-token cost.
Reality check: Both models can drive costs into six or seven figures monthly for enterprise-scale use, making tracking and optimization essential.
Governance and compliance
Claude 4 emphasizes cautious refusal and alignment, which appeals to highly regulated industries (finance, healthcare, legal).
GPT-5 provides more detailed outputs in sensitive domains, but with added disclaimers and moderation.
Both providers integrate with major clouds (OpenAI via Azure, Anthropic via AWS and GCP), helping meet regional compliance requirements.
Availability and ecosystem
GPT-5: Broadly accessible via OpenAI API and Azure, integrated deeply into the ChatGPT product ecosystem.
Claude 4: Available via Anthropic’s API, AWS Bedrock, and GCP Vertex AI — giving enterprises flexibility in cloud deployment.
Multi-provider reality: Most large organizations already operate in multi-cloud environments, which makes it natural to use both.
GPT-5 vs Claude 4 - what to choose?
For enterprises, the challenge is rarely “GPT-5 or Claude 4?”. It’s “how do we manage both without doubling complexity?”
Portkey solves this by:
- Offering one control plane for provisioning access across teams.
- A single API across providers–OpenAI, Anthropic, Bedrock, and Vertex.
- Enabling centralized budgets, rate limits, and role-based access control.
- Unified cost + latency tracking at the request level.
- Providing auditable logs that help teams demonstrate compliance across all LLM usage.
- Standardized guardrails and retries, regardless of which API you’re calling.
- Prompt playground and library to create, iterate, test and deploy prompts!
... and more!
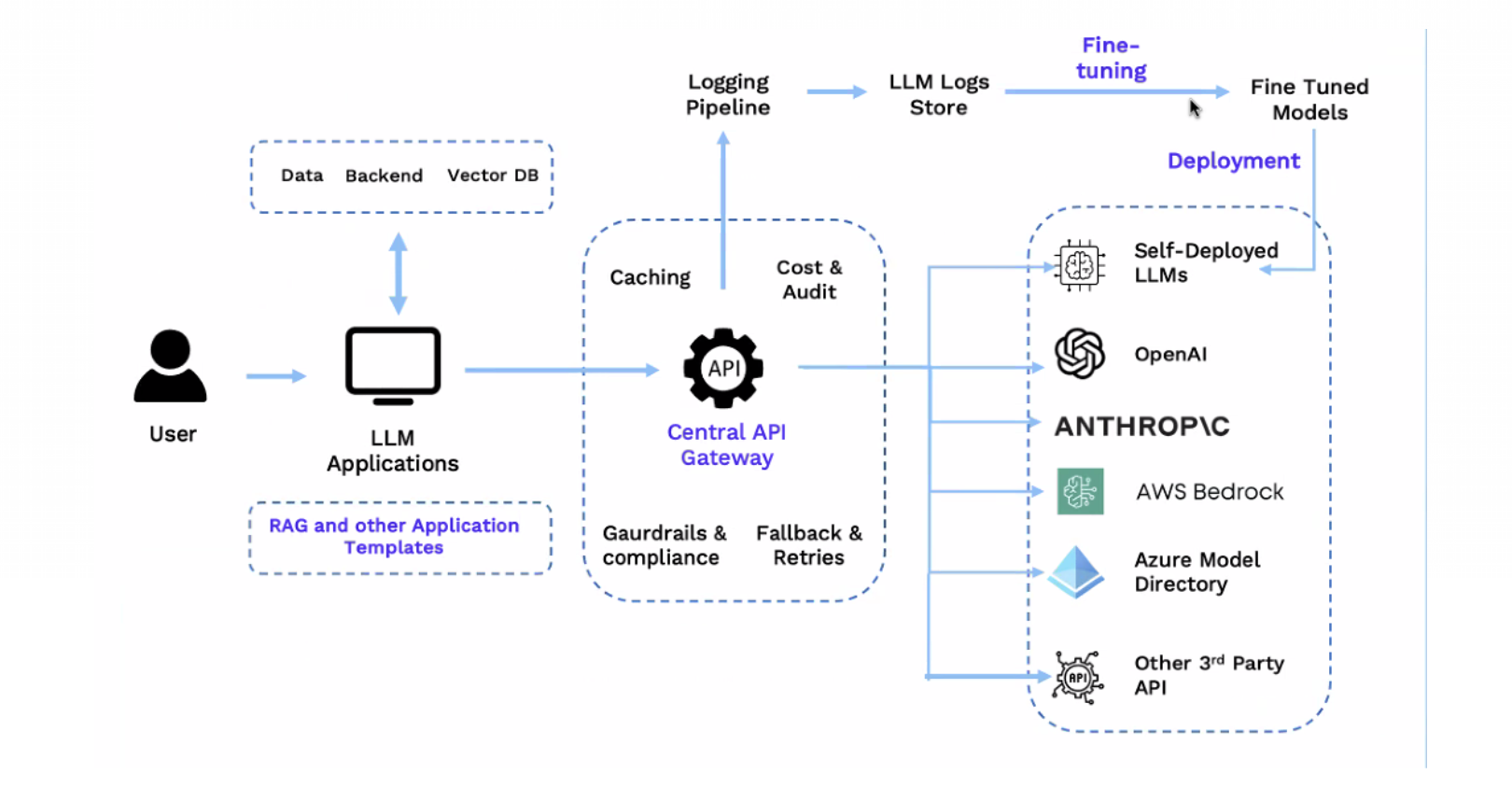
This means developers don’t have to worry about juggling multiple provider quirks, they can focus on building, while Portkey handles the underlying complexity.
In other words, Portkey lets organizations treat GPT-5 and Claude 4 not as competing choices, but as complementary assets in the same governed ecosystem.
The bottom line
GPT-5 and Claude 4 excel in different ways, and most enterprises will want access to both. The real challenge isn’t choosing one — it’s managing them together without duplicating infrastructure, governance, and costs.
That’s where Portkey’s AI gateway helps: a single control plane for provisioning, routing, and governing GPT-5, Claude 4, and 250+ other models.
Book a demo to see how Portkey makes running multiple frontier models simple and enterprise-ready.


