
How to choose the right AIOps platform
Your AI agent has been routing requests incorrectly, but your dashboards still show green because the infrastructure is healthy.
Traditional ops were built for infrastructure systems. They do not account for workloads where correctness depends on prompts, models, and multi-step reasoning. This guide outlines what enterprises should expect from an AIOps platform built for generative AI.
AI Agents and LLM apps are now production-critical systems
Enterprises are embedding LLMs into revenue-generating, customer-facing, and internal decision workflows. An agent that routes customer requests, summarizes contracts, or generates compliance documents is now a system of record.
However, only 43% of organizations say their data is ready for AI, and fewer than 30% of AI leaders think their CEOs are satisfied with GenAI results
Failures in LLM systems behave differently from infrastructure outages. A server is either up or down; it is binary. An LLM failure can be invisible. Wrong outputs that look correct, missed guardrails that go undetected, or runaway token costs that only appear on next month's bill.
The blast radius is qualitatively different. One hallucinated response from a customer support agent can trigger dozens of escalation tickets before anyone notices the pattern.
Teams are discovering that server-uptime thinking does not apply to LLM systems. Their correctness is probabilistic, and their behavior shifts with model and prompt changes. Without purpose-built operational tooling, enterprises are flying blind on their most strategically important systems.
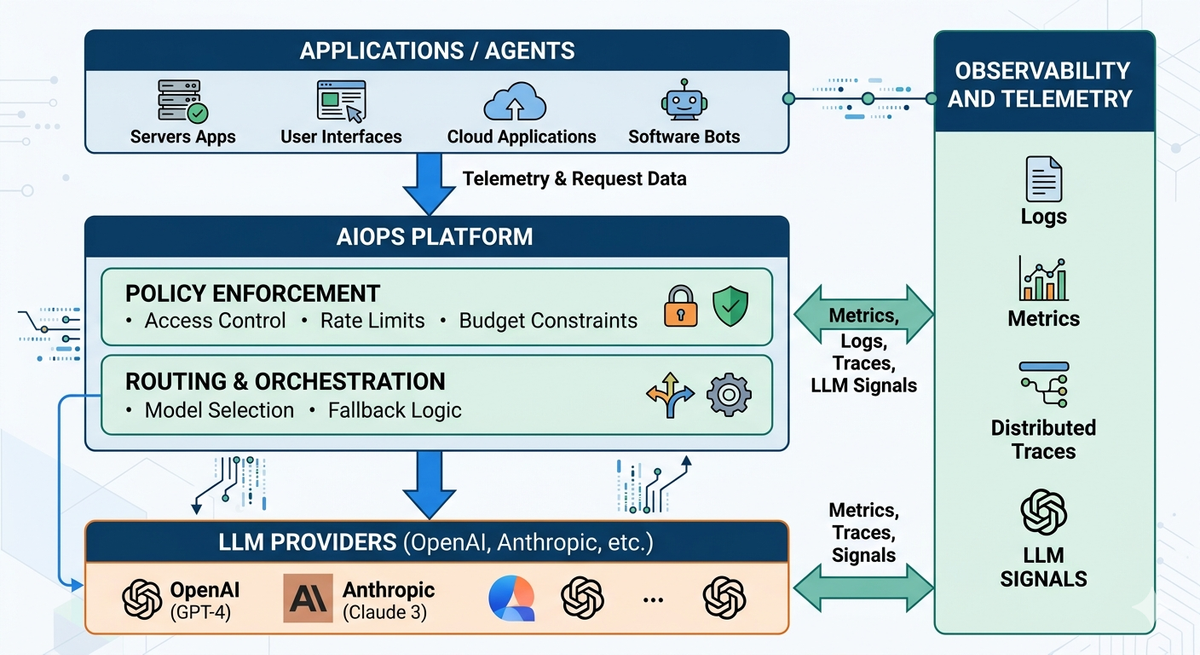
Five capabilities to evaluate in an AIOps platform
When evaluating an AIOps platform for LLM and AI agent workloads, these five capabilities should be considered.
1. Unified LLM observability
- Full request-level visibility across every model call, with distributed tracing for multi-step agent flows and analytics for latency, cost, and output behavior.
Portkey's observability layer is OTEL-compliant and captures the full request lifecycle: prompts, responses, token usage, latency, and metadata, all searchable and traceable across multi-step agent flows. This is backed by analysis of over 2 trillion production tokens processed across 3000+ models and 90+ regions.
2. Routing and resilience
- Fallbacks to secondary models when a primary provider fails.
- Load balancing across providers.
- Conditional routing based on request type, cost target, or latency requirements.
- Caching to reduce redundant model calls.
Portkey's AI Gateway helps you set up load balancing, fallbacks, conditional routing, to keep your apps reliable, even on production scale.
3. Guardrails and safety controls
- Real-time enforcement of content and safety policies on both inputs and outputs.
- Protection against prompt injection attacks
- The ability to route or reject requests that fail checks before they reach users, not just log them after.
Portkey runs 50+ guardrail checks, including both rule-based and model-based checks, helping you stay under compliance.
4. Prompt management and versioning
- Collaborative prompt template creation with version control.
- Deploy prompt changes without code releases.
- Experimentation across models using the same prompt template.
Portkey's prompt studio lets teams create, version, and deploy prompt templates without code changes, and run experiments across models using the same template. Prompt changes can be promoted across environments independently of application deployments.
5. Governance and cost controls
- RBAC to control which teams and applications can access which models.
- Per-workspace and per-user budget limits.
- Audit logs that tie every LLM output to the team, prompt, and model that produced it.
Portkey manages over $180 million in annualized AI spend across its customer base, with per-team cost attribution, virtual key management, role-based access control, and full audit trails. It is ISO 27001 and SOC 2 certified, GDPR and HIPAA compliant, with SSO support for enterprise identity integration.

How enterprises actually adopt an AIOps platform
Most teams already have LLMs running in production before they formalize how to operate them. The starting point should be getting clear on what you cannot currently see.
- Start by identifying one workflow and routing it through Portkey to get immediate visibility into requests, costs, and failures.
- Add routing and fallback rules next. Understanding your traffic patterns first makes it easier to write policies that reflect how your system actually behaves.
- Introduce guardrails before prompt versioning. Safety controls are harder to retrofit once workflows are in production.
- Roll out governance, access control, and cost attribution last. These require enough operational history to set limits that are meaningful rather than arbitrary.
What changes when LLMs become operational systems
As agentic AI systems become more autonomous and multi-step, the need for centralized control only increases.
If you are already running LLMs in production, the next step is centralizing how those systems are routed, monitored, and controlled. Explore Portkey’s documentation to see how this works in practice, or book a demo with us.
FAQs
Q: What makes LLM cost management harder than traditional systems?
Costs scale with tokens and multi-step workflows, making them unpredictable without request-level tracking and budget enforcement.
Q: Do you need to change your application code to adopt AIOps?
No. Most platforms start by routing existing traffic through a gateway to capture logs, apply controls, and add observability.
Q: How do teams debug multi-step agent failures?
By tracing the full execution path across model calls, tools, and prompts to identify where the output diverged.
Q: When should an enterprise introduce governance for LLM usage?
As soon as multiple teams or workflows use LLMs, before cost, access, and compliance issues scale.