LLM routing techniques for high-volume applications
High-volume AI systems can’t rely on a single model or provider. This guide breaks down the most effective LLM routing techniques and explains how they improve latency, reliability, and cost at scale.
High-volume AI applications don't depend on a single model or provider.
Routing steps in as the control layer that keeps applications stable under load. For teams serving millions of requests, this flexibility is the difference between smooth operation and unpredictable outages.
In this blog, we'll discuss different LLM routing techniques and how you can apply them to your AI workloads.
How routing differs from simple model selection
Most teams begin with static model selection: pick one model for a task, wire the endpoint, and ship. This works at small scale but breaks down quickly under real production traffic. High-volume systems need something more adaptive, and that’s where LLM routing techniques come in.
Model selection is a one-time architectural decision. Routing is continuous decision-making. Instead of binding every request to a predetermined model, you can evaluate each request against real-time signalsand choose the best model for that moment.
Static selection assumes the environment is stable. Routing assumes things will vary. And at scale, they always do. Traffic surges, providers throttle, latency drifts regionally, or a newer model becomes more cost-efficient. Routing absorbs this volatility so applications don’t have to.
Challenges in high-volume workloads that routing solves
As applications scale, the behavior of LLMs becomes increasingly uneven. Providers operate under fluctuating load, pricing structures shift, and latency patterns vary across regions and times of day. LLM routing techniques exist precisely to handle these challenges.
Unpredictable latency variance
Even the best models can swing from 200ms to 800ms. When every millisecond matters—search, chat, support automation—these spikes degrade user experience. Routing helps maintain consistency by choosing the fastest healthy endpoint in real time.
Rate limits and throttling
Providers impose hard and soft limits that are easy to hit during traffic surges. Retry storms make this worse. Effective routing distributes load across models or providers to avoid saturating any single endpoint.
Cost instability at scale
What seems affordable at 10,000 requests becomes unsustainable at 10 million. Always using frontier models creates unnecessary spend for routine or low-sensitivity tasks. Routing enables cheaper paths without compromising output quality where it matters.
Provider degradation or outages
Models occasionally slow down, return elevated error rates, or fail entirely. Without routing, these incidents become application-wide outages. With routing, systems can detect degradation and shift traffic within seconds.
High-volume environments make these challenges unavoidable but with the right LLM routing techniques, they become manageable, predictable, and often invisible to users.
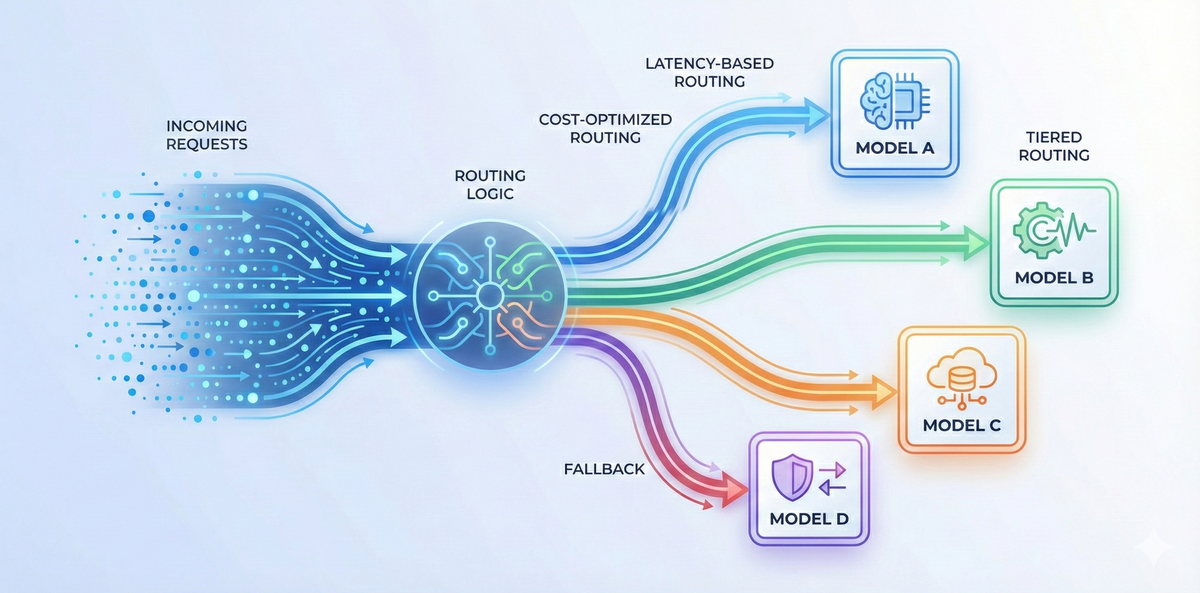
LLM routing techniques
Conditional routing
Latency-based routing
Some applications need consistently fast responses—search, support chat, and consumer-facing assistants. Latency-based routing directs traffic to the model or provider that historically responds the fastest for the given region or workload.
Cost-based routing
High-volume workloads amplify every pricing difference. Instead of sending all requests to a frontier model, cost-based routing classifies traffic and steers low-sensitivity or repetitive tasks to cheaper models.
Examples:
- Content rewrites → economical models
- Complex planning → high-accuracy models
- Internal automation → mid-tier models
This is one of the most impactful LLM routing techniques for keeping spend predictable at scale.
Region-aware routing
Routing requests to the closest deployment or provider region improves latency and reduces cross-border data movement. For regulated industries or global applications, geo-location based routing is essential for both speed and compliance.
Semantic routing
Semantic routing classifies the intent of the request and routes it to the model best suited for that task. This can be embedding-based, rule-based, or classifier-driven.
Examples:
- Coding tasks → code-optimized models
- Summaries → small, fast models
- Reasoning tasks → frontier models
This approach dramatically improves quality-to-cost ratio.
Metadata-based routing
Traffic often varies by team, tier, or workload type. Metadata-based routing uses contextual information to determine which model a request should hit.
This allows organizations to enforce:
- different cost ceilings per team
- stricter models for sensitive workloads
- lightweight models for experimentation
Metadata becomes a simple but powerful dimension in LLM routing techniques, especially inside large organizations.
Performance-based routing techniques
While conditional routing relies on predefined rules, performance-based routing reacts to what’s happening right now. These LLM routing techniques use real-time signals like latency, error rates, throughput, and health checks to make decisions dynamically.
Load-based routing
LLM providers often enforce strict rate limits. When traffic spikes, a single endpoint can saturate quickly, leading to throttling or elevated error rates. Load-based routing allows you to distribute requests across multiple models or providers to keep every endpoint below its capacity threshold.
This is especially important for:
- consumer-scale applications with bursty traffic
- agent workloads generating many parallel requests
- batch processing pipelines with high concurrency
By smoothing load across the system, it prevents cascading failures and maintains consistent throughput.
Fallback routing
Providers can degrade without warning from latency spikes, error codes rise, or throughput collapses. Fallback routing ensures that when a primary model fails or slows down, traffic automatically switches to a secondary or tertiary model.
Fallback chains are critical for uptime-sensitive workloads because they remove the single point of failure inherent in relying on any one provider.
Circuit breakers
Circuit breakers temporarily “trip” a failing route to protect the system. When error rates or timeouts cross a threshold, the route is disabled for a cooldown period while traffic is diverted elsewhere.
This prevents the system from repeatedly calling a degraded endpoint, avoids retry storms, and stabilizes behavior during provider outages or maintenance windows.
Canary testing
Before adopting a new model or upgrading to a new version, canary routing sends a small percentage of traffic—1–5%—to the candidate model. Teams can observe quality, latency, and cost metrics in production before rolling out fully.
This is one of the safest LLM routing techniques for introducing new models without risking production regressions.
Observability requirements for effective routing
Routing only works as well as the signals you feed into it. High-volume systems need continuous visibility into model behavior so that routing decisions remain accurate, timely, and cost-aware. Without LLM observability, even the most advanced LLM routing techniques become guesswork.
Real-time latency and throughput metrics
Latency isn’t static. Providers fluctuate throughout the day, and different regions behave differently. Routing engines need a live view of:
- p50 / p95 latency
- token throughput (tokens/sec)
- variance across regions and providers
Error rates and provider health
Errors tend to spike before full outages. Tracking failure patterns helps performance-based routing decide when to apply fallbacks or trip circuit breakers. Key indicators include:
- timeout frequency
- 429 and 5xx spikes
- connection or rate-limit failures
Cost and token usage visibility
Routing decisions, especially cost-based ones, depend on knowing token consumption and effective cost per request. High-volume teams need granular insight into:
- token usage per model
- cost per route
- cost drift over time
Model comparison insights
To refine routing rules, teams need to know how models actually perform under real workloads. Observability should surface:
- quality deltas across models
- model regressions after version changes
- output differences for similar inputs
Feedback loops
The best routing setups continuously learn. Observability closes the loop between offline evaluation and online performance, allowing teams to adjust conditions, thresholds, and fallback priorities as the system evolves.
With proper observability, LLM routing techniques become predictable, measurable, and aligned with real user experience.
How Portkey supports advanced LLM routing at scale
High-volume teams need routing that adapts instantly to shifting latency, cost, or provider performance. Portkey was built as an AI Gateway to give teams this exact control layer without building it themselves. It brings both conditional and performance-based LLM routing techniques into a single, production-grade system.
Multi-provider routing with one API
Portkey connects to 1,600+ models across leading providers. This makes routing decisions fully transparent and manageable through one unified interface.
Dynamic per-request routing
Routing rules can be applied using real-time context:
- budget ceilings or cost thresholds
- metadata (team, workload, risk level)
- rate limits
- guardrail checks
This means each request can take the most efficient path without manual orchestration.
Built-in performance protection: fallbacks, circuit breakers, and load management
Portkey continuously monitors provider health and automatically redirects traffic when a model slows, errors spike, or rate limits are reached. This protects applications from upstream volatility and prevents outages from spreading.
Budgets, guardrails, and semantic caching for cost control
High-volume workloads often face cost drift. Portkey pairs routing with budget policies, guardrails, and semantic caching so teams can keep spend predictable even as usage scales.
End-to-end observability
Latency, token usage, errors, cost, and routing decisions are all captured automatically. This visibility helps teams tune routing strategies, evaluate model performance, and understand how decisions impact reliability and cost.
If you want to adopt intelligent, multi-provider LLM routing techniques without building the infrastructure yourself, Portkey’s AI Gateway gives you a ready-to-use routing layer that scales reliably with your traffic.
If you'd like to apply these LLM routing techniques across providers, you can try it out with Portkey or book a demo with the team to learn more.