LLMs in Prod: The Reality of AI Outages, No LLM is Immune

This is Part 2 of our series analyzing Portkey's critical insights from production LLM deployments. Today, we're diving deep into provider reliability data from 650+ organizations, examining outages, error rates, and the real impact of downtime on AI applications. From the infamous OpenAI outage to the daily challenges of rate limits, we'll reveal why 'hope isn't a strategy' when it comes to LLM infrastructure
Check this out!
🚨 LLMs in Production: Day 3
— Portkey (@PortkeyAI) December 13, 2024
“Hope isn’t a strategy.”
When your LLM provider goes down—and trust us, it will—how ready are you?
Today, we’re sharing fresh data from 650+ orgs on LLM provider reliability, downtime strategies, and how to keep things running smoothly (while…
Before that, here’s a recap from Part 1 of LLMs in Prod:
— Portkey (@PortkeyAI) December 13, 2024
• @OpenAI dominance is eroding, with Anthropic slowly but steadily gaining ground
• @AnthropicAI requests are growing at a staggering 61% MoM
• @Google Vertex AI is finally gaining momentum after a rocky start.
Now,… pic.twitter.com/4MjD63EWyJ
Remember the OpenAI Outage?
— Portkey (@PortkeyAI) December 13, 2024
In just one day, they reminded the world how critical they are—by taking everything offline for ~4 hours. 😛
But here’s the thing: this wasn’t an anomaly.
Outages like these are a recurring pattern across ALL providers.
Which begs the question: why… pic.twitter.com/HYNVeZlSpo
📊 Over the past year, error spikes hit every provider—from 429s to 5xxs, no one was spared.
— Portkey (@PortkeyAI) December 13, 2024
The truth?
There’s no pattern, no guarantees, and no immunity.
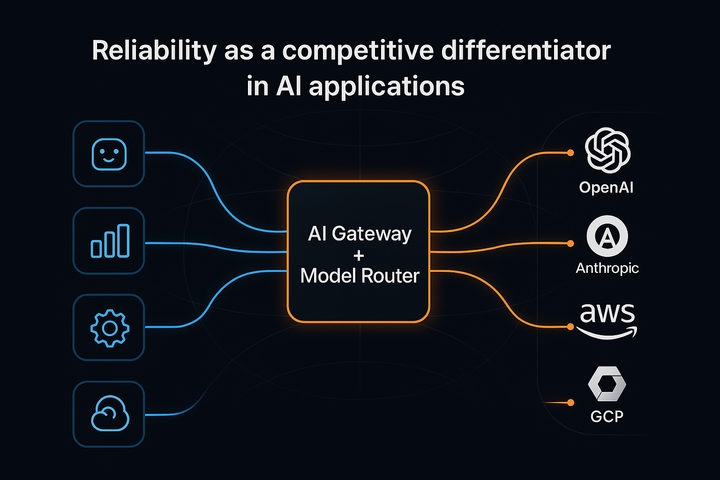
If you’re not prepared with multi-provider setups, you’re inviting downtime.
Reliability isn’t optional—it’s table… pic.twitter.com/MDpSfSrYft
Rate Limit Reality Check:
— Portkey (@PortkeyAI) December 13, 2024
• @GroqInc : 21.11%
• @Perplexity: 12.24%
• @AnthropicAI : 5.60%
• @Azure OpenAI: 1.74%
Translation: If you're not handling rate limits gracefully, you're gambling with user experience.
Your customers won’t wait for infra to catch up. Are you… pic.twitter.com/GiJwXdPMuQ
But rate limits are just the tip of the iceberg.
— Portkey (@PortkeyAI) December 13, 2024
Server Error (5xx) rates this year:
• Groq: 0.67%
• Anthropic: 0.56%
• Perplexity: 0.39%
• Gemini: 0.32%
• Bedrock: 0.28%
Even "small" error rates = thousands of failed requests at scale.
These aren’t just numbers—they’re… pic.twitter.com/0CqdEGfYc0
So, what’s the solution?
— Portkey (@PortkeyAI) December 13, 2024
The hard truth? Your users don't care why your AI features failed.
They just know you failed.
The key isn’t choosing the “best” provider—it’s building a system that works when things go wrong:
💡 Diversify providers.
💡 Implement caching.
💡 Build smart…
6/ Why caching matters:
— Portkey (@PortkeyAI) December 13, 2024
Performance optimization is critical, and here’s where caching delivers results:
• 36% average cache hit rate (peaks for Q&A use cases)
• 30x faster response times
• 38% cost reduction
Caching isn't optional at scale—it's your first line of defense. pic.twitter.com/YX7YvwkmMS
That’s it for today! Follow @PortkeyAI for more on LLMs in Prod Series
— Portkey (@PortkeyAI) December 13, 2024
— Portkey (@PortkeyAI) December 13, 2024