MCP vs RAG Compared for Production Teams
MCP doesn't replace RAG. Learn when to use each, how to combine them, and the security and governance patterns production teams actually need.

When teams put Large Language Models (LLMs) into production, they usually want two things:
- Accurate answers from their company’s knowledge.
- The ability for the AI to take real actions inside live systems.
Retrieval-Augmented Generation (RAG) solves the first problem by searching through documents like help articles, policies, and PDFs to ground responses in trusted sources. The Model Context Protocol (MCP), introduced by Anthropic in November 2024, solves the second problem by giving LLMs a standardized way to call APIs, query databases, and trigger workflows.
Although they’re often compared, RAG and MCP aren’t alternatives. They address different parts of how AI systems “know” versus how they “do.” That’s why production teams are increasingly using both together.
If you want to know more about MCP vs. RAG, you’re in the right place. This article lays out how to choose between RAG and MCP, secure action-taking agents, manage token costs, and build reliable hybrid workflows.
How to decide between RAG, MCP, or both
At a high level, the choice comes down to whether your AI system primarily needs to understand knowledge or interact with live systems.
Here’s RAG vs MCP at a glance:
Use RAG when the problem involves semantic search over long-form text – product documentation, compliance policies, onboarding guides, or internal wikis. If the agent needs to understand language at scale, RAG is the right abstraction.
Use MCP when the agent must work with structured data or take actions: filtering inventory by price and availability, updating customer records, triggering refunds, or pulling live telemetry.
✨ Use both RAG and MCP when knowledge informs action, which is where most real systems land.
MCP does not replace RAG. A production-grade customer service AI typically uses RAG for knowledge and policy grounding, while MCP handles orders, refunds, account updates, and system state. Neither is sufficient on its own, but together, they form a complete operational layer for AI in production.
For instance, consider a SaaS company with 50,000+ help articles and an active user base. When a customer asks, “How do I set up SSO?”, RAG retrieves the relevant documentation with precise citations.
But when another user reports, “My integration broke after last night’s deploy,” static docs aren’t enough. The agent needs live context. MCP tools can query the incident status page, pull the user’s configuration and recent error logs from APIs, and even trigger a rollback or escalate a ticket.
Security risks when LLMs can take actions
Once an LLM moves beyond answering questions and starts interacting with live systems, the security model changes.
RAG is largely a read-only architecture. Its primary risks involve data exposure – leaking sensitive documents, embedding private information into vector stores, or allowing users to retrieve content they shouldn’t see. These are serious governance concerns, but they live in the world of data-at-rest.
MCP, by design, enables write access, workflow triggers, and direct interaction with production infrastructure – the same privileges traditionally guarded behind carefully scoped service accounts and human approvals. A compromised or poorly governed agent can leak information, modify records, process refunds, deploy changes, or trigger irreversible business actions.
Compared to this, RAG’s risks are narrower and easier to reason about, thanks to vector database access controls, document-level permissions, and PII handling. The failure mode is typically overexposure of information, not unintended execution.
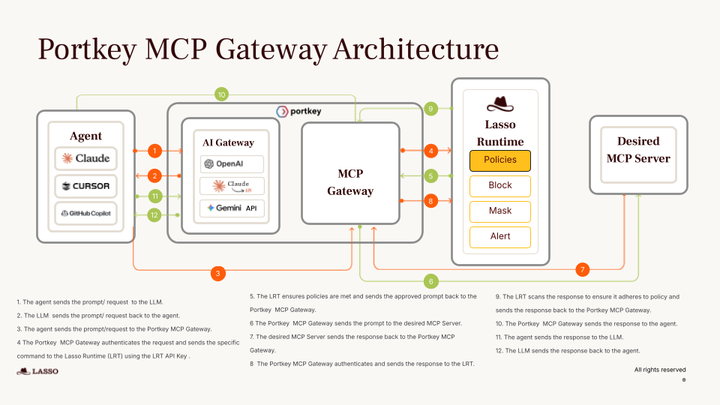
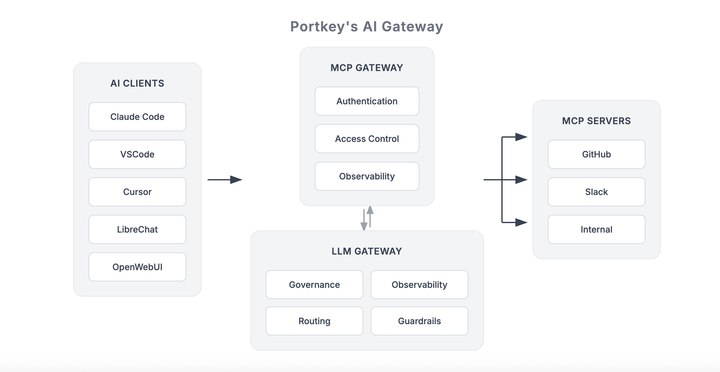
This is exactly the gap Portkey’s MCP Gateway is designed to close. It introduces OAuth 2.1 and configurable authentication on top of MCP servers, enforces role-based access control at the organization, team, and user level, applies runtime policies like PII redaction, and logs every tool invocation for auditability. If a tool isn’t explicitly approved in the gateway, agents simply can’t call it.
Why MCP uses more tokens, and how to fix it
One of the first things teams notice when experimenting with MCP is higher token usage and slower responses compared to classic RAG pipelines.
This happens for two main reasons:
- First, many early MCP tools return broad or loosely filtered pages, which forces the model to read far more text than necessary.
- More importantly, MCP introduces schema overhead. Every tool comes with detailed JSON definitions explaining inputs, outputs, and capabilities, and these are injected into the system prompt on every request. As teams connect multiple MCP servers in production, this background prompt keeps growing, raising the token cost before the user even asks a question.
To solve this, the industry is moving toward "Tool Search," a pattern where models dynamically fetch only the specific tool schemas they need on-demand. Anthropic reports this "just-in-time" loading can reduce initial context overhead by 85% for large tool libraries.
Luckily, this is an implementation choice, not a fundamental limitation of MCP.
Teams can wrap efficient vector retrieval inside MCP tools themselves. A search_documentation tool can embed the query, run semantic search internally, and return only the most relevant chunks, preserving RAG-like efficiency while using MCP’s standardized interface.
Building a hybrid RAG and MCP architecture
In production, the most reliable AI systems combine RAG and MCP so models can first understand the rules of the business and then safely act inside live systems. The simplest and most effective place to start is a sequential RAG-then-MCP workflow.
Imagine a customer asking for a refund:
- The agent retrieves the company’s refund policy using RAG, pulling the relevant section that explains eligibility, time limits, and dollar thresholds. This grounds the model in the exact rules it must follow.
- Once the policy confirms the refund is allowed, the agent calls an MCP tool connected to the payments system to execute the refund in real time.
- The agent responds to the customer, confirming the transaction and citing the original policy document that justified the decision.
This pattern mirrors how human support teams operate and provides both accuracy and accountability.
As systems mature, teams typically adopt one of four hybrid patterns – let’s unpack them:
The sequential approach is easier to debug, cheaper to run, and safer from a governance standpoint. Build RAG and MCP pipelines independently first, add strong observability around both LLM calls and tool invocations, and only move to parallel or iterative patterns when clear performance or UX gains justify the added complexity.
For organizations running MCP in production, Portkey’s MCP Gateway acts as a secure reverse proxy between the model and MCP servers. It provides a single control plane for authentication, access control, and end-to-end tracing across both LLM requests and tool calls.
🌟 One team reported consolidating 14 separate authentication mechanisms into the gateway, enabling key rotation and role-based access control without touching their core agent logic.
Your next step: Production-grade AI
By now, it’s clear that RAG isn’t going away, and MCP isn’t here to replace it. Mature production systems use both, with strong governance layered on top.
Remember, the right design starts by answering a few practical questions:
- What types of data does your AI need to work with? Long-form documentation and policies naturally favor RAG, while live system state and structured records point toward MCP.
- What actions must the agent perform? If everything is read-only, RAG may be sufficient. The moment workflows, updates, or transactions are involved, MCP becomes essential.
- What controls exist over the tools your models can call, and how are those calls audited? Equally important is governance.
- Does each request map to a real user with scoped permissions, or does your MCP server operate behind a single high-privilege key? You need to consider identity.
For teams bringing MCP into production, Portkey’s MCP Gateway adds centralized authentication, access control, and observability across MCP servers, without changing agent or server code.
Start securing your AI action layer with Portkey’s MCP Gateway today!
Frequently asked questions
Will MCP make RAG obsolete?
No, RAG remains a specialized retrieval layer for grounding models in external knowledge. In many modern systems, MCP tools actually call RAG-style retrieval internally to fetch relevant documents before taking action. The two approaches compose naturally rather than compete, with RAG handling knowledge access and MCP orchestrating interaction with live systems.
What limitations of RAG does MCP address?
RAG is fundamentally read-only and best suited for static or slowly changing content like documentation and policies. It cannot write data, trigger workflows, or query real-time system state.
MCP fills this gap by enabling live API calls, database queries, and action execution. At the same time, MCP does not replace what RAG does best. It does not solve semantic retrieval over long-form text, which remains RAG’s core strength.
Why frame this as “knowing more” versus “doing more”?
RAG focuses on retrieving information so the model can ground its responses in a factual context. It helps the system know what is true according to your knowledge base.
MCP focuses on execution, allowing models to interact with external systems such as processing payments, updating records, or checking live inventory. The framing comes from IBM Technology and reflects architectural roles rather than a value judgment about either approach.
Is anything better than RAG for knowledge retrieval?
Fine-tuning is excellent for teaching models specialized language, tone or reasoning patterns, such as legal formatting or clinical communication style. However, it performs poorly for storing and updating factual knowledge and is prone to hallucinations when recalling specifics. For verifiable, updatable fact retrieval with citations, RAG remains the gold standard in production systems.
Ship Faster with Portkey
Everything you need to build, deploy, and scale AI applications