
Why Multi-LLM Provider Support is Critical for Enterprises
Learn why enterprises need multi-LLM provider support to avoid vendor lock-in, ensure redundancy, and optimize costs and performance.
You've built your AI application around a single language model provider. Everything's running smoothly until... the provider has an outage, raises prices, or falls behind competitors in key features you need. Not a fun situation, right?
More companies are realizing that relying on just one LLM provider is like having a single point of failure in their system. While working with multiple providers might sound like extra work upfront, it's becoming a smart strategy that can save you headaches (and money) down the road.
Let's look at why spreading your LLM dependencies across different providers isn't just about playing it safe - it's about setting your AI projects up for long-term success.
The risks of vendor lock-in
Your LLM strategy is like an investment portfolio. Would you put all your money into one stock? Probably not. The same goes for LLM providers.
Price changes can force unexpected migrations. When your sole provider adjusts their pricing model, you might need to refactor large portions of your codebase to accommodate a new provider's API structure. This isn't just about higher costs - it's about engineering time spent on migration instead of building new features.
Each provider has distinct technical capabilities. GPT-4 might handle certain tasks differently than Claude. Being locked into one provider means your code can't adapt to use the best model for each specific function.
System reliability becomes a single point of failure. During provider outages, your application falls back to degraded or non-functional states. Without the ability to route requests to alternate providers, you can't maintain service reliability guarantees to your users.
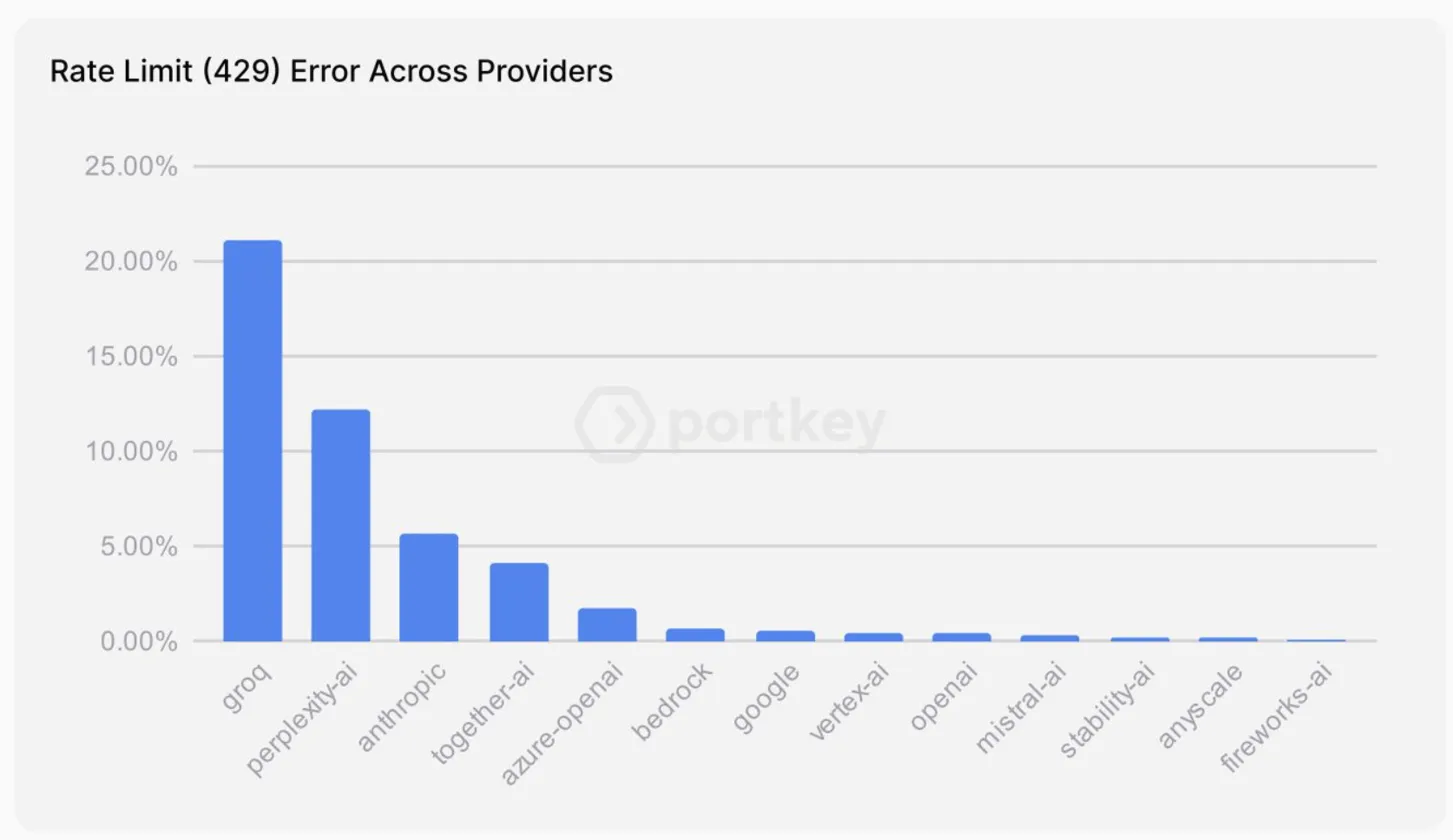
Service interruptions are a real pain point. When your provider goes down for maintenance or has technical issues, your entire AI pipeline stops. Without redundancy, you're stuck waiting for them to come back online. Looking at real-world data, rate limit errors (HTTP 429) vary significantly across providers - from over 20% for some to under 1% for others.
Rate limits hit harder than you'd expect. Even established providers can throttle requests during peak times or when you hit API quotas. The graph shows why having fallback options matters - when one provider starts throwing 429s, you need the ability to route traffic elsewhere. Some teams learn this the hard way after their first major outage.
Having a single point of failure means your application's reliability is only as good as your provider's uptime. Engineering around these constraints often requires building complex caching and fallback systems that wouldn't be necessary with a multi-provider approach.
Building Redundancy into Your LLM Architecture
Let's get practical about implementing fallback strategies for your AI applications. When your primary provider fails, your system needs to keep running - not throw errors at your users.
The key is designing your abstraction layer right. Your application code shouldn't need to know which provider actually handled the request. This means building a common interface that normalizes responses across providers and handles their specific quirks.
For example, if OpenAI is down, your system can automatically route traffic to Claude or another alternative. Your users won't notice the switch, and your application stays responsive.
Yes, building this takes extra development time and adds complexity to your system. You'll need to maintain multiple API integrations and handle differences between providers. But in production environments where reliability matters, this overhead isn't optional - it's a necessary investment in your system's resilience.
Optimizing costs across LLM providers
Cost optimization with LLMs isn't just about finding the cheapest provider - it's about matching the right provider to each task. Different providers price their models differently for various capabilities. Understanding these differences lets you build a smarter spending strategy.
Take text classification tasks. Many of these work perfectly well with simpler, cheaper models. No need to pay premium rates when a basic model handles the job reliably. On the other hand, tasks like complex reasoning or specialized code generation might justify the cost of more expensive models.
This is where a multi-provider setup helps. You can route basic, high-volume tasks to cost-effective providers while reserving premium services for jobs that truly need them.
Running thousands of simple classification requests? Use a budget-friendly option. Need a detailed analysis of complex technical documents? Switch to a more capable model.
Performance benchmarking for providers
Different LLM providers have different strengths - that's just how it is. Some models nail creative writing while others excel at structured data analysis.
Building a benchmarking system into your architecture lets you make these decisions based on data, not guesswork. Track success rates, output quality, and consistency across different task types. When providers release updates or new models, you can quickly evaluate if they're worth integrating into your stack.
Take a look at the 2025 AI Infrastructure Benchmark Report here.
The goal isn't to find one "best" provider - it's to know which provider works best for each specific task in your application.
The need for a unified platform to manage multi-LLM setups
Let's talk about the practical side of running multiple LLM providers in production. While the benefits are clear, the technical challenges are real.
Each provider has their own API quirks. Building and maintaining these integrations takes significant engineering effort:
The monitoring challenge is another key issue. You need visibility into:
- Per-provider response times and error rates
- Token usage and costs across providers
- Request success rates by task type
- Security compliance across all integrations
Then there's compliance - each provider might have different data handling policies. You need to ensure all providers meet your security requirements, handle user data appropriately, and maintain audit logs. Managing this across multiple providers quickly becomes complex.
This is where using a unified platform makes sense. Platforms like Portkey handle the complexities of:
- One API endpoint for all providers
- Consistent security policies and logging
- Centralized monitoring and alerting
- Standardized error handling and retries
The platform approach means your team can focus on building features instead of managing infrastructure. You get multi-provider benefits without the operational overhead of building everything from scratch.
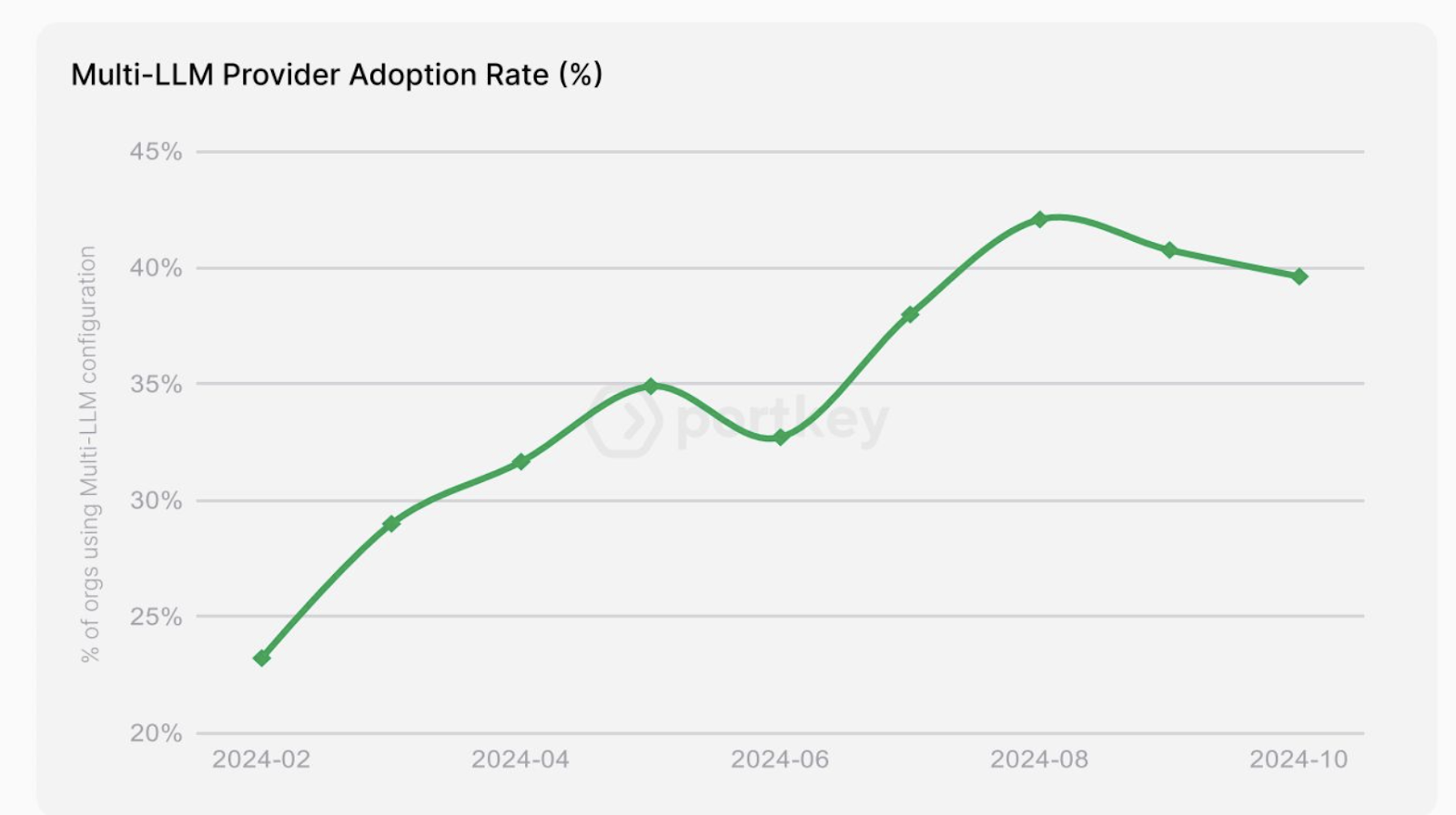
Building production AI applications isn't getting simpler. New models drop every month, existing providers keep updating their offerings, and pricing models shift. The key to building sustainable AI applications? Don't lock yourself into a single provider's ecosystem.
Tools like Portkey's AI gateway help manage this complexity, but the fundamental architectural decisions are up to you. The time you invest in building flexible, provider-agnostic systems today will pay off as the LLM landscape continues to evolve.
Start testing multiple providers in your development environment. See how different models handle your specific use cases. Build the infrastructure to measure what matters for your application. Your future self will thank you.
