
OpenCode: token usage, costs, and access control
A practical guide to managing OpenCode token usage, costs, and governance in shared or production environments.
OpenCode is an open-source, terminal-first AI coding assistant designed to work directly inside a developer’s existing workflow.
OpenCode supports agent-based interactions, long-running tasks, and complex instructions that can span large context windows. It is built to be model-agnostic, allowing users to choose between multiple providers or local models, depending on their setup.
OpenCode's model-agnostic approach makes it easy to experiment. Local model support also allows OpenCode to run in environments where calling external APIs is not always desirable.
As usage grows, this flexibility introduces practical challenges. Each provider has its own pricing, rate limits, reliability characteristics, and failure modes. Without a central way to manage these differences, teams often end up handling provider-specific logic and configuration on their own.
Managing OpenCode at scale with an AI gateway
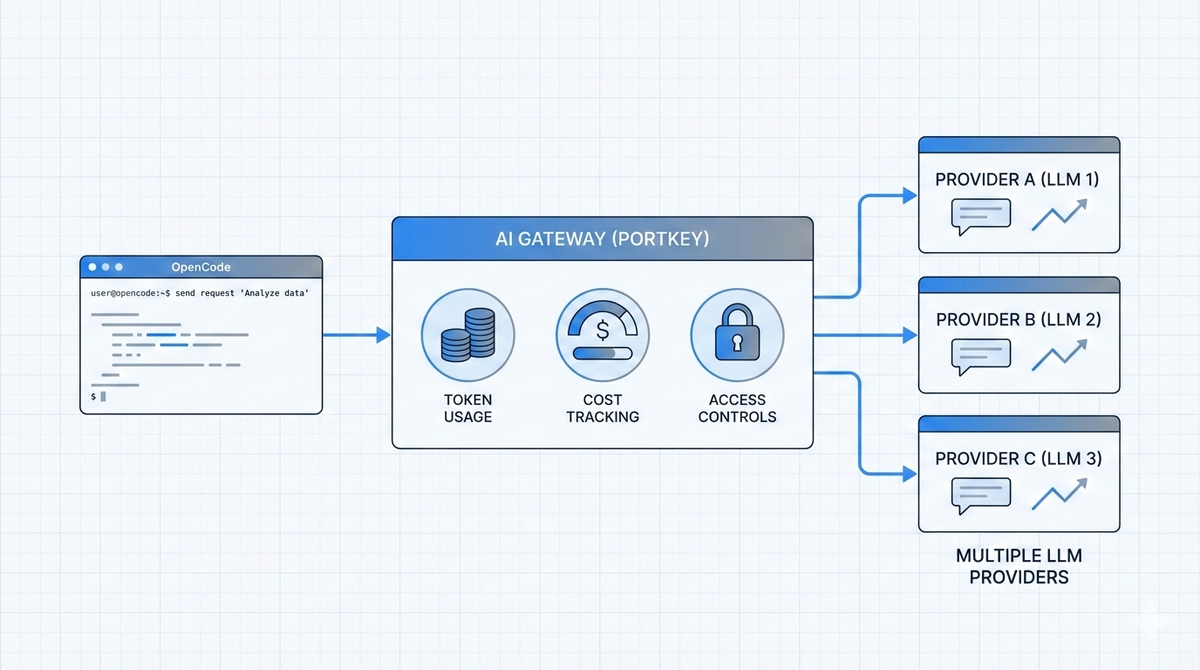
An AI gateway acts as a control layer between OpenCode and the underlying model providers. Instead of OpenCode calling providers directly, requests flow through a single, centralized layer that standardizes how usage is tracked, observed, and governed. This allows teams to keep OpenCode flexible and developer-friendly while adding the operational structure needed at scale.
Check out our detailed documentation to learn more.
Monitoring OpenCode token usage and costs
Agent retries, tool calls, and background execution can significantly increase spend, especially when teams are experimenting or running OpenCode continuously. Without a central layer, cost data remains fragmented across provider dashboards, making it difficult to attribute usage to specific projects or users.
By routing OpenCode’s model calls through an AI gateway like Portkey, teams get unified cost visibility across all providers and models. OpenCode token usage can be tracked at the request, model, and workspace level, enabling clearer attribution, budget enforcement, and early detection of unexpected spikes, all without changing how developers interact with OpenCode.
Getting observability into OpenCode workflows
As OpenCode is used for longer-running and more complex agent workflows, understanding what actually happened during an execution becomes increasingly important. When something fails or produces an unexpected result, developers need visibility into each step along the way.
An AI gateway provides a centralized observability layer for these workflows. When OpenCode requests pass through Portkey, teams can capture structured logs, request metadata, model usage, and latency metrics in one place. This makes it easier to trace agent behavior end to end, compare model performance, and diagnose failures without relying on scattered provider dashboards.
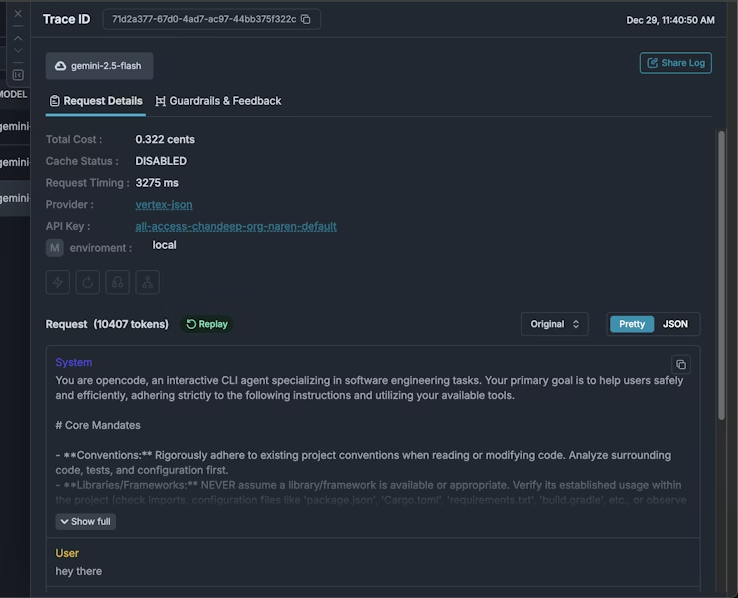
With observability in place, OpenCode remains lightweight at the developer level, while teams gain the visibility needed to operate it reliably in shared or production environments.
Adding guardrails to OpenCode usage
OpenCode is intentionally permissive. Agents are designed to explore, execute tools, and operate with minimal friction. This works well in individual workflows, but it introduces risk once OpenCode is shared across teams or connected to production systems.
Common risk areas include unrestricted tool usage, accidental destructive actions, and expensive model calls triggered by retries or exploration. Without explicit boundaries, it becomes difficult to control what agents are allowed to do and under what conditions.
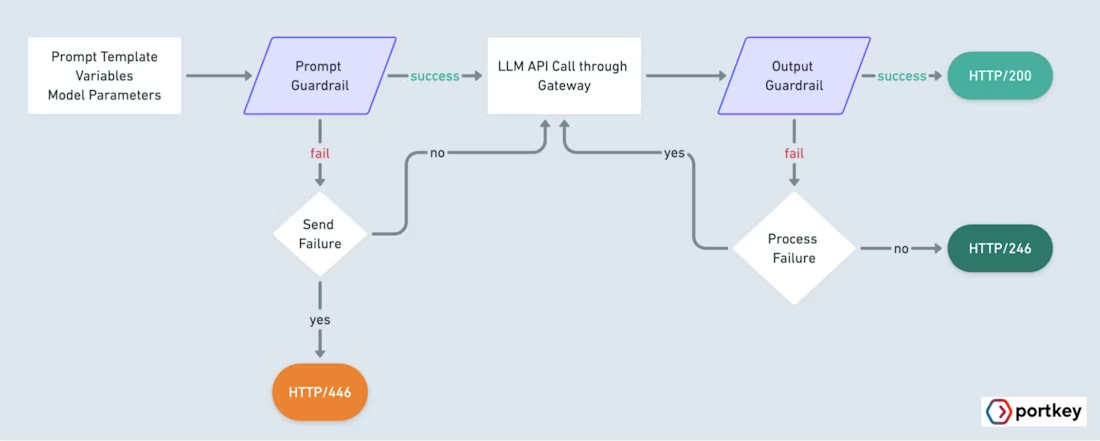
There is also a second layer of risk: LLM outputs themselves. As OpenCode is used to generate code, documentation, scripts, or configuration changes, teams need confidence that outputs meet certain standards. This can include preventing unsafe code patterns, blocking sensitive data leakage, enforcing formatting or policy constraints, or catching hallucinated or non-compliant responses before they are acted on.
An AI gateway adds a policy layer without changing how OpenCode itself works. By routing requests through Portkey's AI Gateway, teams can enforce guardrails around model usage, tools, and request patterns. Policies can define which models are allowed, restrict certain tools, and block unsafe or unintended operations before they reach a provider.
Access control, budgets, and limits for OpenCode
When OpenCode is adopted across teams, governance becomes a practical requirement. Not every user, agent, or workflow should have unrestricted access to every model or unlimited usage.
With Portkey, governance is applied at the platform layer rather than inside OpenCode itself.
Access control: Portkey allows teams to define which models and providers OpenCode can access, and under what conditions. Access can be scoped by workspace, project, or environment.
Budgets: Budgets can be applied at the team or workspace level to prevent runaway spend. Budgets make experimentation safer by enforcing hard or soft limits without requiring developers to manually track usage or rely on provider-specific dashboards.
Rate limits and usage caps: Enforce rate limits and request caps to protect downstream providers and prevent accidental overload. This is especially important for agent-driven workflows that may retry or fan out requests automatically.
Conclusion
OpenCode provides a flexible, agent-driven interface for working with modern language models. Its model-agnostic design and terminal-first approach make it a strong fit for developers who want control over how AI fits into their workflows.
As usage grows beyond individual experimentation, operational requirements become unavoidable. Access control, budgets, limits, and governance are needed to keep usage predictable and manageable without constraining developers.
By using Portkey alongside OpenCode, teams can add these controls at the platform layer. OpenCode remains unchanged for developers, while organizations gain the structure required to run it safely and sustainably in shared or production environments.
If you're looking to add this to OpenCode or other AI tools, book a demo with us!
