MCP tool discovery for autonomous LLM agents A concise summary of the MCP-Zero paper, explaining how active tool discovery enables scalable, autonomous LLM agents while reducing context overhead.
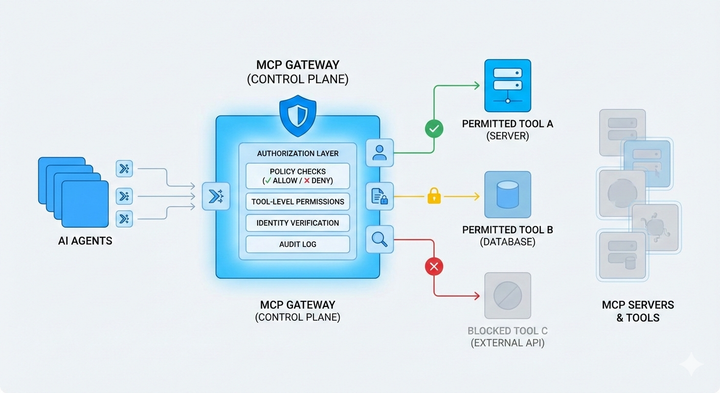
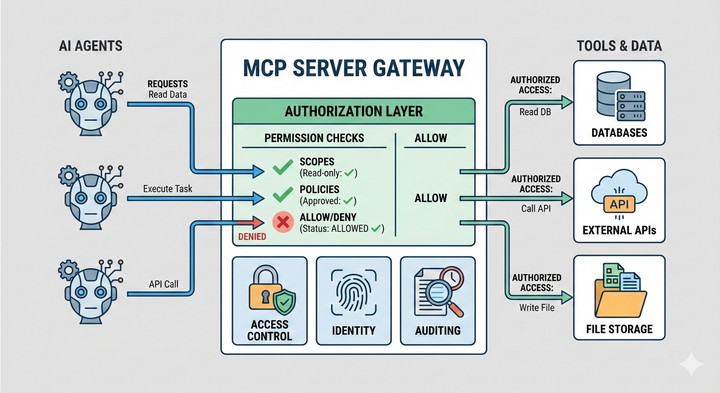
Enterprise MCP access control: managing tools, servers, and agents Learn how MCP access control works and how enterprises can govern MCP tools and agents safely in production environments.
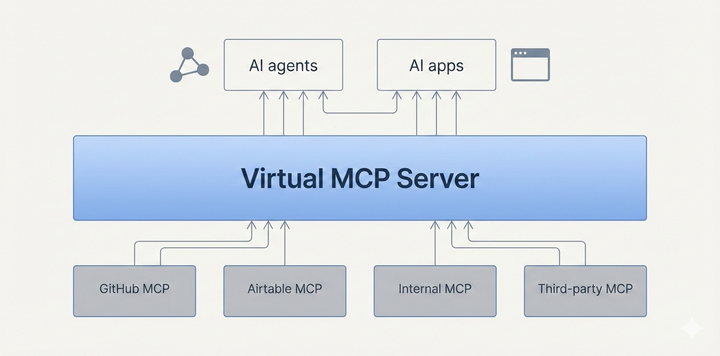
What is a virtual MCP server: Need, benefits, use cases As teams use more MCP servers, virtual MCP servers help simplify provisioning by combining tools into a single interface. See how they help, and use cases.
Understanding MCP Authorization Learn why MCP authorization matters, how access is enforced at the server boundary, and best practices for securing MCP in production environments.
How an AI gateway improves AI app building See how how an AI gateway improve building AI apps acting as a control layer between AI apps and model providers for routing, governance, and observability.
MCP primitives: the mental model behind the protocol If you’ve looked at MCP servers or examples, you’ve probably seen terms like resources, tools, prompts, and roots show up repeatedly. Those aren’t implementation details. They’re the primitives MCP is built around. Understanding these primitives makes it easier to design MCP servers, reason about agent behavior,
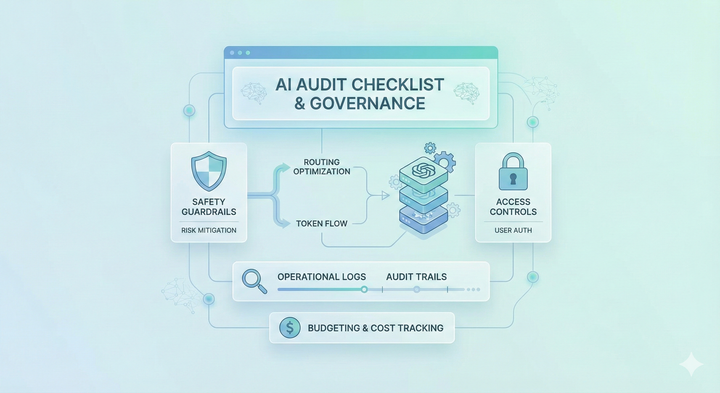
AI audit checklist for internal AI platform & enablement teams A practical AI audit checklist for platform teams to evaluate access controls, governance, routing, guardrails, performance, and provider dependencies in multi-team, multi-model environments.