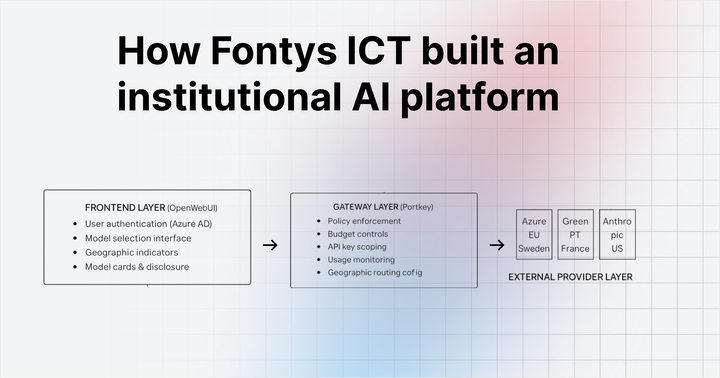
Rate limiting for LLM applications: Why it matters and how to implement it
Your team launches a new LLM-powered feature. Early tests look promising, but as usage grows, token consumption spikes. GPU queues begin to fill, response times increase, and users start seeing HTTP 429 errors.
AI rate limiting governs how requests and tokens flow through the LLM infrastructure. By controlling token throughput, request frequency, and tenant quotas, platforms can prevent runaway workloads and keep GPU resources available for all users.
LLM applications make traffic unpredictable
LLM workloads are far less predictable than traditional APIs. Depending on prompt length, context windows, and generated output, a single LLM request can consume thousands of tokens. Without guardrails, token consumption quickly becomes unbounded.
In production environments, token-heavy prompts monopolize GPU inference time and force smaller requests to wait in the queue. Before long, operations stall due to resource starvation, unexpected billing spikes, and degraded SLAs.
Here are a few aspects that make LLM traffic inherently unpredictable:
- Probabilistic outputs: Unlike deterministic APIs, LLMs generate variable-length responses for similar inputs, making token consumption and latency difficult to forecast.
- Multi-step and agent-driven workflows: A single user action can trigger multiple model calls through retrieval, tool use, or chained prompts, creating bursty traffic patterns.
- Provider limits and cascading failures: LLM providers enforce tokens-per-minute (TPM) and requests-per-minute (RPM) limits, and exceeding these thresholds leads to throttling or 429 errors that can cascade across dependent systems.
These behaviors make rate limiting essential for protecting system reliability, not just controlling cost. Without rate limiting, spikes in one workload can saturate shared resources, causing latency, timeouts, and system-wide reliability issues.
Rate-limiting strategies for LLM applications
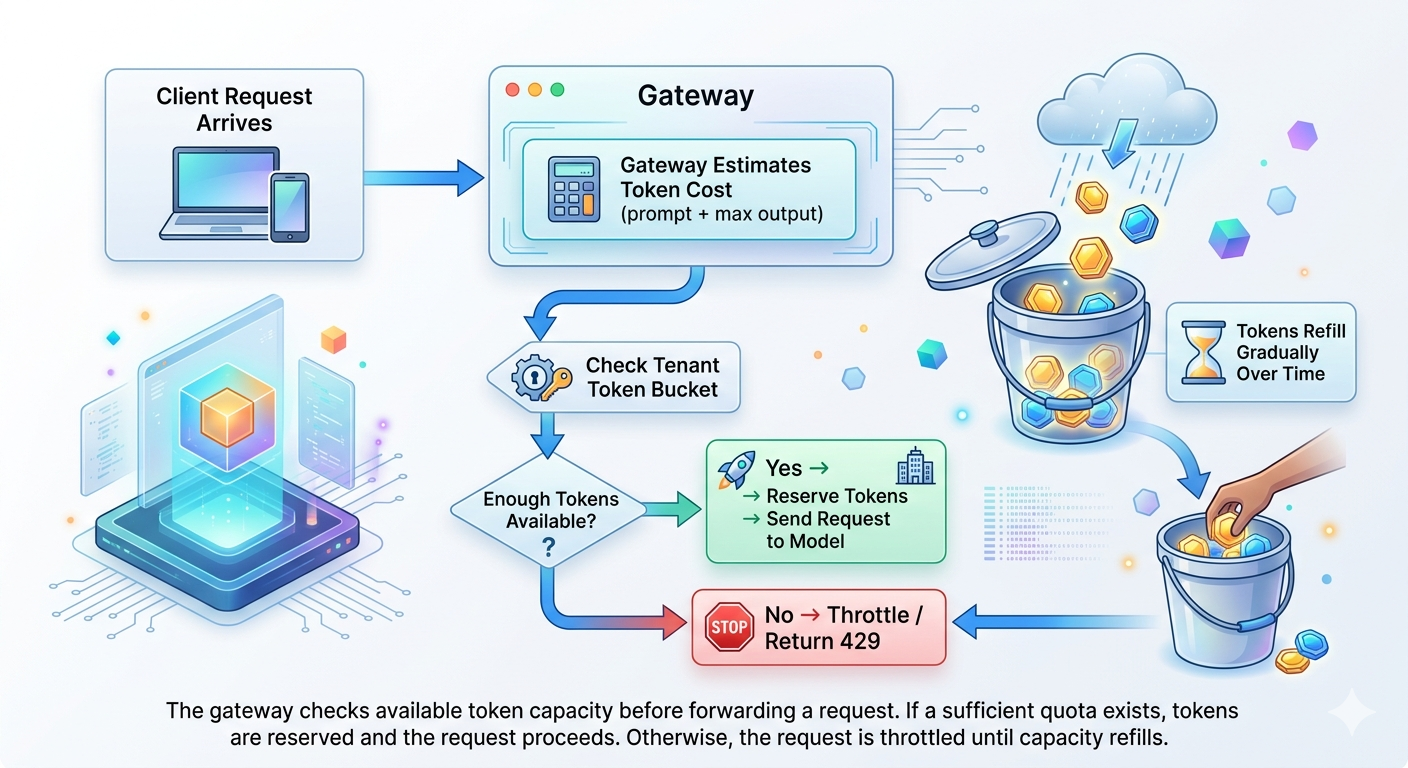
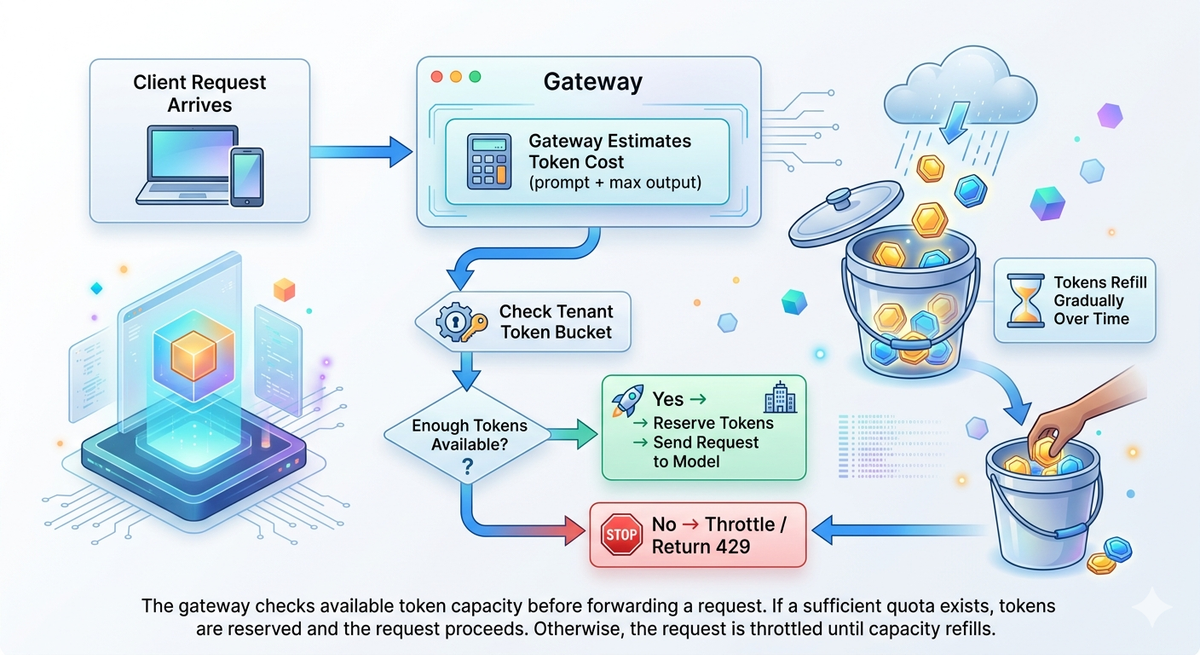
In reality, prompt sizes and output lengths vary widely. One request might consume 200 tokens while another consumes 4,000. The fluctuations could create 5×–20× swings in GPU demand, destabilizing capacity planning and increasing latency.
In practice, LLM systems rely on regulating both request volume and token consumption while ensuring usage stays within infrastructure and provider limits. To design production-grade LLM rate limiting, you need token-based, request-based, and cost-based controls that align traffic with both compute capacity and budget constraints.
Request-based limits
Most providers enforce request-based limits measured as requests per minute (RPM), hour, or day. RPM limits protect infrastructure from sudden request floods caused by retries, traffic spikes, or misconfigured clients, making them useful for controlling concurrency and gateway load rather than actual compute usage.
Token-based limits
Token-based limits control how much model computation occurs by enforcing tokens per minute (TPM) or tokens per day. Since tokens directly map to compute usage and cost, TPM limits are the primary mechanism for managing GPU capacity, large prompts, and multi-step agent workloads.
Cost and usage limits
Cost and usage limits enforce budget ceilings by tracking cumulative token consumption over daily or monthly periods. Once usage crosses defined thresholds, requests are throttled or blocked, preventing unexpected spend spikes from batch jobs, agent loops, or runaway workloads.
Time-window limits
Time-window limits enforce usage across multiple durations, such as per-minute limits for burst control and per-day limits for overall usage caps. Combining short and long windows helps smooth traffic spikes while keeping total consumption within predictable limits.
Per-provider limits
Developers building LLM agents frequently run into provider rate limits as usage scales. Enforcing provider-specific TPM and RPM limits prevents upstream throttling and failed requests.
Per-team and per-application limits
Per-team or per-application limits allocate independent TPM, RPM, and budget quotas across tenants. This prevents any single workload from consuming shared capacity and ensures fair usage across multiple teams, environments, or customer-facing applications.
Implementing rate-limiting using an AI gateway
In multi-provider environments, managing rate limits separately across each service quickly becomes difficult, leading to inconsistent enforcement and policy drift.
To apply AI rate limiting effectively, you need standardized enforcement, followed by an intelligent workflow after token limits are hit.
Instead of managing policies separately across infrastructure layers, teams can adopt a unified AI gateway to define token and request limits onceand enforce them uniformly across all LLM traffic.
The control plane centralizes traffic governance for LLM infrastructure. It manages rate limits, routing policies, token quotas, and observability from a single layer rather than distributing these responsibilities across individual gateways.
Here’s where a gateway-based approach enables consistent AI rate limiting:
- Providers, applications, and workloads: Unified platforms define and enforce TPM and RPM limits across multiple model providers and application entry points. Gateways apply standardized rate-limit policies to both user-facing requests and batch traffic, eliminating policy drift and removing the need for per-provider configuration.
- Users, teams, and API keys: Through identity-level limits and quotas, compute workloads and consumption can be controlled and isolated. Gateways assign each user, team, API key, and virtual key an independent TPM, RPM, and usage limits, preventing any single tenant or key from impacting shared infrastructure.
Portkey’s AI Gateway acts as the control plane where rate limits are defined once and enforced across providers, applications, and users. Teams can define token-aware configurations and policies once and enforce them consistently across providers and clusters, reducing duplicated configuration and operational overhead.
Fallback routing
Gateway routing policies also improve availability when rate limits are reached. If a primary model approaches its token quota or latency threshold, traffic can automatically be routed to a fallback model. For example, requests targeting GPT-4 can shift to another provider when token capacity is exhausted, maintaining availability while staying within global rate-limit policies.
Track rate-limit and usage metrics
Rate limiting becomes actionable only when systems capture the right operational signals. Metrics such as HTTP 429 response counts, token spend per tenant, and quota utilization percentages show how close workloads are to their limits and where traffic pressure originates.
These signals quickly identify abnormal usage patterns. A sudden spike in token spend from a single tenant, for example, may indicate a misconfigured agent loop or runaway prompt cycle. Likewise, a surge in 429 responses often signals that traffic is repeatedly hitting defined capacity thresholds.
Standardize monitoring dashboards
Metrics become useful only when they are clearly visualized. Centralized dashboards provide a real-time view of how traffic interacts with rate-limit policies across tenants, models, and endpoints.
Alert thresholds should align with budget and governance policies. When token consumption approaches defined limits, alerts notify engineering teams before costs escalate or service quality degrades. Exportable audit logs can also support compliance reporting under frameworks such as GDPR and HIPAA.
The future: Unified control planes for AI infrastructure
AI infrastructure is moving toward integrated policy engines that manage rate limits, quotas, and routing across providers. These AI rate-limiting systems will broker capacity across models, shift workloads to optimize cost, and enforce policies consistently across multi-cloud deployments.
Platforms like Portkey are built around this model, helping engineering teams run reliable LLM infrastructure at scale, while maintaining centralized governance.
Request a demo to see the Portkey control plane in action.
FAQs
How do token and request limits differ?
Request limits control how many API calls can occur within a time window, such as RPM. Token limits control how much model computation occurs by restricting TPM. LLM applications need both because a single request may consume thousands of tokens.
What happens when LLM rate limits are exceeded?
When LLM rate limits are exceeded, requests are throttled, delayed, or rejected, typically returning HTTP 429 errors. Upstream providers may block further requests until quotas reset. This can increase latency, cause request failures, and trigger cascading issues across dependent services if traffic continues without backoff or retry control.
How do you prevent 429 errors in LLM apps?
Prevent 429 errors by enforcing TPM/RPM before hitting provider thresholds. Use backoff and retry strategies, queue or stagger batch workloads, and distribute traffic across providers. Applying rate limiting at the gateway ensures requests are regulated before reaching upstream limits.
Should rate limiting be implemented at the app or gateway level?
AI-rate limiting should be implemented at the gateway level for centralized control across providers, users, and applications. This ensures consistent enforcement and avoids duplicated logic. Application-level limits can complement this for specific use cases, but gateways provide a single point of policy enforcement.
Does rate limiting slow down responses?
Rate limiting itself adds minimal latency, typically a few milliseconds at the gateway. Any delay usually comes from controlled throttling or queuing when limits are reached. This trade-off prevents system overload and ensures stable response times across all users under varying traffic conditions.