Why reliability in AI applications is now a competitive differentiator
Reliability is now a competitive edge for AI applications. Learn why outages expose critical gaps and how AI gateways and model routers build resilience, and how Portkey unifies both to deliver cost-optimized, reliable AI at scale.
AI has moved far beyond pilots and proofs of concept. Today, it underpins critical applications across industries, from powering customer experiences to automating internal workflows. As AI becomes foundational to business operations, expectations around its reliability have shifted.
The cost of downtime is no longer theoretical. Recent outages at major providers like OpenAI, Google Cloud Platform, and Cloudflare have shown how dependent organizations are on external AI services, and how vulnerable they become when those services fail. A single failure can disrupt thousands of customer interactions, stall operations, and erode user trust.
As per one of the predictions stated by Gartner® in their research, “by 2028, 70% of engineering leaders will treat reliability as a core differentiating factor in choosing AI model providers.”
The reliability gap in today’s AI stack
Despite the growing reliance on AI, most organizations still build on infrastructure that isn’t designed for enterprise-grade reliability.
The problem is compounded by weak guarantees. According to Gartner, “Cloud hyperscalers commit to a monthly uptime SLA of only 99.9% (or higher) uptime for generative AI services, while their traditional enterprise offerings, like databases and storage, promise 99.99% or higher.”
That small difference translates into significantly more downtime over the course of a year.
This creates a critical gap: AI applications are expected to perform like any other mission-critical system, but the underlying services often lack the same level of reliability. And for organizations relying on a single model or provider, the risk is amplified. A failure at the provider level cascades into a failure at the application level, exposing businesses to single points of failure.
Why reliability is becoming a differentiator
As AI adoption scales, reliability is shaping competitive outcomes. Organizations that deliver consistently available, predictable AI experiences gain trust from users and confidence from internal stakeholders. Those that falter risk losing both.
Performance benchmarks or model features alone will not win contracts; enterprises will increasingly prioritize platforms that can withstand outages, recover quickly, and maintain service continuity under pressure.
Reliability also directly affects adoption. Business leaders will hesitate to scale AI applications across mission-critical functions if they cannot be assured of stability. Conversely, when engineering teams can point to built-in resilience and clear recovery strategies, they unlock confidence to expand use cases.
In short, reliability has moved from being a backend quality measure to a front-line business advantage. The ability to guarantee uptime and resilience is quickly becoming a deciding factor in the success of AI applications.
Resilience strategies for AI applications
Building reliability into AI applications requires more than just monitoring uptime. It means designing for failure and implementing safeguards that keep systems functional even when providers falter.Here are several strategies that engineering teams can adopt:
- Caching: During outages or high-latency periods, cached responses can continue serving users with slightly degraded but still functional experiences. For example, a product recommendation engine can fall back to a cached “most popular” list if the AI-driven system is unavailable.
- Asynchronous processing for non-real-time tasks:Not every AI task needs to happen instantly. Reports, document analysis, or email summaries can be queued and processed asynchronously, reducing the strain on real-time services and lowering the impact of transient failures.
- Graceful degradation of functionality: Applications should degrade in predictable, user-friendly ways. A chatbot might display default help options during an outage, rather than going offline entirely.
- Multiprovider and multimodel redundancy: The most effective long-term strategy is avoiding reliance on a single provider or model. AI gateways and model routers make this possible by routing traffic across multiple providers, ensuring continuity even when one fails.

By combining these techniques, engineering leaders can move from a reactive stance to a proactive design mindset where resilience is a first-class principle.
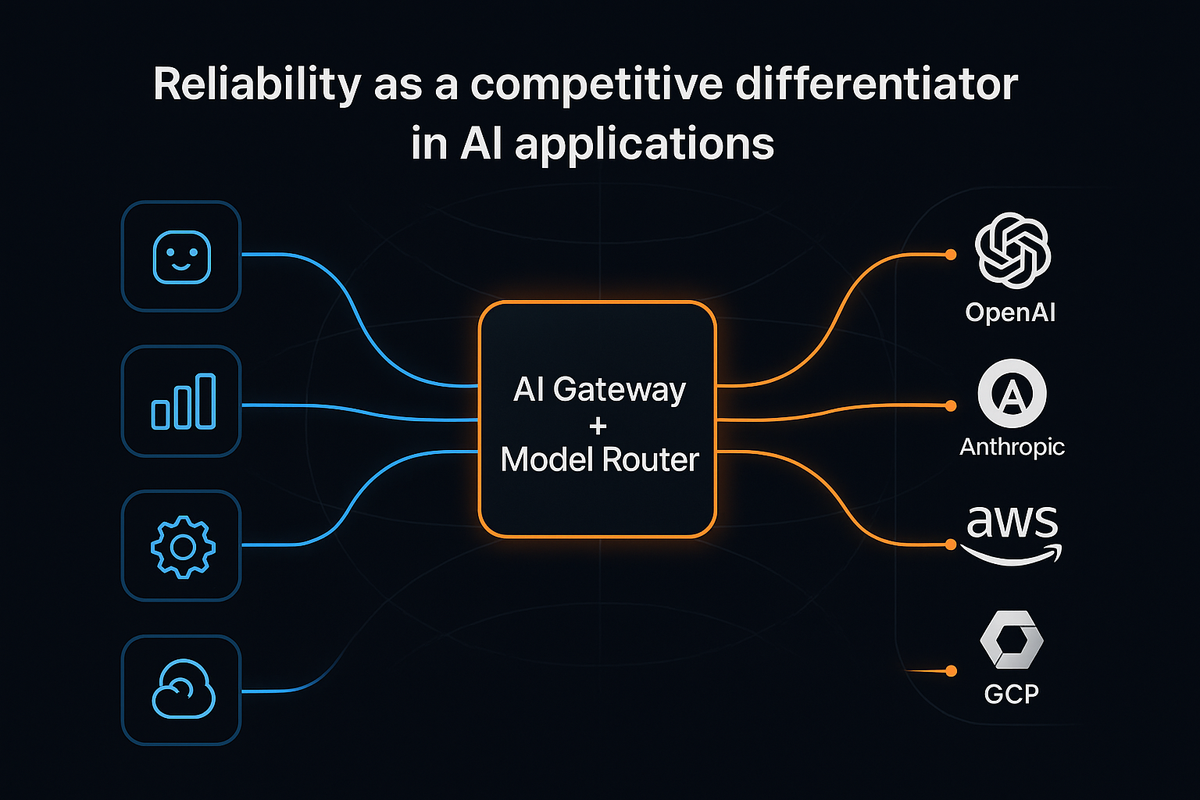
AI gateways and model routers — enablers of reliability
Resilience strategies provide a foundation, but organizations need infrastructure that can enforce them consistently across applications. This is where an AI gateway + model router play a pivotal role. Together, they act as intelligent control layers that decouple applications from individual providers, reduce risk, and improve continuity.
AI gateways centralize reliability and governance. They:
- Distribute traffic intelligently across providers with dynamic load balancing.
- Provide automated failover, rerouting traffic to backup providers during outages.
- Offer observability into key metrics like latency, token usage, and error rates, enabling teams to detect and address problems before they impact users.
- Enforce enterprise guardrails like quotas, caching, and policy-based usage limits, which prevent runaway costs while ensuring uptime
Model routers address reliability at the model level. They:
- Route queries to the most suitable models based on latency, complexity, and cost.
- Enable fallback to alternative models when a primary model fails or slows down.
- Help eliminate single points of failure by supporting multiprovider and multimodel redundancy.
- Optimize resource allocation, directing simple queries to lightweight models and reserving expensive, reasoning-intensive models for complex tasks

Source: Gartner, Optimize AI Cost and Reliability Using AI Gateways and Model Routers, Manjunath Bhat, Andrew Humphreys, 12 August 2025
Together, gateways and routers shift reliability from being a reactive scramble to a built-in design principle. They ensure that AI applications can survive outages, deliver consistent performance, and maintain user trust, even in unpredictable conditions.
How Portkey brings AI gateways and model routers together
Portkey combines AI gateways and model routers into a single platform designed for production-grade AI. This dual capability means organizations don’t need to stitch together multiple tools or compromise between reliability and cost optimization.
With Portkey, engineering and platform teams get:
- Unified routing layer — Dynamically switch between providers and models, balancing accuracy, latency, and cost.
- Centralized governance — Set quotas, rate limits, and usage policies across all applications, preventing outages and uncontrolled spend.
- Automated failover — Reroute traffic instantly when a provider goes down, ensuring continuity of service.
- Observability built in — Track latency, error rates, token usage, and costs across providers, all in one place.
- Caching and cost control — Reduce token usage and improve responsiveness by serving frequent queries from cache.
By integrating gateway and router functionality, Portkey allows enterprises to treat reliability as a built-in feature of their AI stack rather than an afterthought. Instead of designing ad hoc resilience patterns for each application, teams can standardize on Portkey as the backbone of their AI infrastructure.
Reliability as the new baseline
The era of treating AI outages as “acceptable” growing pains is coming to an end. As organizations expand AI from experiments to mission-critical applications, resilience and uptime will be table stakes.
Gartner predicts, “By 2028, 70% of software engineering teams building multimodel applications will use AI gateways to improve reliability and optimize costs, up from 10% in 2025.”
In this future, enterprises that continue to depend on single providers or lack failover strategies will fall behind, while those that build resilience into their infrastructure will move faster and earn greater trust from users.
Reliability is no longer a differentiator only for hyperscalers, it’s becoming the responsibility of every engineering leader.
Platforms like Portkey make this shift possible by embedding redundancy, observability, and governance into the AI stack. The winners in this new landscape will be the teams that treat reliability not as insurance, but as a core design principle.
To improve reliability of your AI platforms and apps, book a demo with Portkey today!