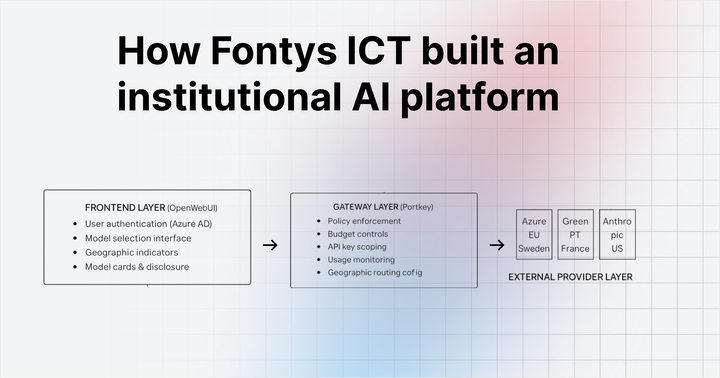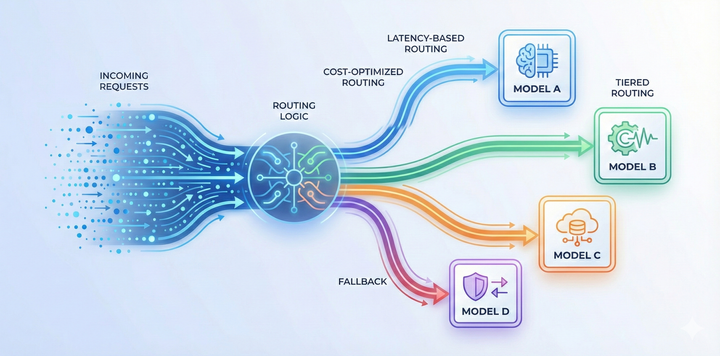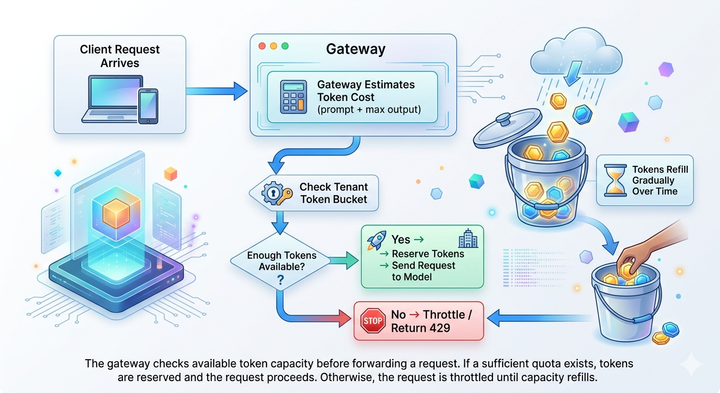
Rate limiting for LLM applications: Why it matters and how to implement it
Your team launches a new LLM-powered feature. Early tests look promising, but as usage grows, token consumption spikes. GPU queues begin to fill, response times increase, and users start seeing HTTP 429 errors.
AI rate limiting governs how requests and tokens flow through the LLM infrastructure. By controlling token