
GPT-4 is Getting Faster 🐇
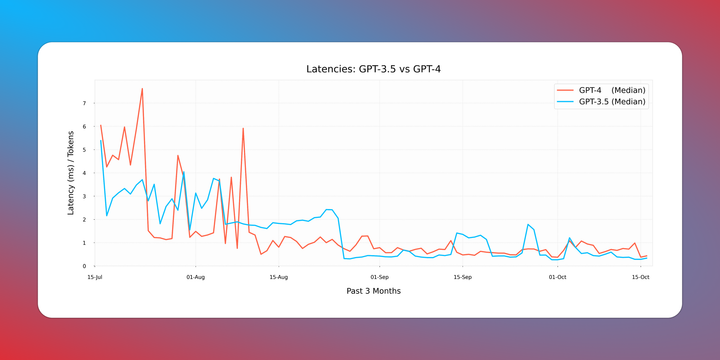
Over the past few months, we've been keenly observing latencies for both GPT 3.5 & 4. The emerging patterns have been intriguing.
The standout observation? GPT-4 is catching up in speed, closing the latency gap with GPT 3.5.
Our findings reveal a consistent decline in
