Scaling production AI: Cerebras joins the Portkey ecosystem Cerebras inference is now available on the Portkey AI Gateway,bringing ultra-fast performance with enterprise-grade governance and control.
Simplifying LLM batch inference LLM batch inference promises lower costs and fewer rate limits, but providers make it complex. See how Portkey simplifies batching with a unified API, direct outputs, and transparent pricing.
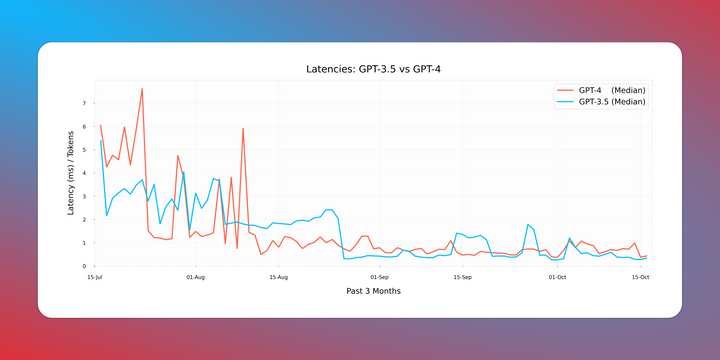
GPT-4 is Getting Faster 🐇 Over the past few months, we've been keenly observing latencies for both GPT 3.5 & 4. The emerging patterns have been intriguing. The standout observation? GPT-4 is catching up in speed, closing the latency gap with GPT 3.5. Our findings reveal a consistent decline in GPT-4
⭐ Semantic Cache for Large Language Models Learn how semantic caching for large language models reduces cost, improves latency, and stabilizes high-volume AI applications by reusing responses based on intent, not just text.
LoRA: Low-Rank Adaptation of Large Language Models - Summary The paper proposes Low-Rank Adaptation (LoRA) as an approach to reduce the number of trainable parameters for downstream tasks in natural language processing. LoRA injects trainable rank decomposition matrices into each layer of the Transformer architecture, greatly reducing the number of trainable