Role-based access control (RBAC) for LLM applications Learn how Role-Based Access Control (RBAC) helps enterprises build AI applications, control access, ensure compliance, and scale securely.
What is AI interoperability, and why does it matter in the age of LLMs Learn what AI interoperability means, why it's critical in the age of LLMs, and how to build a flexible, multi-model AI stack that avoids lock-in and scales with change.
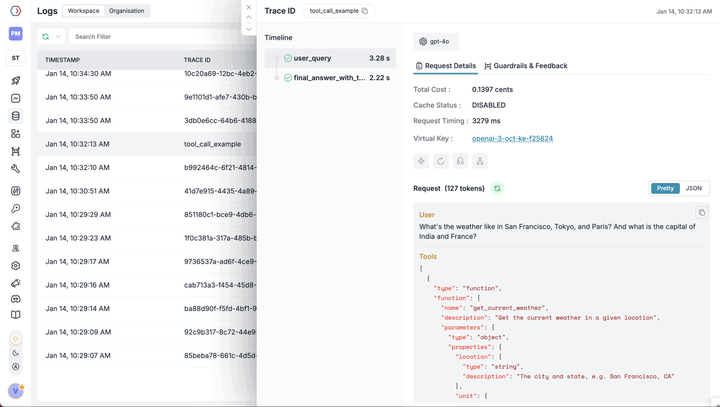
How LLM tracing helps you debug and optimize GenAI apps Learn how LLM tracing helps you debug and optimize AI workflows, and discover best practices to implement it effectively using tools like Portkey.
LLM cost attribution: Tracking and optimizing spend for GenAI apps Learn how to track and optimize LLM costs across teams and use cases. This blog covers challenges, best practices, and how LLMOps platforms like Portkey enable cost attribution at scale.
Scaling and managing LLM applications: The essential guide to LLMOps tools Learn how to scale your AI applications with proven LLMOps strategies. This practical guide covers observability, cost management, prompt versioning, and infrastructure design—everything engineering teams need to build reliable LLM systems.
What a modern LLMOps stack looks like in 2025 Learn what a modern LLMOps stack looks like in 2025 the essential components for building scalable, safe, and cost-efficient AI applications.
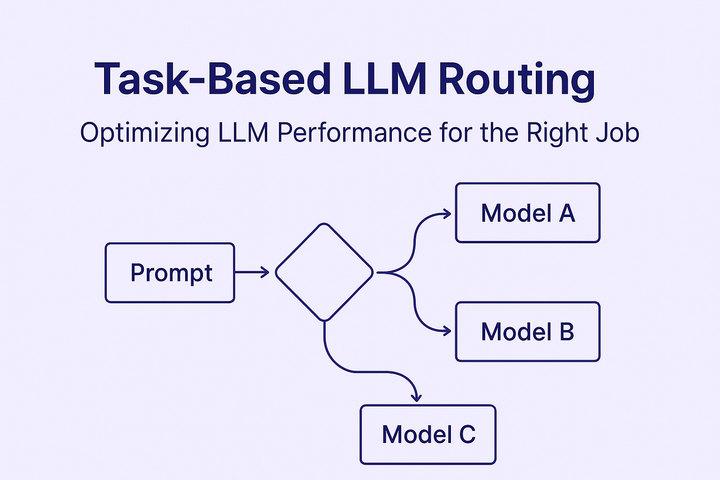
Task-Based LLM Routing: Optimizing LLM Performance for the Right Job Learn how task-based LLM routing improves performance, reduces costs, and scales your AI workloads