Understanding RAG: A Deeper Dive into the Fusion of Retrieval and Generation

Retrieval-Augmented Generation (RAG) models represent a fascinating marriage of two distinct but complementary components: retrieval systems and generative models. By seamlessly integrating the retrieval of relevant information with the generation of contextually appropriate responses, RAG models achieve a level of sophistication that sets them apart in the realm of artificial intelligence.
How does RAG work?
Imagine you're planning a trip to a foreign country and you want to learn about its culture, history, and local attractions. You start by consulting a well-informed travel agent (retrieval system) who has access to a vast library of guidebooks and travel articles. You provide the agent with your interests and preferences (query), and they sift through their resources to find the most relevant information.
Once they've gathered all the necessary details, they pass them on to a talented tour guide (generative model) who crafts a personalized itinerary tailored to your tastes.
This itinerary seamlessly blends the information provided by the travel agent with the guide's own expertise, resulting in a comprehensive and engaging travel plan.
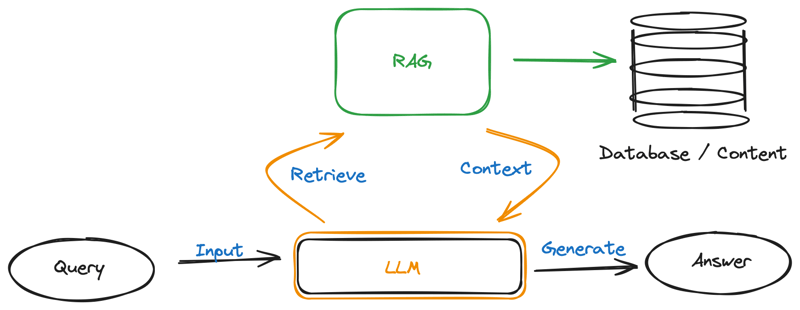
Architecture of RAG Models
Let's break down the architecture of RAG models into its constituent parts:
Query Processing: This is where the journey begins. When a query is submitted to a RAG model, it undergoes a process of analysis and interpretation to discern the context and intent behind it.
Like a human travel agent, who collects more information about weather, location, budget, food choice from a traveller.
Document Retrieval: Once the query has been processed, the retrieval system springs into action. Drawing upon its extensive database of documents, the retrieval system embarks on a quest to find the most pertinent information related to the query. It sifts through mountains of data, searching for nuggets of knowledge that will help illuminate the user's inquiry.
Just as a travel agent understands the traveller's needs and preferences to recommend the best itinerary, RAG carefully analyses the user's query to identify their intent and picks the most appropriate places of attraction, city under given budget guidelines.
Response Generation: With the relevant information in hand, it's time for the generative model to work its magic. Like a skilled storyteller weaving together threads of narrative, the generative model synthesizes the retrieved information with its own internal knowledge to craft a response that is both coherent and contextually appropriate. Drawing upon its vast reservoir of linguistic patterns and semantic understanding, the model generates text that is not only factually accurate but also engaging and insightful.
Finally, A good travel agent is like a personal concierge, working tirelessly to gather all the necessary details and craft the perfect itinerary for their clients. Just as a generative model creates a cohesive story, a travel agent artfully combines flights, hotels, and activities to create a seamless and enjoyable travel experience.
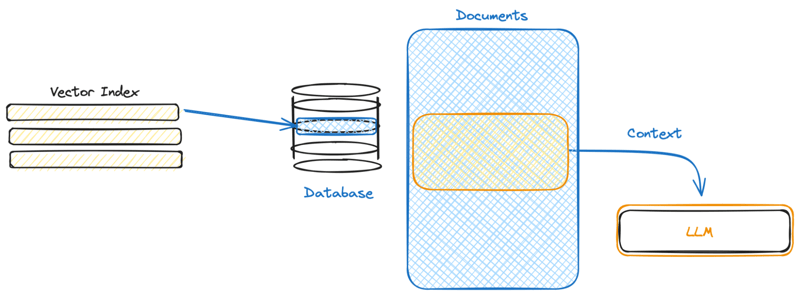
Bringing it All Together
What makes RAG models truly remarkable is the synergy between their retrieval and generation components. Like two dancers moving in perfect harmony, these components work together to create responses that are greater than the sum of their parts. By leveraging the precision and depth of retrieval systems alongside the creativity and fluency of generative models, RAG models are able to tackle a wide range of tasks with unparalleled sophistication and accuracy.
Platforms for Building RAGs: Exploring the Options
When it comes to building Retrieval-Augmented Generation (RAG) models, developers have access to a variety of platforms and tools that streamline the development process and offer integrated environments for experimentation and deployment. There are LLM platforms, Chunker & Retrievers, Complete Frameworks.
Let's take a closer look at some of the prominent platforms available:
OpenAI: OpenAI offers an API that provides access to powerful generative models, including GPT-3, which can be seamlessly integrated with retrieval systems to build RAG models. The API provides developers with a simple and intuitive interface for interacting with state-of-the-art language models, making it an ideal choice for building RAG applications.
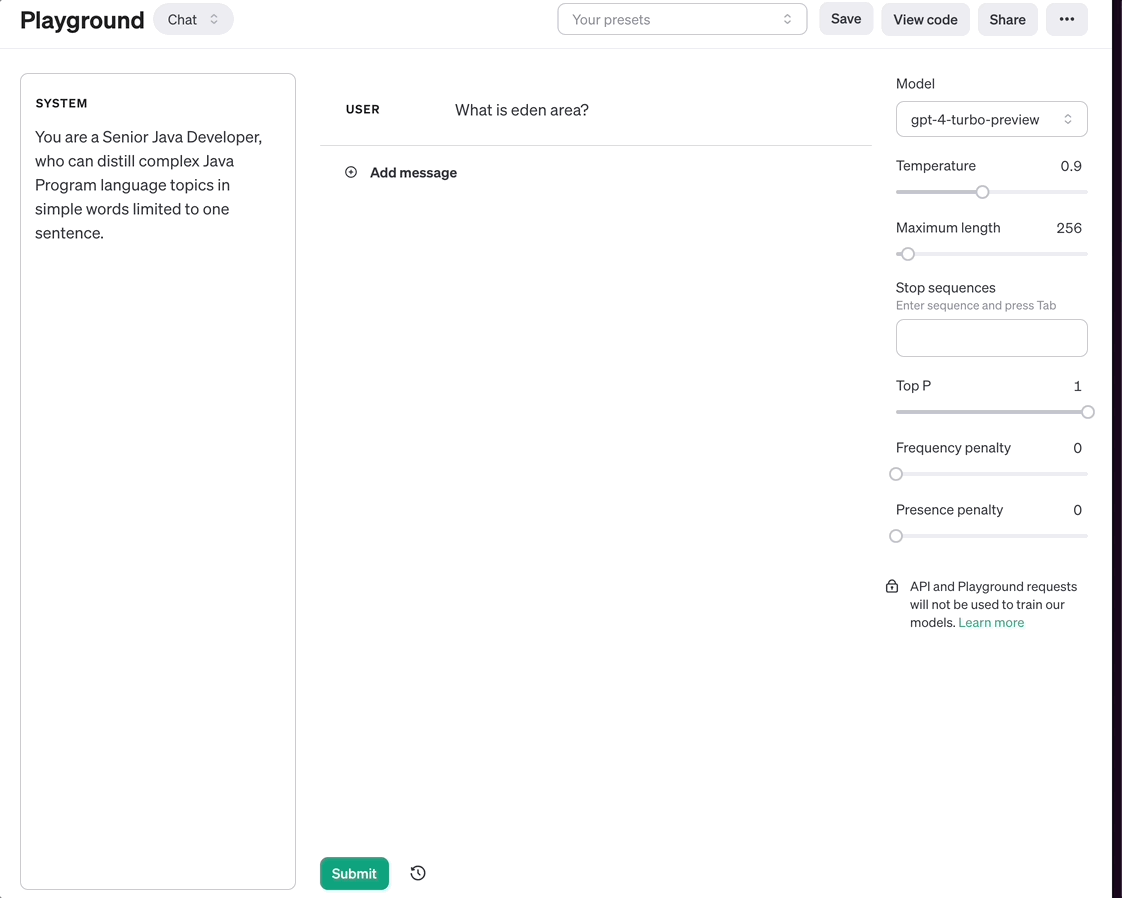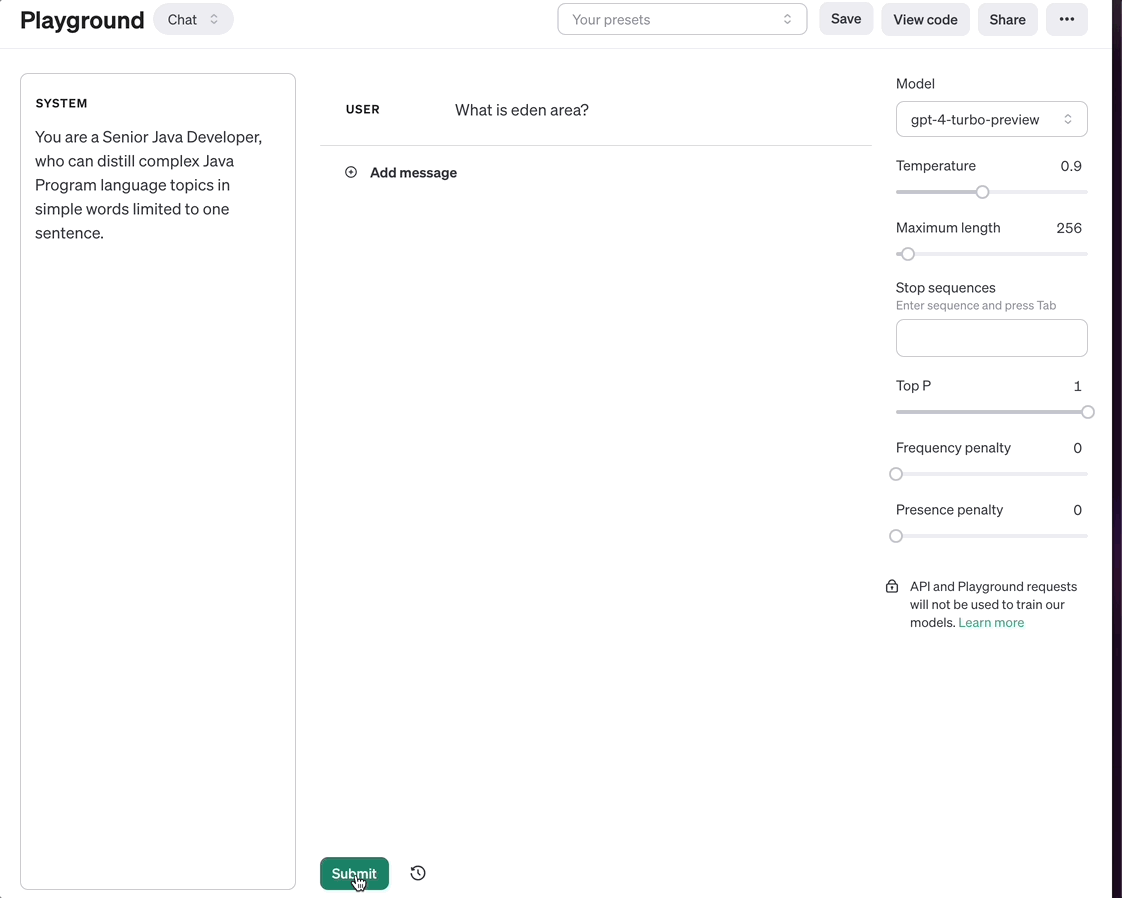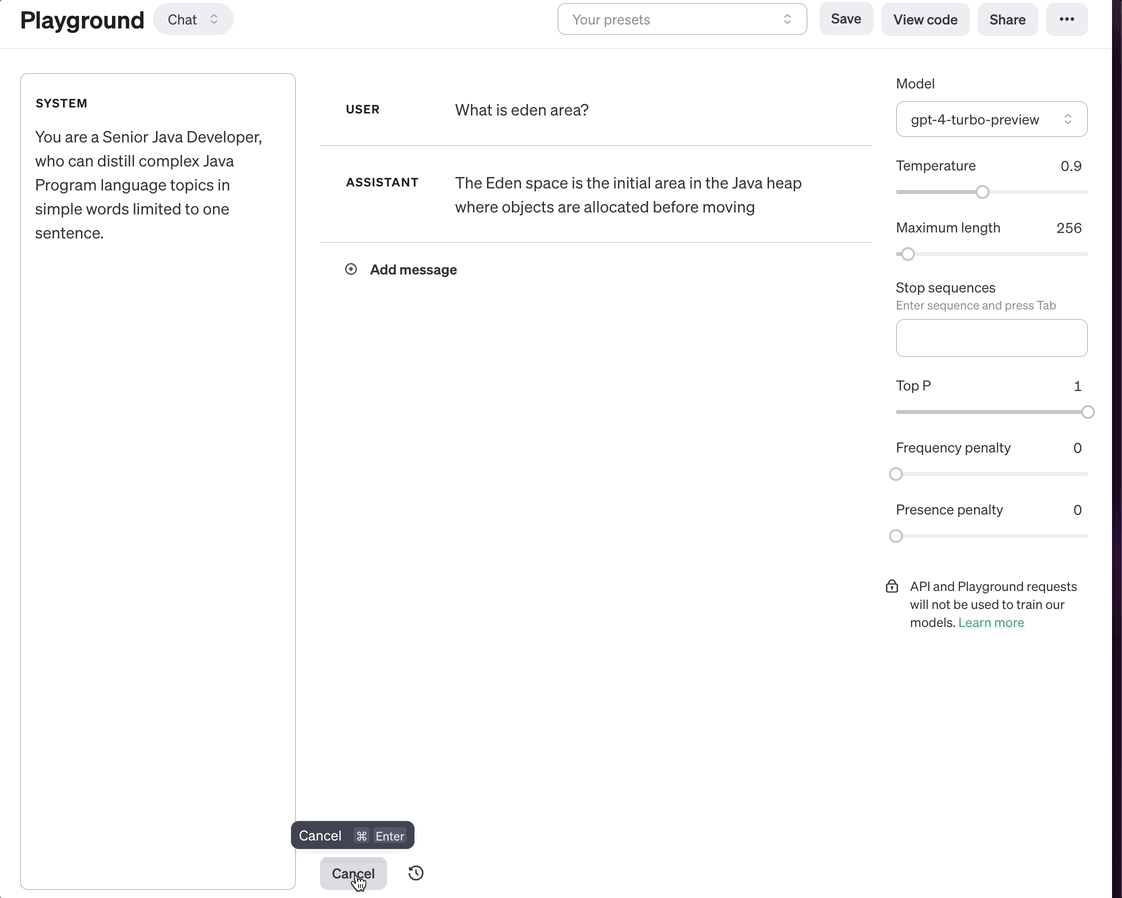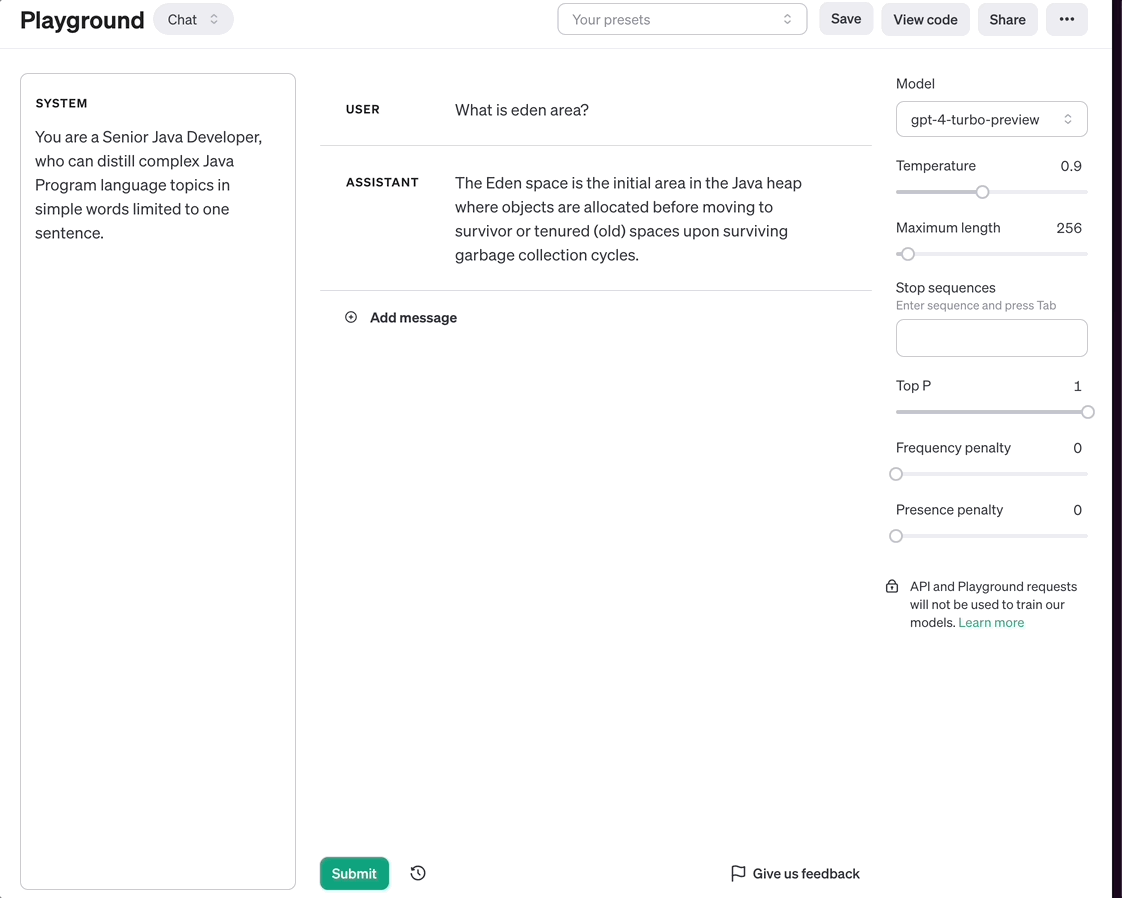
Hugging Face's Transformers Library: Hugging Face's Transformers library is a comprehensive toolkit for natural language processing tasks, including support for RAG models. The library offers pre-trained models, fine-tuning capabilities, and a wide range of utilities for working with transformer-based architectures. With its extensive documentation and active community support, Hugging Face's Transformers library is a popular choice among developers for building RAG models.
LangChain and LlamaIndex: These open-source libraries were founded in late 2022 and have gained significant adoption in the RAG community. LangChain and LlamaIndex provide developers with tools and frameworks for building RAG pipelines, including support for retrieval systems, generative models, and prompt engineering. With their modular design and emphasis on flexibility, LangChain and LlamaIndex offer developers the freedom to customize and experiment with different components of RAG models.
OpenLLaMA and Falcon: These are other open-source options for building RAG models. OpenLLaMA and Falcon provide developers with access to a range of tools and resources for constructing RAG pipelines, including support for vector search engines, language models, and integration with external data sources. With their active development communities and growing ecosystems, OpenLLaMA and Falcon offer promising opportunities for building and deploying RAG applications.
Conclusion
In conclusion, Retrieval-Augmented Generation (RAG) models represent a groundbreaking approach to natural language processing that combines the power of retrieval systems and generative models to produce highly sophisticated and contextually relevant responses.
That being said, deploying LLMs and building RAGs in production is not easy, we at Portkey are building a community for Generative AI builders. Come join us and let us know your problems. You can also showcase your GenAI product or solution to our user community.