

What is AgentOps?
A single LLM call has one shape: request in, response out. You log it, alert on it, and move on. Agents break that model.
They make multiple LLM calls per task, decide which tools to invoke, and chain those decisions across steps to reach an outcome. By the time something goes wrong, the run has already burned tokens, broken an SLA, or violated a policy several steps back.
AgentOps closes this gap, giving teams visibility and control over agent behavior in production.
What is AgentOps?
AgentOps is the operational layer for AI agents in production. It sits above your model and tool infrastructure and gives teams the controls they need to operate autonomous systems safely and predictably.
Agents use LLMs to plan, reason, and call tools on their own. Their behavior is multi-step, dynamic, and shaped by the model's choices at runtime, not by a fixed control flow you wrote in advance. Operating that kind of system requires more than per-request monitoring.
In practice, AgentOps covers a specific surface:
- Tracking: Every LLM call and tool invocation is logged, in the sequence of execution.
- Monitoring: Token usage, latency, and spend are tracked per LLM call.
- Enforcement: Guardrails and policy controls during runtime
- Routing and rate limiting: Applied at the agent level, so you control which models an agent can use and how much it is allowed to consume.
Each of these capabilities exists because agent behavior produces challenges that request-scoped infrastructure was never designed to handle. Now, let’s walk through what those challenges actually look like.
Why you need a dedicated operational layer
- Reasoning errors compound across steps. Reasoning errors compound across steps. A model produces an intermediate output that is slightly off. The next step treats it as ground truth. Most pipelines give you the final output and nothing else. There's no record of what the model received at step two, what it returned, or what structural assumptions the next step inherited. By the time the final output is wrong enough to notice, you have no way to work backwards.
- Tool calls fail silently. A tool returns an ambiguous schema, a partial result, or a stale value. The agent retries, reframes its plan, or proceeds with bad data. There is no HTTP-level failure. The only signal is a degradation in the agent's information state, and that only shows up if you are tracking tool interactions across the run.
- Cost and latency accumulate invisibly. The agent fails to satisfy a goal and re-invokes the same step. Or it succeeds, but spans dozens of legitimate steps that together run through a daily budget or a P95 SLA. Every individual call is valid. Per-request rate limits do nothing, because they have no awareness of cumulative run state.
- Policy violations emerge from sequences. Policy violations emerge from sequences, not requests. Tool A is permitted. Tool B is permitted. Reading sensitive data with one and writing it to an external system with the other is a compliance violation, but no single request breaks policy. The violation only becomes legible when you can see the whole run: which tools were called, in what order, with what inputs and outputs. Without a complete record of every agent action, there is nothing to audit and nothing to enforce against.
Every one of these requires something that holds context across the full agent run.
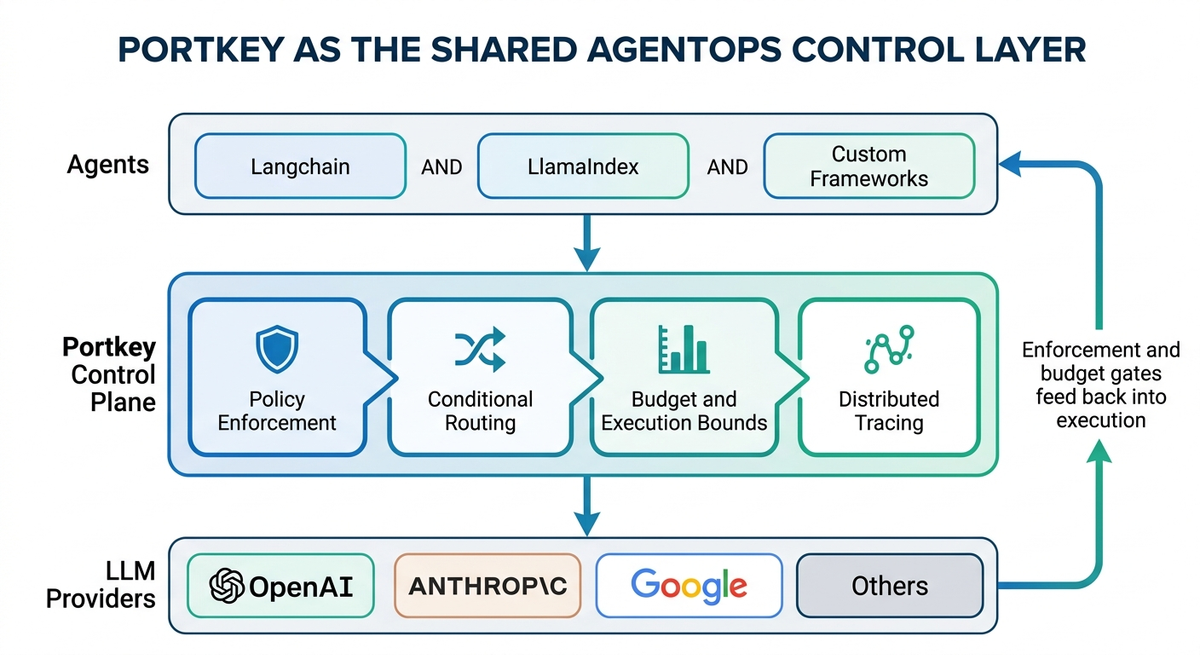
AgentOps for enterprises: Portkey as the shared control layer
Everything above applies to a single agent. Once you have multiple teams shipping agents independently, on different frameworks, with different model configurations, under different release cycles, the controls have to live in shared infrastructure, or they drift.
A guardrail update becomes a coordinated release across every agent that needs it. A new model gets adopted in one team's stack before security has evaluated it. There is no single place to ask what every agent in the org is currently doing, what it's spending, or whether it's behaving within policy.
The only way to avoid that drift is a control layer that every agent routes through.
Portkey's AI Gateway is built to be that shared layer. Because it sits in the path between every agent and the models it calls, its controls are enforced. Here's what that looks like in practice:
Agent Registry and virtual servers. Every agent is registered in a central registry and exposed via a Portkey-managed URL. Clients call that URL instead of the upstream agent directly. Swapping the underlying agent, rotating credentials, or revoking access happens at the registry, no client-side changes required.
Model Catalog for governed model access. Providers and models are managed centrally in the Model Catalog, credentials stored once, access provisioned per workspace. Budget caps, rate limits, and model allow-lists are set at the org or workspace level, so teams can only use what's been approved and can't exceed their spend limits regardless of how their agents are written.
Guardrails enforced at the gateway. Safety and compliance checks, input validation, output schema enforcement, PII detection, prompt injection scanning are configured once and applied to every agent that routes through the gateway. No per-agent implementation required.
Workspace-level spend controls. Budget caps and rate limits are set per workspace, so each team's agent spend is bounded independently.
Full run tracing across frameworks. Every agent interaction is logged as a structured trace, spans, tool calls, model inputs and outputs, regardless of whether the agent was built on LangChain, LlamaIndex, OpenAI Agents SDK, or an in-house framework. The framework is irrelevant. The gateway sees everything.
A2A protocol support. For multi-agent architectures using the A2A protocol, the gateway proxies agent-to-agent communication through the same control plane, same auth, same logging, same access policies.
What changes for you
Agents are not single LLM calls, and operating them like they are is what produces the failures that show up at 2 a.m. AgentOps is the layer that makes autonomous behavior visible and bounded, not a wrapper around your existing monitoring, but the place where enforcement actually lives.
The question for any team running agents in production is whether those controls are enforced through shared infrastructure or hoped for through per-agent configuration.
If you are working through that decision, the Portkey docs and GitHub repo are the fastest way to see how this works in practice, or book a demo to walk through it with the team.
FAQs
How is AgentOps different from DevOps and MLOps?
DevOps handles infrastructure automation. MLOps manages model training and deployment pipelines. AgentOps governs the runtime behavior of autonomous agents in production: their execution paths, tool usage, policy compliance, and cost across full runs.
Can AgentOps prevent runaway agent loops in production?
Yes. Execution bounds on token consumption, request count, and duration applied at the run level catch loops that per-request rate limits miss, because per-request limits have no awareness of cumulative session state.
Does AgentOps require a specific agent framework?
No. When implemented at the infrastructure layer, AgentOps is framework-agnostic. It controls the run regardless of whether you built the agent on Langchain, LlamaIndex, or a custom stack.
What agent metrics should teams track first?
Start with latency per run, token cost per session, and error rate. These surface the most common production issues, like cost overruns, slow workflows, and silent failures, before they compound into outages or budget incidents.