
What is AI lifecycle management?
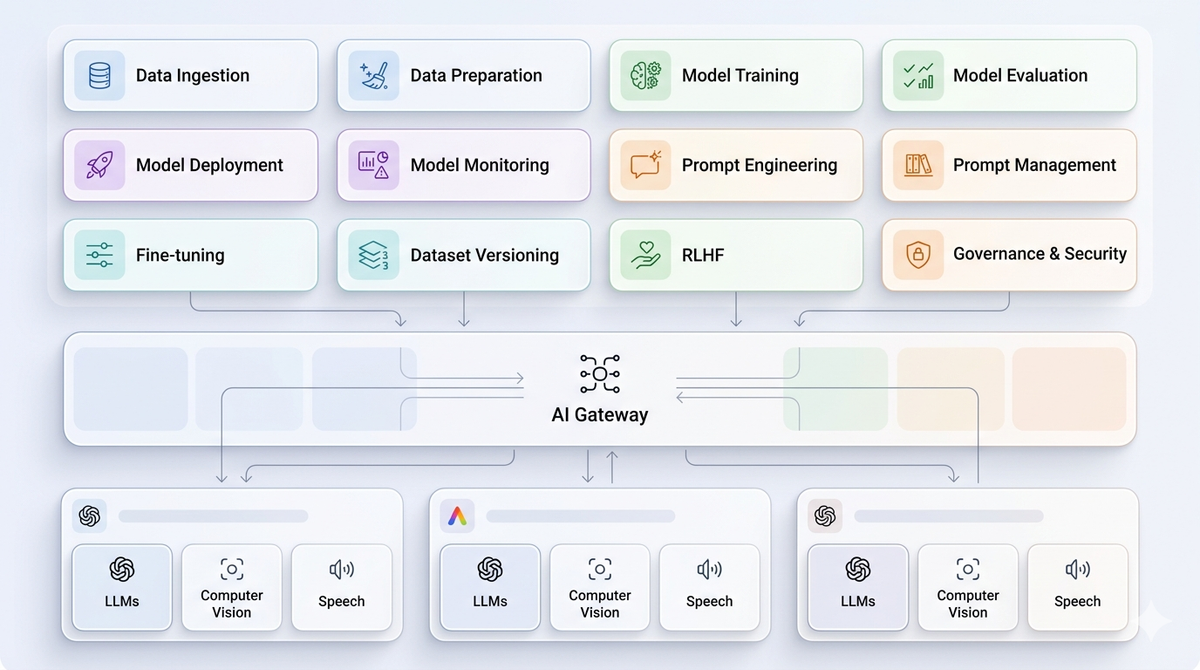
AI lifecycle management begins before any model is called. The first step is defining where AI should be used, what success looks like, and how risk is managed from the start.
For most teams, this means moving beyond isolated experiments to identifying repeatable, high-impact use cases, whether internal copilots, workflow automation, or customer-facing AI features. AI lifecycle management begins with defining the right use case and each use case should have clearly defined success metrics across quality, latency, cost, and adoption, so performance can be measured as systems scale.
Equally important is risk classification. Not all AI applications carry the same level of sensitivity. Internal productivity tools, for example, require different controls compared to systems handling user data or making critical decisions. Establishing this early helps determine the right level of governance, guardrails, and monitoring required downstream.
AI lifecycle management is the process of building, deploying, and continuously improving AI systems in production.
Data governance
AI systems are only as reliable as the data they operate on. Managing the data lifecycle is critical to ensuring outputs remain accurate, safe, and compliant over time.
This starts with controlled data access, defining what data can be used in prompts, which systems can access it, and how sensitive information (like PII) is handled. As AI usage scales across teams, enforcing consistent policies becomes essential to avoid leakage or misuse.
Equally important is data quality and consistency. Inputs to AI systems should be structured, validated, and, where necessary, filtered before reaching the model. This includes applying guardrails such as content filters, redaction, or transformation layers to standardize requests and responses.
Model selection and evaluation
Choosing the right model is not a one-time decision. It is an ongoing process of balancing quality, latency, and cost across different use cases.
Most teams start by testing a few models, but as AI usage grows, this quickly becomes harder to manage. Different tasks may require different models, some optimized for reasoning, others for speed or cost efficiency.
Evaluation plays a critical role here. This includes offline testing on curated datasets to benchmark performance, as well as online evaluation on live traffic to understand real-world behavior. Tracking outputs, comparing responses, and identifying regressions helps teams make informed decisions when switching or upgrading models.
Over time, models evolve, new providers emerge, and pricing changes. Treating model selection as part of the lifecycle allows teams to continuously optimize performance without disrupting production systems.
Prompt and agent management
Prompts and agents define how AI systems behave in production. Managing them as versioned, testable components is essential to maintaining consistency and control.
Prompts should not live inside application code. Instead, they need to be versioned, reusable, and independently updatable, so teams can iterate without redeploying entire systems. Even small changes in prompts can significantly impact output quality.
As systems evolve, many teams move from simple prompts to agents with tool-calling and multi-step reasoning. This introduces additional complexity, agents can behave non-deterministically, depend on external tools, and vary based on context. Managing this requires clear definitions of agent logic, tool access, and fallback behavior.
Guardrails also play an important role at this layer. Applying constraints on inputs and outputs helps ensure that prompts and agents operate within defined boundaries, especially in sensitive or user-facing scenarios.
Security and governance
As AI systems move into production, they need the same level of control and accountability as any other critical infrastructure.
This begins with access control i.e. defining who can use which models, tools, and data. Role-based access (RBAC), workspace isolation, and scoped permissions ensure that usage is intentional and contained, especially in larger organizations.
Equally important is cost and usage governance. AI workloads can scale quickly, making it essential to enforce budgets, rate limits, and usage policies at both the user and application level. This prevents unexpected spend while maintaining system stability.
Security also extends to policy enforcement and compliance. Guardrails help filter unsafe or non-compliant content, while audit logs provide a clear record of how AI systems are being used. For enterprise environments, alignment with standards like GDPR, SOC 2, and ISO requirements is often mandatory.
Deployment and routing
A critical part of AI lifecycle management is ensuring production reliability, scale, and constant change, without adding complexity to the application itself.
A unified gateway layer sits between applications and model providers, abstracting away provider-specific logic and enabling teams to manage AI traffic centrally. This allows applications to remain stable even as models, providers, or configurations evolve.
At the core of this is intelligent routing. Requests can be dynamically routed across models and providers based on latency, cost, quality, or availability. If a provider fails or degrades, automatic failover ensures continuity without requiring changes in application code.
Production reliability also depends on built-in controls like retries, timeouts, rate limits, caching, and load balancing. These mechanisms help reduce failures, smooth traffic spikes, and maintain consistent performance under scale.
For enterprise deployments, this layer also supports regional routing, private infrastructure (VPC), and secure production environments, ensuring compliance and data control alongside performance.
Observability and monitoring
Effective AI lifecycle management requires deep visibility into system behavior. Without it, teams have no reliable way to understand performance, debug issues, or improve outcomes.
AI observability goes beyond traditional metrics. In addition to latency, error rates, and throughput, teams need visibility into model outputs, prompt behavior, token usage, and cost. This helps answer questions like: Why did a response fail? Which model is underperforming? Where is spend increasing?
Centralized logging and tracing make this possible. Every request should carry context, model used, prompt version, routing decision, and response, so teams can trace issues end-to-end. For more complex systems, especially agents, execution traces help visualize multi-step workflows and identify where breakdowns occur.
Monitoring also enables proactive control. Tracking trends in performance and usage allows teams to detect anomalies, enforce budgets, and maintain consistent user experience as traffic scales.
With a unified observability layer, AI systems become measurable and debuggable, turning what would otherwise be a black box into a system teams can actively manage and improve.
Continuous improvement
AI lifecycle management doesn’t end at deployment. It requires continuous optimization across every layer of the system.
With Portkey's AI Gateway, teams can iterate across the full AI lifecycle, from model selection and prompt updates to routing changes and cost optimization, without disrupting production. Observability, logging, and tracing provide the foundation to evaluate performance, detect regressions, and understand real-world behavior.
Because all requests flow through a unified gateway, improvements can be applied centrally. Teams can update prompts, switch models, refine routing strategies, and enforce policies in one place, instead of making changes across multiple applications.
Ship AI Agents faster with Portkey
Everything you need to build, deploy, and scale AI agents