
COSTAR Prompt Engineering: What It Is and Why It Matters
Discover how Costar prompt engineering brings structure and efficiency to AI development. Learn this systematic approach to creating better prompts that improve accuracy, reduce hallucinations, and lower costs across different language models.
When working with large language models, getting the right output often feels like a guessing game. You try one prompt, see what happens, adjust, and try again. But what if there was a more systematic way?
COSTAR prompt engineering moves beyond the typical trial-and-error method many teams use today. It's a structured approach that looks at how models actually behave and what your specific application needs. The payoff? More accurate responses, fewer AI hallucinations, and better use of your computing budget.
That’s why we built the MCP Gateway: a centralized control layer to run MCP-powered agents in production.
Check it out!
What is COSTAR prompt engineering?
COSTAR prompt engineering is a methodical approach to creating and refining prompts for language models.
Rather than making random adjustments to prompts, you systematically analyze the model's outputs and make specific changes to the language and structure. Part of this process involves monitoring token usage to optimize efficiency.
The goal is practical: develop prompts that produce the best results for your specific needs while minimizing computational resources. This means better performance at a lower cost for your AI applications.
How COSTAR prompt engineering works
The COSTAR approach follows four main steps in practice:
- Structured Prompting: This starts with creating clear, unambiguous instructions for the AI. When prompts are well-structured, the model has less room for misinterpretation, leading to more predictable results.
- Adaptive Iteration: After seeing how the model responds, you make targeted improvements to the prompt. This isn't random experimentation but a deliberate process based on analyzing what worked and what didn't in the output.
- Model-Specific Adjustments: Different language models (like GPT-4, Claude, or PaLM) respond differently to the same prompts. The COSTAR method recognizes this and adjusts prompting strategies based on which model you're using.
- Token Efficiency Optimization: This step focuses on getting the best results with the fewest tokens. You'll trim unnecessary words and restructure prompts to be more concise while maintaining clarity - saving on both processing time and costs.
Steps in the COSTAR framework
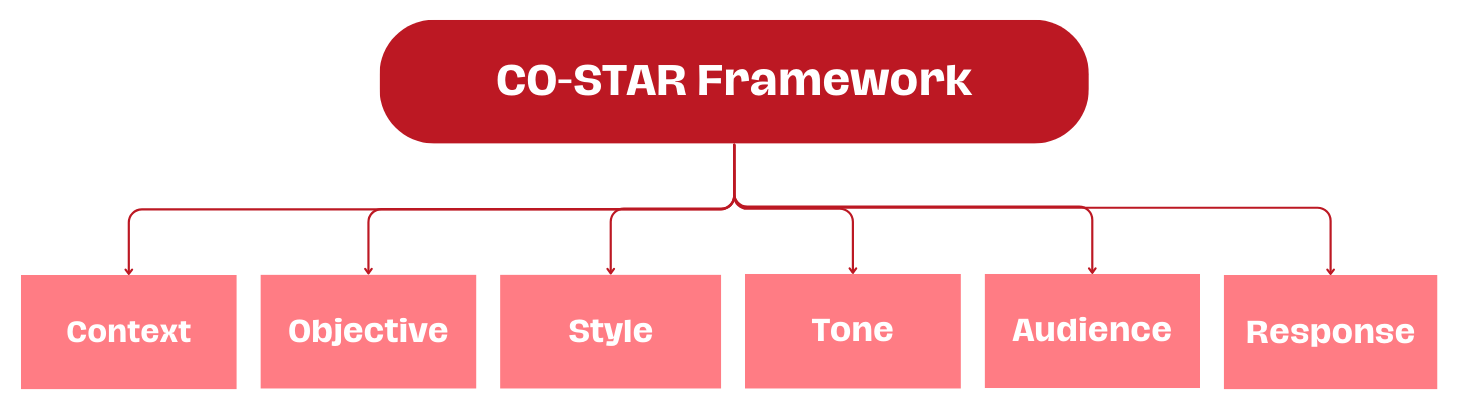
The COSTAR framework breaks down prompt engineering into six essential elements:
Context: Give your model the background information it needs. This helps ground the AI in the specific situation you're dealing with, reducing irrelevant outputs. For example, telling the model you're working with healthcare data sets different parameters than if you're analyzing social media posts.
Objective (O): Tell the model exactly what you want it to accomplish. Clear objectives prevent the model from wandering off-task. This could be "summarize this research paper" or "find inconsistencies in this code."
Style (S): Specify how you want the information presented. This might be "technical and detailed" or "simple and concise" depending on your needs. The style instruction shapes how information is organized and delivered.
Tone (T): Set the emotional quality of the response. Whether you need formal, friendly, cautious, or enthusiastic responses, explicitly stating the tone helps ensure the output feels right for your use case.
Audience (A): Identify who will be reading or using this output. The model can tailor vocabulary, complexity, and examples based on whether the audience is technical developers, business executives, or the general public.
Response (R): Define the format you need, whether that's paragraphs of text, JSON, CSV, or something else. This is particularly important when integrating AI outputs into existing systems or workflows.
Here’s an example:
Context
You are analyzing customer support tickets for a SaaS product that helps companies manage their cloud infrastructure. These tickets come from both technical and non-technical users across different company sizes. The tickets have been tagged with initial categories, but need deeper analysis.
Objective
Analyze each support ticket to identify:
- The root technical issue
- Potential product improvements that could prevent similar issues
- Priority level based on impact and frequency
Style
Structured and analytical. Present findings in clearly defined sections with bullet points for key insights.
Tone
Professional and solution-oriented. Focus on constructive analysis rather than criticism.
Audience
Internal product team including engineers, product managers, and customer success leads. Assume technical familiarity with cloud infrastructure concepts.
Response
Provide analysis in JSON format with the following structure:
{
"ticket_id": string,
"root_issue": {
"category": string,
"description": string,
"technical_details": string
},
"product_improvements": [
{
"feature": string,
"rationale": string,
"difficulty": string
}
],
"priority": {
"level": string,
"justification": string
}
}
Benefits of COSTAR prompt engineering
While traditional methods often rely on intuition and trial and error, COSTAR takes a more structured approach. It uses data from model responses to guide prompt refinement, making the process more scientific and less about guesswork.
Improved Accuracy: Your AI responses become more reliable and on-target. When prompts are carefully engineered, models stay focused on delivering exactly what you need.
Reduced Hallucinations: One of the biggest challenges with language models is when they generate plausible-sounding but incorrect information. Good prompt engineering significantly cuts down on these false outputs.
Lower Costs: By optimizing token usage, you directly reduce your API costs. This becomes especially important at scale when processing thousands or millions of requests.
When compared to other prompt engineering techniques, COSTAR has some advantages.
Compared to COSTAR, CoT focuses on getting models to show their reasoning process step-by-step. COSTAR is different - it's about refining the initial input rather than guiding how the model thinks through a problem. These approaches can be complementary, but they solve different challenges.
ToT creates complex branching pathways for model reasoning, which can be powerful but resource-intensive. COSTAR offers a more lightweight alternative that works across various LLMs without requiring specialized implementations. It's generally easier to implement and adapt to different use cases.
Enhancing COSTAR prompt engineering with Portkey
Model-Specific Optimization: Different language models have different strengths and quirks. Portkey’s Prompt Playground fine-tunes your prompts for whatever model you're using - whether it's GPT-4, Claude, or others. This means you get optimal performance without manually adjusting for each provider.
AI prompt optimisation
A/B Testing for Prompts: Instead of guessing which prompt works better, Portkey lets you test different versions systematically. It tracks performance metrics across prompt variations so you can see which ones deliver the best results based on actual data.
Prompt Playground
Forward Compatibility: As language models evolve with new versions and capabilities, your prompts need to adapt. Portkey helps ensure your carefully crafted prompts remain effective even as the underlying models change, reducing maintenance headaches.
COSTAR prompt engineering offers a structured, efficient way to enhance AI model performance. By using Portkey's AI gateway, teams can further refine prompts for specific models, maximize cost efficiency, and maintain high-quality outputs as LLMs evolve. Implementing this approach ensures better AI-driven results while keeping operational costs in check.
Would you like to give it a try? Try prompt.new today!

