
What is LLM tool calling, and how does it work?
Explore how LLM tool calling works, with real examples and common challenges. Learn how Portkey helps tool calling in production.
When you chat with an AI assistant today, you're often doing more than having a conversation. Behind the scenes, these systems can search the web, crunch numbers, or even control other software. This capability—known as tool calling—is what makes AI assistants truly useful for practical tasks.
Let's explore how this works.
Check this out!
What is tool calling in LLM?
Tool calling is the mechanism by which an LLM can invoke an external function or service to complete a task. Instead of hallucinating a response, the model passes specific requests to external tools, like sending a math problem to a calculator, checking a weather API for the forecast, or querying a database for customer details.
This capability marks a significant advancement toward AI that can think, plan, and act based on what's happening around it.
You might see tool calling in action when:
- A travel assistant checks live flight prices and availability
- A support chatbot creates tickets in your company's system
- A sales AI looks up product specs or updates customer records
How LLM tool calling works
Tool calling allows an LLM to act as a coordinator at a high level. It understands the user's query, decides whether an external function needs to be called, correctly formats the call, and integrates the tool’s output into the conversation.
Let’s break down what’s actually happening behind the scenes.
Step 1: Defining the tools
Before the model can call any function, you need to define a list of available tools. Each tool includes:
- A name (identifier)
- A description (for the model to understand when to use it)
- A JSON schema that describes the input parameters
{
"name": "get_weather",
"description": "Get the current weather for a given location",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city and state, e.g. San Francisco, CA"
}
},
"required": ["location"]
}
}
Step 2: Calling the tool
When the user sends a prompt like "What’s the weather in San Francisco?", the LLM evaluates whether the task requires a tool. If yes, it outputs a structured tool call using the schema. The decision to call a tool can either be:
- Automatic, where the model decides when and which tool to use
- Forced, where you explicitly tell the model to call a certain tool (helpful for structured workflows)
Step 3: Your app handles the call
Once the model outputs the tool name and arguments, it’s up to your app to:
- Match the call to the correct backend function or API
- Execute it
- Return the result to the LLM
This is often called a tool execution layer, where your actual business logic lives.
Step 4: The model uses the tool response
Once the response is returned, the model gets another chance to process it. It integrates the result naturally into its reply, making it feel like part of the same conversation.
How Portkey supports LLM tool calling at scale
Tool calling becomes far more complex once you’re in production: multiple models, tools, use cases, and edge cases. That’s where Portkey comes in — it acts as the orchestration and observability layer between your LLM and external tools.
Whether you’re using OpenAI, Deepseek, or other models, Portkey's AI Gateway helps you monitor, secure, and optimize tool calling end-to-end.
Unified AI gateway
Portkey supports tool calling for OpenAI, Ollama, and Groq providers. You can make it interoperable across multiple providers. With prompts, you can templatize various of your prompts & tool schemas as well.
Full observability for every tool call
Portkey captures detailed traces for every LLM call and tool interaction:
- Full prompt and system message
- Exact tool name and arguments sent
- Response from your tool or API
- Any errors or retries
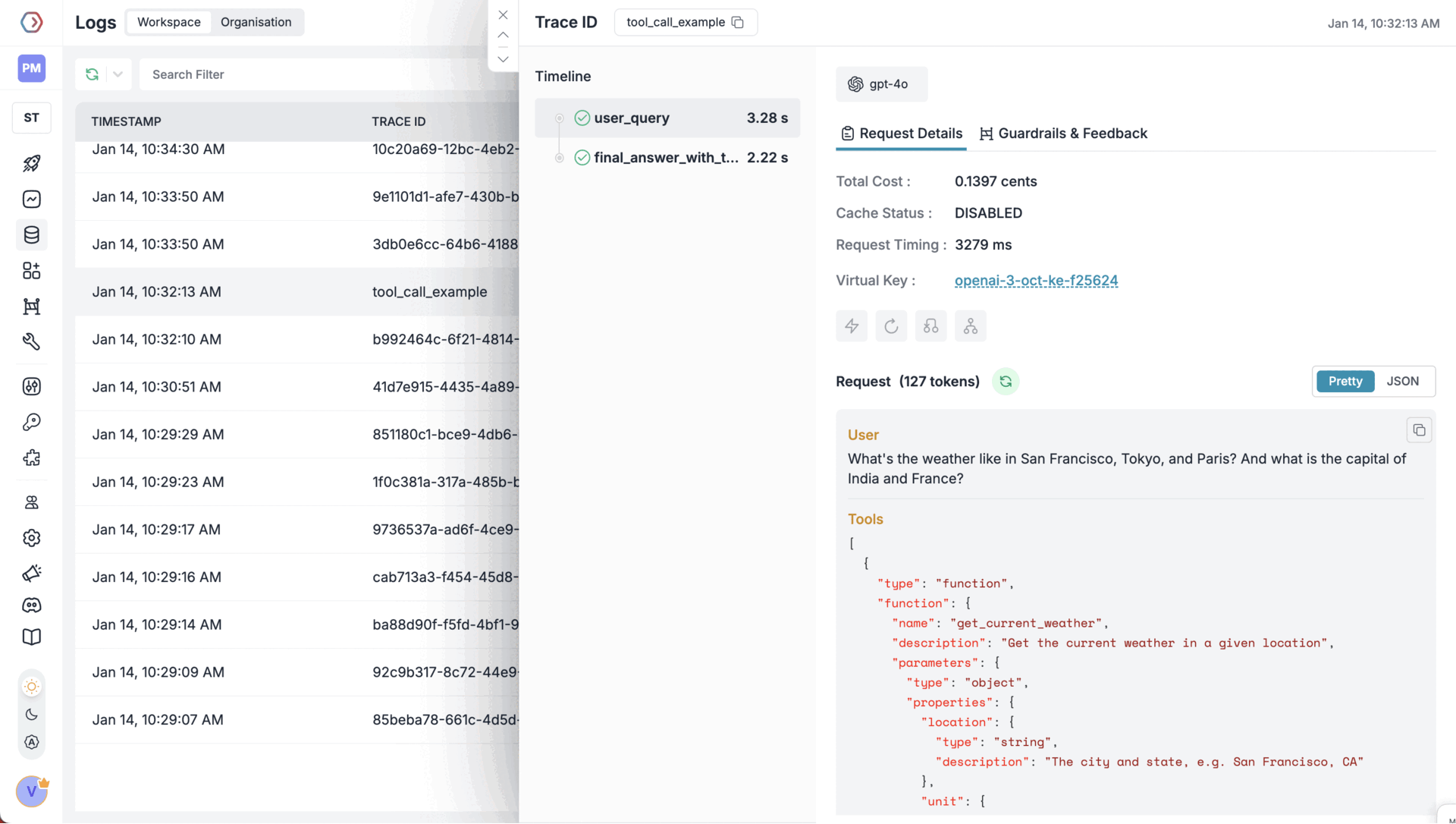
This makes debugging tool-related failures easy and gives your team visibility into what’s happening across different environments.
Retry logic and fallback routing
Tool calls can fail for a variety of reasons—network timeouts, malformed inputs, or temporary outages. With Portkey, you can implement retry logic for tools that are critical to your workflow, ensuring a seamless user experience even in the face of transient failures.
Additionally, you can define fallback, which automatically calls alternative tools if the primary one fails. For example:
- If your weather service is down, Portkey can route the request to a backup API without the model even needing to know.
- If a real-time price lookup fails, Portkey can return a cached response or a default value.
Final thoughts
Tool calling is powerful - it allows language models to move beyond simple Q&A and interact with external systems in meaningful ways, whether it's retrieving data, triggering workflows, or making decisions in real time.
If you're building LLM apps that rely on tool calling — whether for a support bot, AI agent, or internal assistant — now’s the time to invest in the right infrastructure to scale confidently.

