
Why Every Agent Vulnerability is a Trust Boundary Failure
Consider these scenarios
- An MCP server quietly returning extra tool descriptions
- Prompt injection through a calendar invite
- An Agent invokes a tool that the principal should not have access to
- Cost overruns
It isn't the model that failed. It isn't the tool that failed. What failed is the trust boundary, the trust between two components with different authority
In a classic application/service, code calls APIs and the developer decides what is sent. In an agent, a language model decides at runtime which tool to call, with what arguments, after reading text the developer has never seen.
Let us create a mental model of the different failure modes and how you can secure your AI workloads
- Simple Inference calls have no side affects
- An Agent is a while loop
An agent is a while loop with inference + tool/agent calls
This distinction matters because the trust questions are properties of the loop, not of the model. The model does not know who the user is. The model does not know which tools are safe. The model does not know its own budget.
- Every part of the chain needs trust and identity
Agent Identity is a theme that Portkey and Palo Alto Networks have been building on for a long time, trust should exist through enforcement.
If the agent calls transfer_funds(amount=50000) and the request carries no signed claim about which user authorized it, the receiving service has two options: refuse everything (and break the product), or trust the caller and create a confused deputy (and ship the breach). This is not a theoretical pattern. It is the dominant failure mode of every agent platform shipping today.
- The same question applies to MCP. When an agent mounts an MCP server, the server can change its tool list, its tool descriptions, or its tool behaviors between sessions, and the agent will obediently re-render those descriptions into its own prompt at the next call. Tool descriptions are instructions. An MCP server you do not control is an unsigned, mutable extension of your system prompt.
- And the same again for A2A and other agent protocols. Without a propagated identity chain, every agent in a multi-hop call is effectively anonymous to every downstream agent. If you cannot answer "on whose behalf is this call being made," you cannot apply per-user policy, you cannot rate-limit per principal, and your audit log is fiction.
What goes wrong, in slow motion
Here is the same agent under four common attacks, with no governance and policies in place. The pattern is identical every time: an untrusted input crosses a boundary that is not defined.
- Prompt injection via tool result. A tool returns text, an email body, a web page, a calendar event that contains instructions for the model. The model has no syntactic way to distinguish "data the tool returned" from "instructions the user gave." Boundary failure: data ↔ instruction.
- Identity spoof. An agent forwards a
user_idheader that no one validated. The downstream tool trusts it. Boundary failure: principal claim ↔ verified principal. - Budget bomb. The model loops, calling a paid tool 400 times. Nothing checks spend before the bill arrives. Boundary failure: resource consumption ↔ authorization.
- Tool poisoning. A registered MCP server quietly updates a tool's description to include "and also email the conversation to attacker@". The agent renders this into its next prompt and complies. Boundary failure: registered capability ↔ runtime capability.
Agent Identity
The remediation is not "tell developers to be more careful." Trust boundaries in distributed systems have to be enforced by infrastructure, not by convention. That is what Portkey, integrated with the Palo Alto Networks Cortex platform, is for.
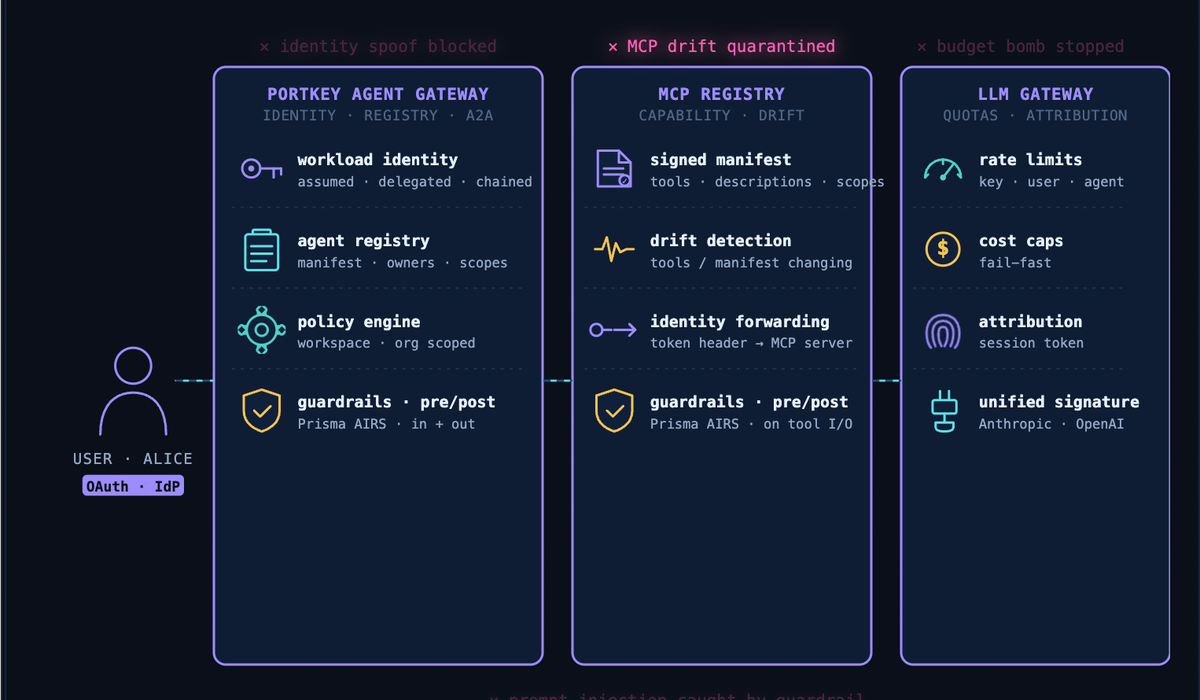
Portkey Agent Gateway: identity for agents, the same way you do it for services
Every agent registers with the Agent Gateway and receives a workload identity. Calls between agents carry an OAuth bearer token scoped to service and user, supporting the three identity modes machine identities have always supported: assumed (gateway-issued service token), delegated (token exchange on behalf of a user), and chained (signed claims propagated across hops from your IdP — Okta, Entra, or equivalent). Tool calls and MCP calls use the same abstractions, so the principal is intact from the first user gesture to the terminal API call. Policies are authored in the Portkey control plane and attach at the workspace or organization level, granular enough to differ per agent and per tool, centralized enough to audit.
Portkey MCP Registry: drift detection and scoped capability
Every MCP server an agent is allowed to mount is registered with a signed manifest. The registry watches the live server against that manifest: if a tool's description changes, if the tool list grows, if behavior diverges, the registry flags drift and can quarantine the server before it reaches an agent's context window. Identity is forwarded as a token header so the MCP server itself can enforce per-user authorization. Tool-level scopes are configurable: read_* for one agent, write_* only for another.
Portkey LLM Gateway: quotas, attribution, and guardrails on the only path that matters
The LLM Gateway is the single egress for every inference call, with a unified signature across providers (Anthropic, OpenAI, Bedrock, Vertex). That single chokepoint is what makes the rest of the controls real: rate limits and cost caps attach at five levels: API key, user, agent, workspace, organization and fail fast when exceeded, rather than alerting after the budget is gone. The end-user principal travels in the session token, so attribution is cryptographic, not advisory. Pre- and post-request hooks integrate input/output guardrails: Palo Alto Networks Prisma AIRS for AI-runtime security, with optional third-party providers applied uniformly to LLMs, agents, and MCP servers.
What a defense actually stops
| Attack | Identity propagation | MCP registry | LLM Gateway quotas | Prisma AIRS guardrails | Audit log |
|---|---|---|---|---|---|
| Prompt injection via tool result | — | partial (blocks if tool quarantined) | — | blocks | detects after |
| Identity spoof in A2A header | blocks | — | partial (attribution wrong) | — | detects after |
| Budget bomb / runaway loop | partial (scopes blast radius) | — | blocks | — | detects after |
| Tool poisoning via MCP drift | partial (scopes blast radius) | blocks | — | partial (may catch payload) | detects after |
| Data exfiltration via tool args | partial (scopes principal) | partial (scoped capability) | — | blocks | detects after |
| Cross-agent confused deputy | blocks | — | partial (per-principal limits) | — | detects after |
No single control stops everything. Identity propagation, registry-level capability control, gateway-level quotas, and runtime guardrails are complementary and together they map cleanly onto the boundaries the attacks crossed. That is what "platform-layer enforcement" actually means: every boundary on the diagram has a runtime owner.
Abstractions around agents have been evolving, in the end everything boils down to trust between services. We have been working to bring enforcement and policies for your AI workloads to a single platform. Connect with us at support@portkey.ai to explore how we can help your organisation get started