

Attention Isn’t All You Need
Mamba: The AI that remembers like a Transformer but thinks like an RNN. Its improved long-term memory could revolutionize DNA processing, video analysis, and AI agents with persistent goals.

Mistral recently announced a 7B parameter Codestral Mamba model. While there are quite a few of such smaller models out there now.. there's something special about this one — it's not just about size this time, it's about the architecture.
Here's a Codetral Mamba(7B) tested against other similarly sized as well as some bigger models:
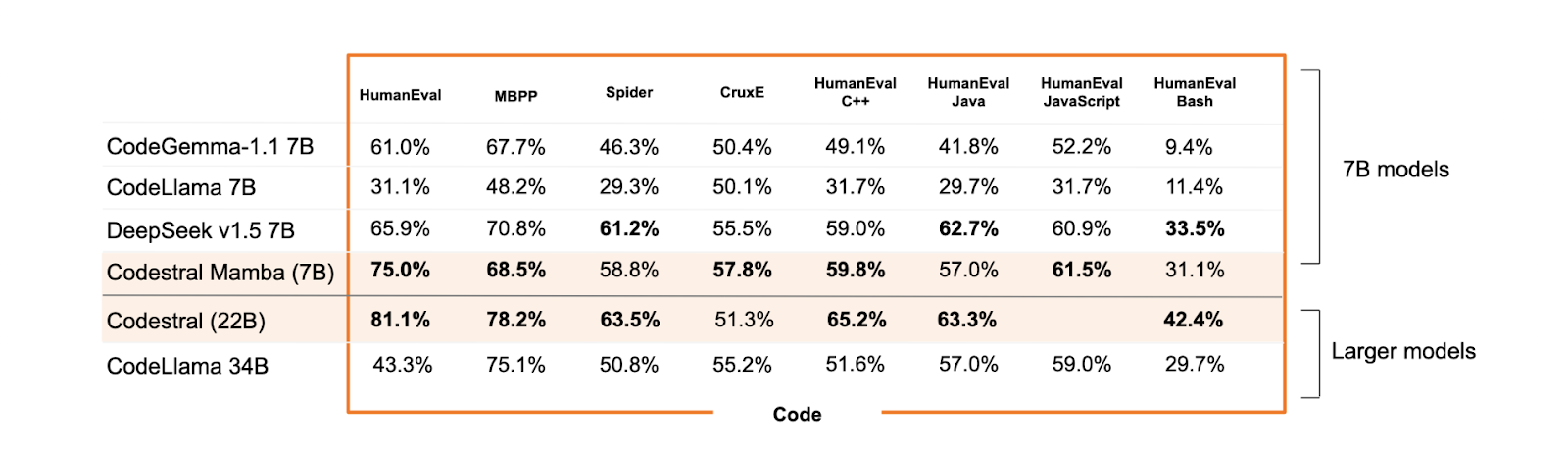
As you can see, Codestral Mamba squarely beats most models of its size and also rivals much bigger Codestral22B & CodeLlama34B models in performance.

The Transformer Dilemma
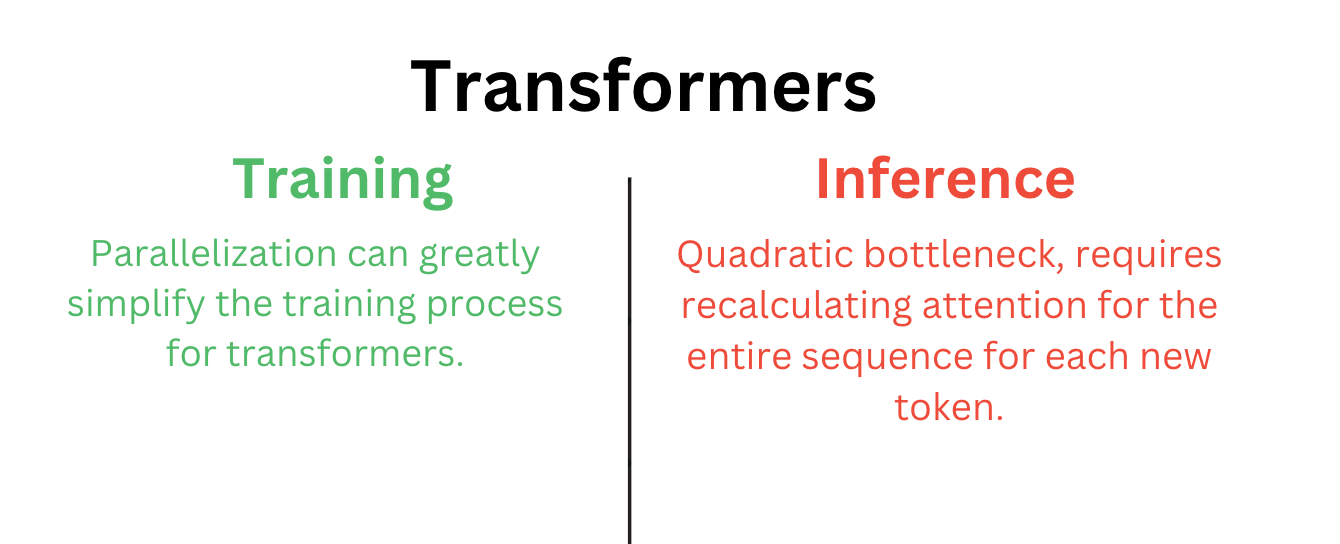
Transformers have been the cornerstone architecture for LLMs, powering everything from open-source LLMs to ChatGPT and Claude. They are great at remembering things, each token can look back at every previous token when making predictions. Making them undeniably effective, storing every detail from the past for theoretically perfect recall.
However, every rose has its thorn. The attention mechanism comes with a significant drawback: the quadratic bottleneck problem. When generating the next token, we need to recalculate the attention for the entire sequence, even if we have already generated some tokens. This leads to increasing computational costs as sequences grow longer.
Traditional RNNs Do One Thing Well
On the other side of the spectrum, we have traditional Recurrent Neural Networks (RNNs). These models excel at one thing: efficiency.
RNNs process sequences by maintaining a hidden state, retaining only a small portion of information and discarding the rest. This makes them highly efficient but less effective since the discarded information cannot be retrieved.
What If.. We Could Take The Good Parts of RNNs?
Enter Mamba: The Selective State Space Model
Mamba is a model that aims to combine the best of both worlds. It belongs to a class of models known as State Space Models (SSMs). SSMs excel in understanding and predicting how systems evolve based on measurable data. State Space, very simply, is the minimum number of variables that can define a system.
e.g., for a moving car that would be x, y coordinates, and its speed. The rest can be derived from the state variables.
SSMs are models that can define the next state of a system with the help of the state variable and input provided.
This makes SSMs just as efficient as RNNs — however, they struggle with discarding irrelevant information while retaining what's important.
Mamba takes the efficiency of RNNs and enhances it with a crucial feature: selectivity. This selective approach is what elevates basic SSM models to Mamba - the Selective State Space Model. Selectivity enables each token to be transformed according to its specific requirements.

Mamba Outperforms Transformers
Mamba hence performs similar to or better than Transformers-based models. And crucially, it eliminates the quadratic bottleneck present in the attention mechanism. (done using Selective SSM)
Gu and Dao, the Mamba authors write:
“Mamba enjoys fast inference and linear scaling in sequence length, and its performance improves on real data up to million-length sequences. As a general sequence model backbone, Mamba achieves state-of-the-art performance across several modalities such as language, audio, and genomics. On language modelling, our Mamba-3B model outperforms Transformers of the same size and matches Transformers twice its size, both in pretraining and downstream evaluation.”
Paper: https://arxiv.org/abs/2312.00752
The performance bump you see on Mistral's Codestral-Mamba models is because of this.
Here's why it's special:
- Efficiency: Mamba performs similarly to or better than Transformer-based models while maintaining the efficiency of RNNs.
- Scalability: It eliminates the quadratic bottleneck present in the attention mechanism, allowing for linear scaling with sequence length.
- Long-term memory: Unlike traditional RNNs, Mamba can selectively retain important information over long sequences.
Mamba in Action
LLMs are already good at summarizing text, even if some details may be lost. However, summarizing other forms of content, like a two-hour movie is trickier!
Long-Term Memory
This is where Mamba's long-term memory comes into play, enabling the model to retain important information. Mamba could be a game-changer for tasks requiring extensive context, like:
- DNA processing
- Video analysis️
- Agentic workflows with long-term memory and goals
Using Mamba Today
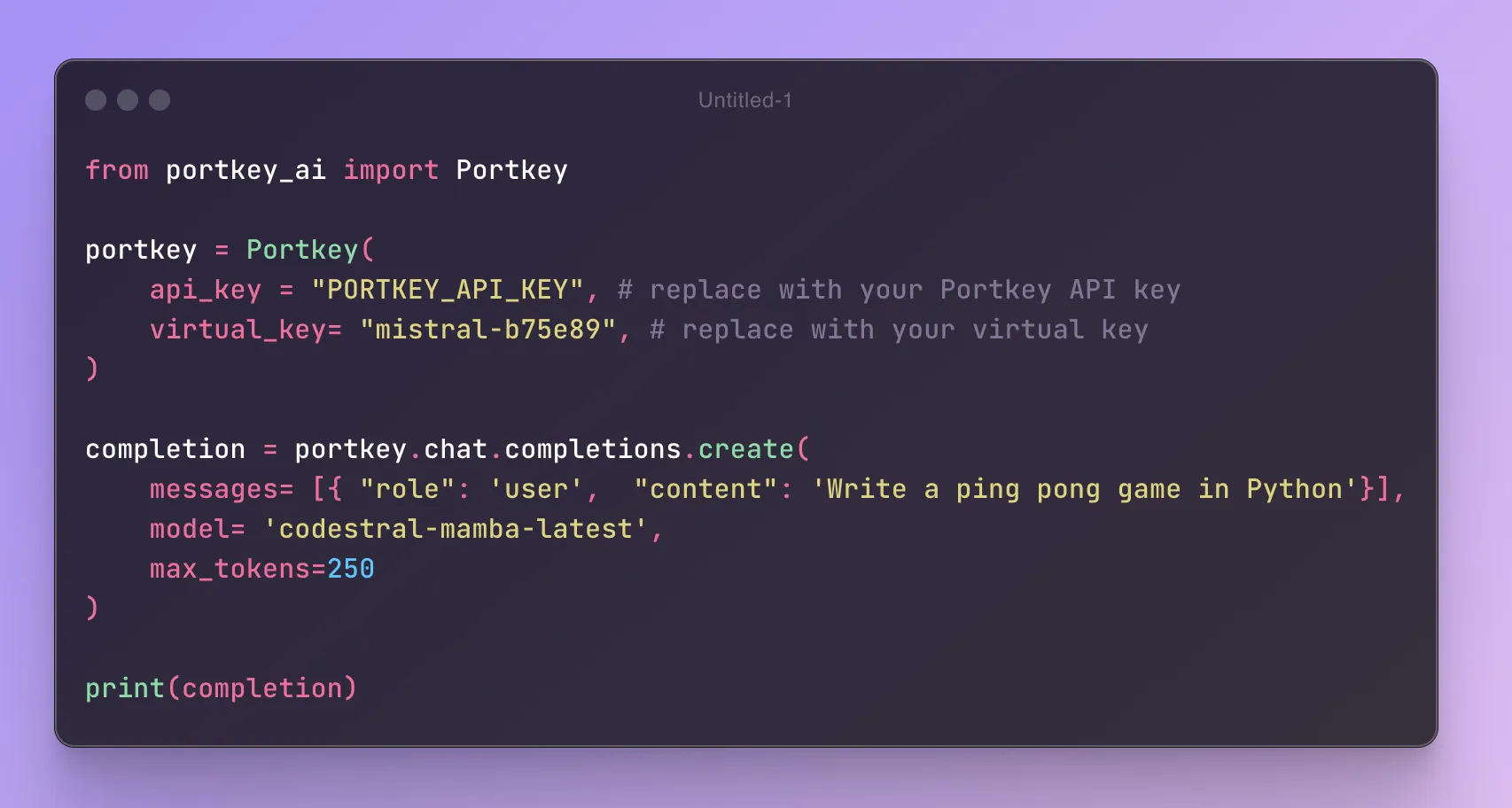
Portkey natively integrates with Mistral' APIs - making it effortless for you to try out their Codestral Mamba model for multiple different use cases!
Conclusion: A New Tool in the AI Toolkit
As AI engineers, it's crucial to stay abreast of these architectural innovations. Mamba represents not just a new model, but a new way of thinking about sequence processing in AI. While Transformers will continue to play a vital role, Mamba opens up possibilities for tackling problems that were previously computationally infeasible.
Whether you're working on next-generation language models, processing complex scientific data, or developing AI agents with long-term memory, Mamba is an architecture worth exploring. It's a powerful reminder that in the world of AI, attention isn't always all you need—sometimes, selective efficiency is the key to unlocking new potentials.
Ready to explore Mamba in your projects? Join other engineers building AI apps on the Portkey community here.

