Portkey Goes Multimodal

2024 is the year where Gen AI innovation and productisation happens hand-in-hand.
We are seeing companies and enterprises move their Gen AI prototypes to production at a breathtaking pace. At the same time, an exciting new shift is also taking place in how you can interact with LLMs: completely new interfaces and modalities of interacting with them are emerging. From vision, audio models like GPT-4-V, Claude, Hume, ElevenLabs to hardware like Rabbit, Humane, Tab, and more.
Josh from The Browser Company said it neatly:
Soon all this AI/LLM stuff is going to be like water & electricity, available to anyone who wants it. And if that is true, the best product, the one that innovates at the interface layer, will win.
Why Multimodality Matters
Reality is fundamentally multimodal. LLMs that can operate in a rich, multimodal environment and can converse using images, audios, etc. beyond just text, are going to be truly useful beyond what's possible. These LLMs are here today, and are ready to go to production.
With Portkey, our vision always has been straightforward - help developers bring their LLM apps to production, whether those apps are part of an existing stack, a stand alone new product or agent, or a completely new device never seen before - all operating across multiple modalities.
Early Experiments with Multimodality
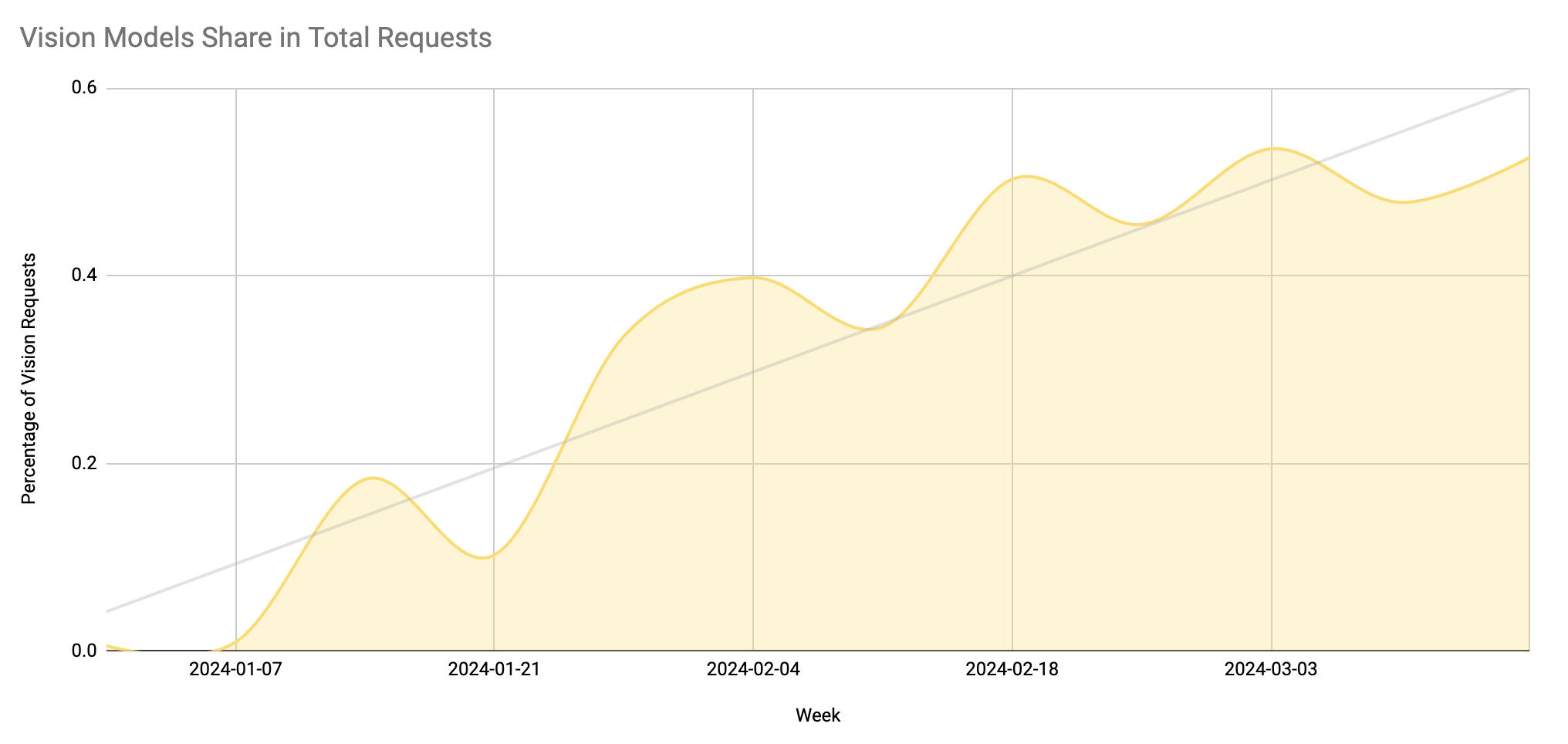
Some of Portkey's marquee customers, like MultiOn, Quizizz are using vision models in completely unexpected and novel ways compared to chat models. So much so, that Quizizz has completely shifted their workloads to vision models and stopped using chat models.
We are seeing multimodal models take up more share of total requests on Portkey week over week:
But the Production Challenges Continue..
As more companies start to build out multimodal features within their products - the same issues that LLMs have had in terms of lack of reliability, observability, slow experimentation, also affect these multimodal models.
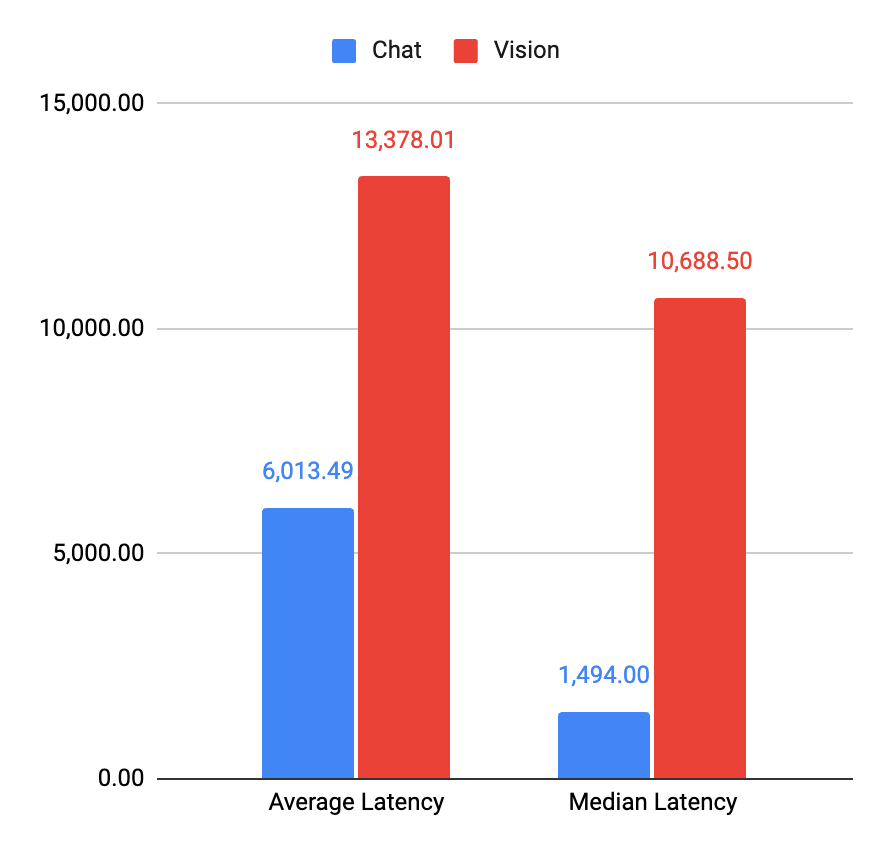
- Vision models on an average have higher fail scenarios compared to chat models. (5% v/s 2%)
- Vision model pricing is quite steep, especially for processing images.
- The median (50 percentile) latency for a vision model request is 7x that of a chat model! (and it goes even higher for tail-end queries)
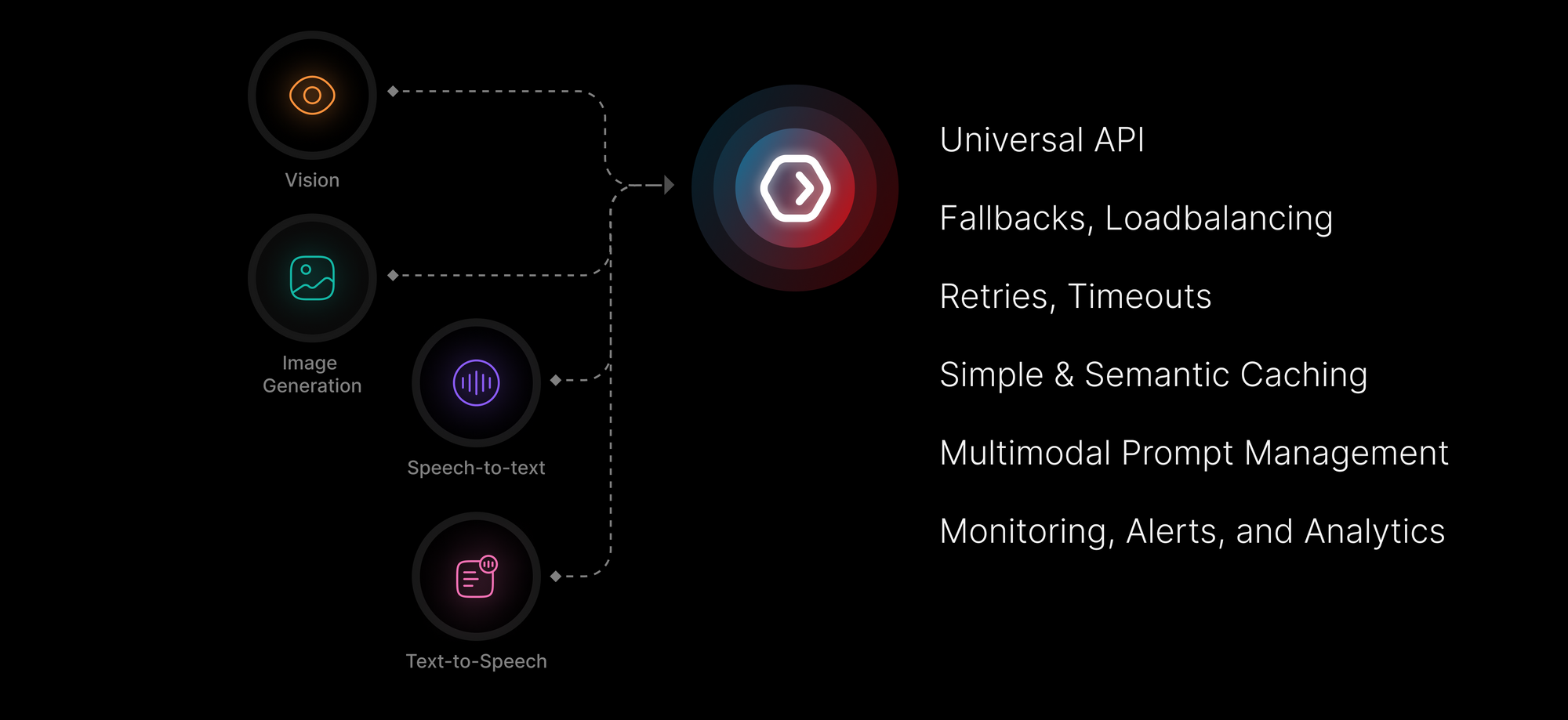
Using Portkey, you can tackle each of these problems (and also completely eliminate some).
How We Solve It
Because of how Portkey works, supporting Multimodal LLMs essentially means that you no longer need to wade through the docs of every new multiomdal LLM to integrate it in your app.
That's just Step 1. By using these new multimodal LLMs through Portkey, you automatically make them reliable and production-grade with our Gateway and Observability features for automated fallbacks, load balancing, retries, request timeouts, simple & semantic caching, monitoring & alerts, and more.
- Want to call
Claude-3if yourGPT-4-Visionmodel fails? Done ✅ - Want to switch between
SDXLandDall-E-3without rewriting any code? Done ✅ - Want to tackle the stringent rate limits on vision models? Done ✅
- Want to reduce your costs & latency for repeat vision model queries using cache? Done ✅
- Want observability over your transcription or translation calls? Done ✅
I'll quickly show you how you can do each of these with Portkey:
1. Call Claude-3 in case of GPT-4-Vision Failures
pip install portkey-ai- Add your Anthropic & OpenAI keys to Portkey vault
- Write the following Fallback Config in Portkey app and save it:
{
"strategy": { "mode": "fallback" },
"targets": [
{
"virtual_key": "openai-virtual-key",
"override_params": { "model": "gpt-4-vision" }
},
{
"virtual_key": "anthropic-virtual-key",
"override_params": { "model": "claude-3-sonnet" }
}
]
}Portkey will return a "Config ID" that refers to this config.
4. Now, just pass the saved Config ID in your vision call:
from portkey_ai import Portkey
portkey = Portkey(
api_key="PORTKEY_API_KEY",
#############
config= "CONFIG_ID"
#############
)
response = portkey.chat.completions.create(\
model="gpt-4-vision-preview",
messages=[{
"role": "user",
"content": [
{ "type": "text", "text": "What’s in this image?" },
{ "type": "image_url", "image_url": "path/to/file.jpg" }
]
}],
max_tokens=300,
)Portkey will now automatically route any of your failed gpt-4-vision requests to claude-3 automatically!
2. Reduce your costs & latency with Cache
Similar to above, in your Config, just add the following cache setting:
{
"cache": { "mode": "simple" }
}With this, Portkey will return repeat vision queries from its cache instead of making an expensive LLM call, saving you both precious time and money.
3. Eliminate Stringent Rate Limits
Many vision models still have stringent rate limits that become a blocker for you to put them in production. With Portkey, you can split your vision model traffic across different LLMs and accounts and not overburden any one LLM or account by hitting TPM or RPM thresholds. Effectively, you can multiply your rate limits by loadbalancing your requests across multiple accounts.
Loadbalance logic is also written with Portkey's Configs:
{
"strategy": { "mode": "fallback" },
"targets": [
{
"virtual_key": "openai-key-1",
"weight":1
},
{
"virtual_key": "openai-key-2",
"weight":1
},
{
"virtual_key": "openai-key-3",
"weight":1
}
]
}Save this Config and just pass the Config ID while instantiating your Portkey client:
from portkey_ai import Portkey
portkey = Portkey(
api_key="PORTKEY_API_KEY",
config= "CONFIG_ID"
)4. Swap out Dall-E-3 for SDXL
Portkey lets you send API requests to Stability AI API, in the OpenAI spec. So, if you've got a Dall-E code block:
from portkey_ai import Portkey
portkey = Portkey(
api_key="PORTKEY_API_KEY",
virtual_key="OPENAI_VIRTUAL_KEY"
)
image = portkey.images.generate(
model="dall-e-3",
prompt="Lucy in the sky with diamonds"
)Just change the virtual_key and model to Stability AI:
from portkey_ai import Portkey
portkey = Portkey(
api_key="PORTKEY_API_KEY",
virtual_key="STABILITY_AI_VIRTUAL_KEY"
)
image = portkey.images.generate(
model="stable-diffusion-xl-1024-v1-0",
prompt="Lucy in the sky with diamonds"
)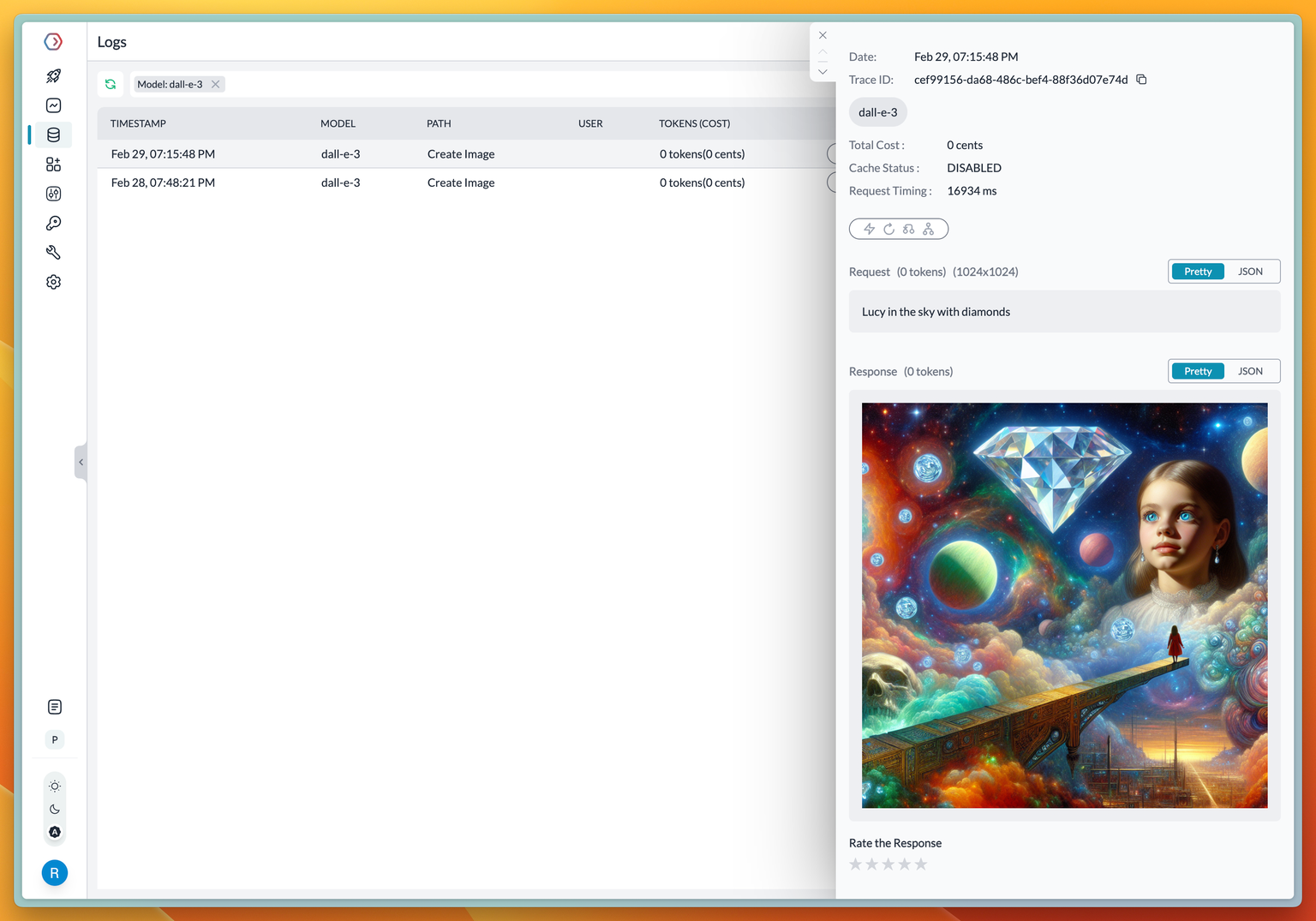
That's it! You don't need to do anything more to make a call to Stability AI now.
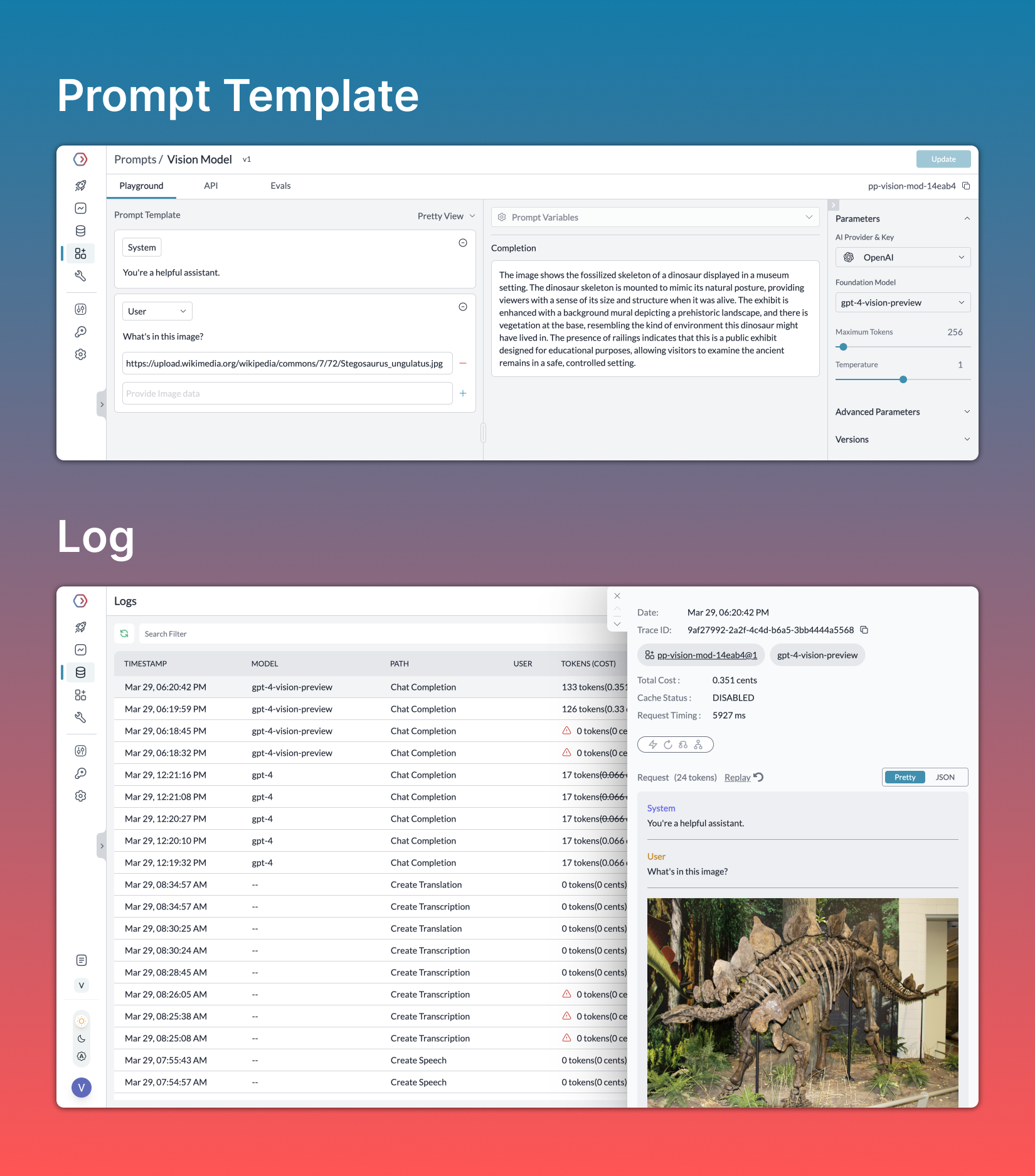
5. Multimodal Prompts
Portkey supports creating multimodal prompt templates in its playground. You can pass image URL/data along with the rest of your messages body and deploy multimodal prompt templates to production easily.
Get Started Today!
Whether you're building a cutting-edge application or exploring the possibilities of multimodal AI, Portkey is your gateway to the future. Explore our extensive guides on how you can productionise multimodal LLMs with Portkey:


To meet other practitioners such as engineers from Quizizz, MultiOn that are pushing the boundaries of what’s possible with multimodal LLMs, join our close-knit community of practitioners putting LLMs in Prod: