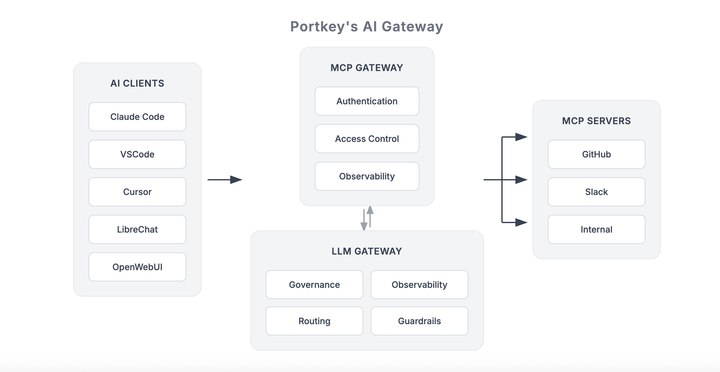
Your interns need three approvals to touch production. Your AI agents? Zero.
With MCP, agents can take real action – connect to databases, trigger workflows, access internal systems. The protocol just works.
But here's what we kept hearing from teams actually running MCP in production: "How do I