

How to balance AI model accuracy, performance, and costs with an AI gateway
Finding the sweet spot between model accuracy, performance, and costs is one of the biggest headaches AI teams face today. See how an AI gateway can solve for that.
Finding the sweet spot between model accuracy, performance, and costs is one of the biggest headaches AI teams face today. As more companies jump into using generative AI, striking this balance isn't just nice to have—it's make-or-break for your AI projects.
Cost overruns are a real concern. Gartner's research shows a pretty stark reality: through 2028, at least half of generative AI projects will blow past their budgets because of poor architecture decisions and operational inexperience.
Let's talk through some practical ways to manage these trade-offs with an AI gateway so your AI initiatives don't become expensive while still delivering the results you need.
Assessing your AI requirements
Before you pick models or lock in your architecture, take time to figure out what you really need. This upfront work saves headaches later.
Start by pinning down what success looks like for your specific situation:
Define what "good enough" accuracy means. How precise does your model actually need to be? Some applications can work fine with 85% accuracy, while others might fail completely below 95%. Be honest about what your use case requires rather than defaulting to the highest possible accuracy.
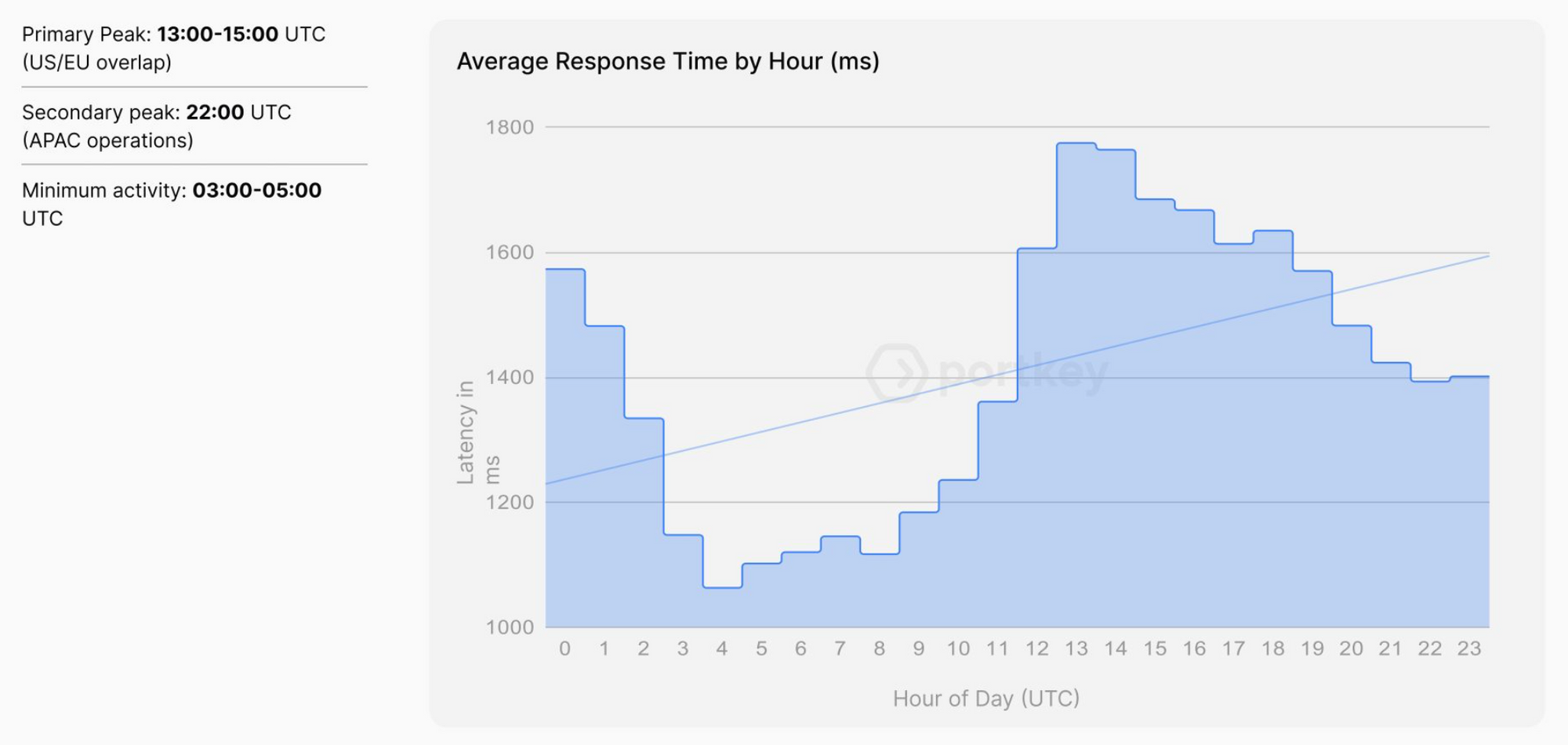
Get clear on speed requirements. How fast does your AI need to respond? If users are waiting for results, even a 2-second delay might be too much. But for overnight data processing jobs, response time matters much less than throughput. See what the average response time is during peak hours.
Know your budget boundaries. Map out both what you can spend now and what ongoing costs you can sustain. Remember to account for the less obvious expenses like data cleaning, infrastructure scaling, and regular model updates.
Check for regulatory guardrails. Some industries have specific rules about AI systems that might limit your options or add requirements for explainability and transparency.
Strategies for balancing the triangle
Adopt a Multi-Model Approach
Using different models for different tasks can save you money and boost performance where it matters most. This is becoming standard practice for teams that have moved beyond their first AI projects.
You can structure your approach with an AI gateway to:
- Use lightweight models for everyday tasks where "good enough" accuracy works fine
- Reserve your computing power and budget for complex tasks where precision really matters
- Look for specialized models that excel in specific domains rather than using general-purpose models for everything
This strategy makes sense from a practical standpoint, too.
Organizations are actively looking for ways to control their access costs. AI gateways are proving useful by not only tracking and controlling service access but also by offering cost-saving features—optimizing requests to reduce token usage, caching responses to avoid duplicate calls, and managing both retries and throttling limits.
Implement LLM routing
Before diving into routing specifics, it's worth emphasizing that using multiple LLMs from different providers should be part of your core strategy.
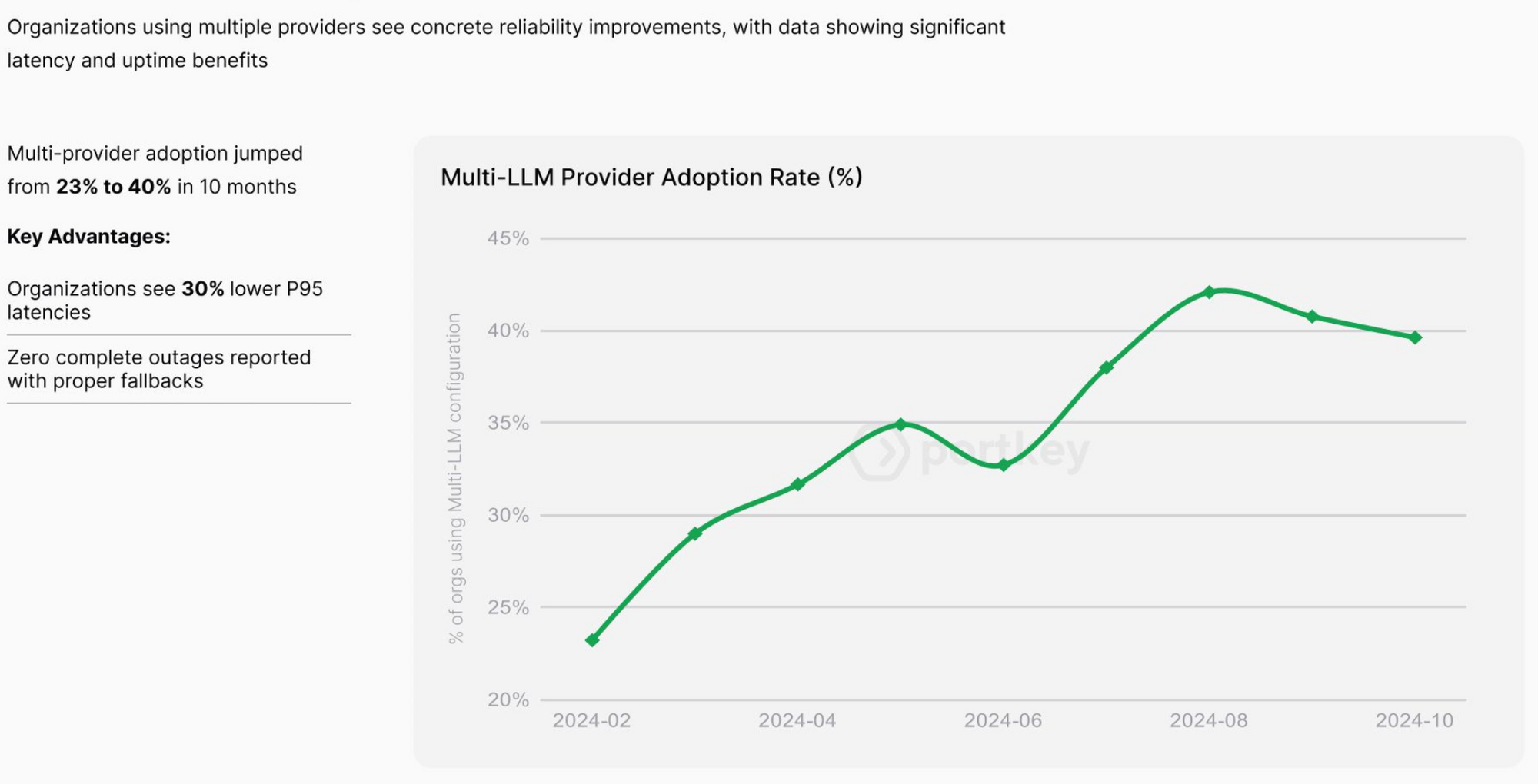
Relying on a single LLM creates several risks for your organization. Vendor lock-in severely limits your flexibility to adapt as the AI landscape evolves. You also create single points of failure in your AI stack that could disrupt operations. Working with just one provider gives you less negotiating power for pricing and leaves you exposed to model-specific weaknesses. Additionally, you're vulnerable when provider policies change in ways that affect your use cases.
AI Gateways provide reliability by offering different ways to distribute workloads across models.
Conditional routing directs queries to specific models based on predefined rules, letting you match each request with the most suitable model. You can route by query characteristics, sending complex questions to more capable models while directing simple ones to lightweight alternatives.
Load balancing distributes traffic across multiple model instances to optimize resource usage while maintaining consistent performance. By tracking current model utilization, you can shift traffic away from overloaded instances to maintain response times.
Similarly, fallback and retries can also be used in routing logic to make sure you rescue requests and improve the reliability of your application.
An AI Gateway can:
- Analyze incoming queries to determine complexity
- Route simple queries to smaller, cost-efficient models
- Direct complex queries to more powerful models
- Balance load across models based on performance metrics
For example, a customer service AI might route basic inquiries to a lightweight model while escalating complex issues to a more sophisticated model.
Optimize prompt engineering
Well-designed prompts are often overlooked as a way to balance accuracy and costs.
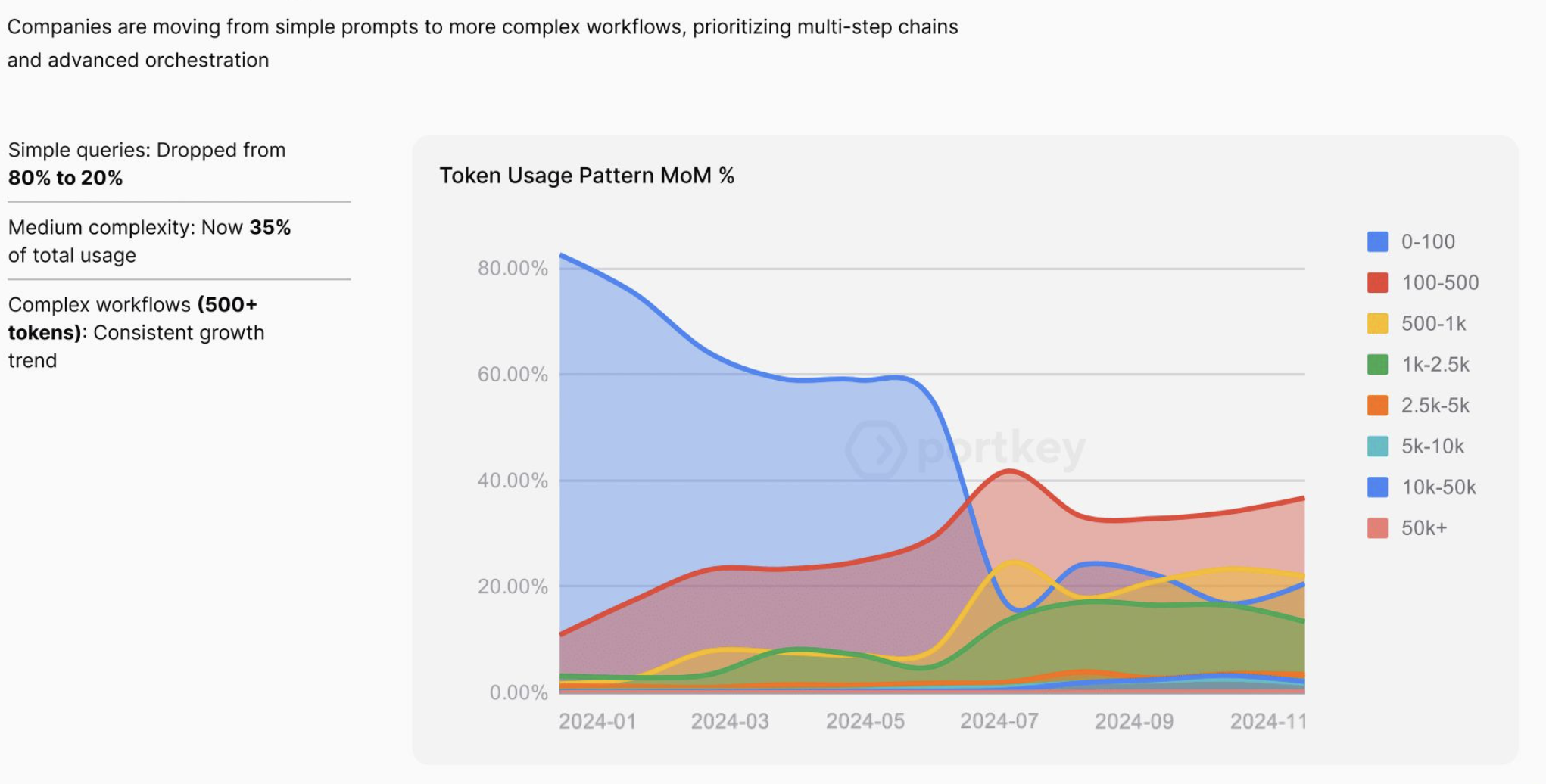
Good prompt engineering can dramatically cut your token usage while getting better results from the same models. When you craft prompts that clearly guide the model, you get more focused responses with fewer wasted tokens. This approach reduces the need for multiple back-and-forth interactions to clarify what you want.
Creating reusable prompt templates for common tasks saves both development time and computing resources. These templates can include the right amount of context, clear instructions, and examples that show the model exactly what you need. For instance, a prompt that includes "respond in 3 sentences maximum" not only gets you more concise answers but can significantly reduce your token costs over time.
Many teams are now building prompt libraries—collections of tested, optimized prompts for different use cases. These libraries become valuable assets that improve over time as you learn what works best with different models. Some platforms also provide tools that help non-technical team members create effective prompts without needing to understand the underlying model details.
Use caching mechanisms
Implementing caching for AI responses can dramatically reduce costs for repetitive or similar queries.
The savings from caching can be substantial, especially for applications with predictable usage patterns. Customer service bots, for example, often get the same questions about return policies or account setup dozens or hundreds of times per day.
AI gateways now offer intelligent caching that lets you set expiration policies based on content type, keeping product information cached longer than time-sensitive data, for instance.
Implementing a cost-aware AI governance framework
Keeping your AI systems balanced requires ongoing attention, not just initial setup. A well-designed AI governance framework helps you track performance, costs, and user satisfaction over time so you can make data-driven adjustments as needed.
According to Gartner, 70% of organizations building multi-LLM applications will use AI gateway capabilities for optimizing cost performance outcomes by 2028, up from less than 5% in 2024. These platforms provide a central control point for managing your entire AI stack, helping you implement best practices without building everything from scratch.
Start by implementing regular performance and cost monitoring across your AI applications using an AI Gateway. Track metrics that matter for both technical and business outcomes - token usage, response latency, throughput rates, accuracy on key tasks, and direct costs. These metrics give you visibility into how changes affect your system. Many teams create dashboards that highlight these metrics by model, application, and time period to spot trends early.
Make comparative evaluations part of your routine. Schedule quarterly assessments where you benchmark your current setup against promising alternatives.
Analyze actual usage patterns to find optimization opportunities that might not be obvious from technical metrics alone. Look for time-of-day patterns, query clusters, or user behaviors that suggest ways to adjust your system. For instance, you might discover that certain query types account for a disproportionate share of your costs but deliver limited business value.
Build feedback loops into every AI application you deploy. User feedback provides insights that technical metrics might miss, like when responses are technically accurate but miss the real intent behind a question. This qualitative information helps you refine both your models and the systems around them. Simple thumbs-up/down ratings combined with occasional follow-up questions can provide valuable direction for improvements.
Key Recommendations
- Be objective about model trade-offs: The largest or most advanced model isn't always necessary. Normalize pricing models for accurate comparisons.
- Employ guided prompt design: Invest in tools and training that optimize prompts for both accuracy and cost efficiency.
- Implement caching solutions: Explore tools that can optimize model usage through effective caching mechanisms.
- Consider model routing: Automate the selection of appropriate models based on task requirements.
- Monitor and govern consumption: Implement tools to track usage patterns and enforce reasonable limits.
- Conduct regular cost reviews: Schedule monthly or quarterly evaluations of your AI costs and optimization opportunities.
Path forward
Balancing model accuracy, performance, and costs isn't a one-time decision but an ongoing process. As AI technologies evolve and your organization's needs change, this balance will need regular recalibration.
For organizations serious about scaling their AI initiatives sustainably, implementing an AI gateway like Portkey provides the infrastructure needed to balance all three corners of the triangle—accuracy, performance, and costs—while maintaining the flexibility to adapt.
If you're looking to achieve that balance, Portkey is the right choice. Try it yourself or book a demo today.

