⭐ Building Reliable LLM Apps: 5 Things To Know
In this blog post, we explore a roadmap for building reliable large language model applications. Let’s get started!
Take a look at OpenAI's status page:
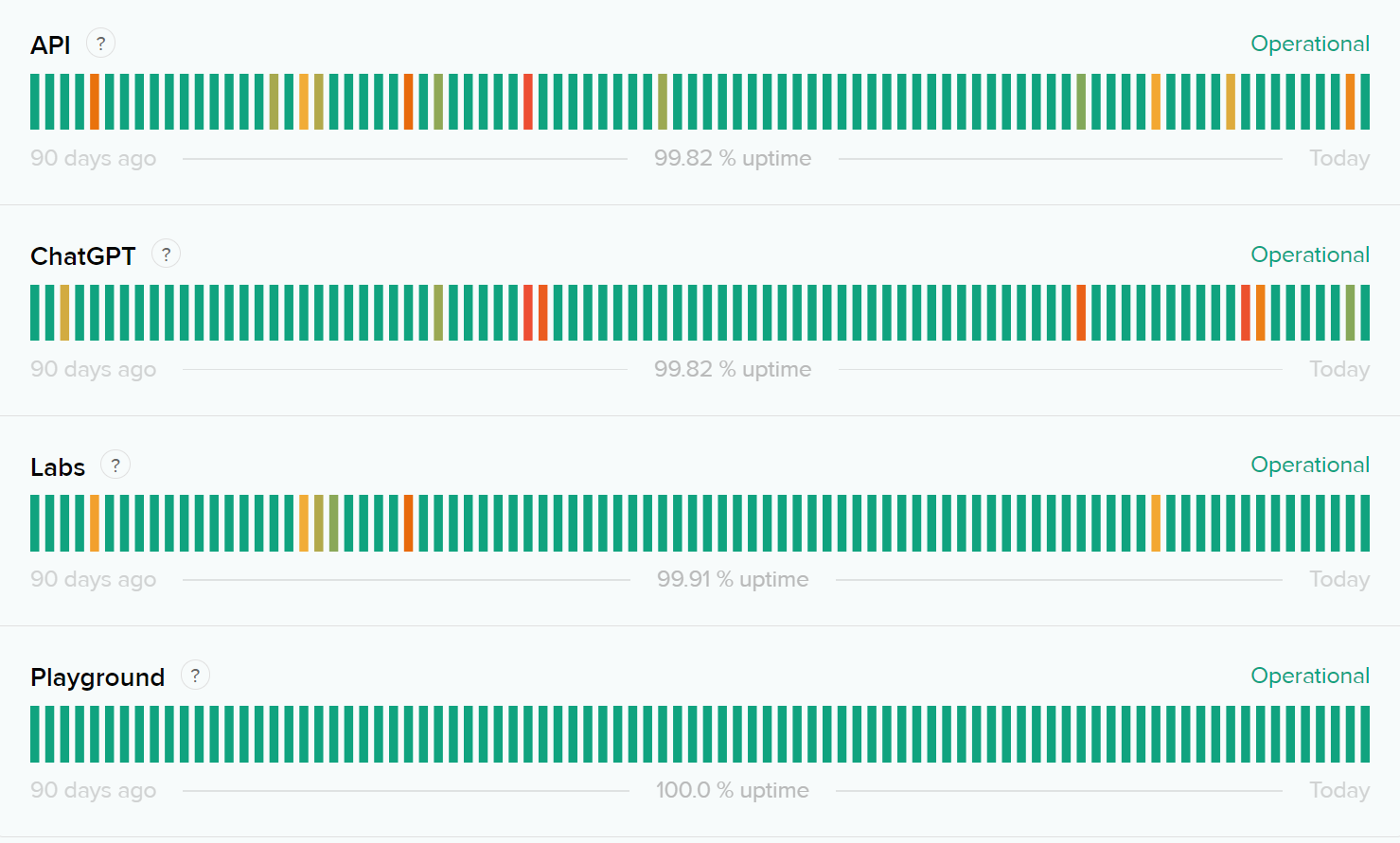
At any time, you might find 1000s of users reporting errors while accessing the API in their community or on Twitter.
The fact that OpenAI can sustain even this uptime amidst such heavy usage is amazing. They've managed to do this with a combination of great engineering and a robust implementation of rate limits.
Despite OpenAI's impressive resilience, API downtimes & errors are common. You need to bake-in reliability within your application. You need to ensure that your app remains robust, even when there are challenges with the underlying APIs.
So, how do you design your apps to ensure a smooth user experience when the unexpected (downtime, throttling, errors) happens?
“What you don't measure, you can't fix.”
If you're launching an app on any of the LLM providers, having a monitoring setup from the outset is a crucial step in maintaining reliability. Once you have the right monitoring and metrics in place, you can take more steps to make your app robust and to improve it's user experience.
Ready to delve in? In this blog post, we'll explore these steps in detail, providing you with a roadmap for building reliable large language model applications. Let’s get started!
5 Essential Reliability Strategies
1. 👣 Log Your Requests & Responses
The sanest thing to do right before launching to production is to ensure all the LLM API calls are being logged. This creates confidence in the LLM system, and helps debug problem areas faster.
Be mindful that since prompts and responses can contain large chunks of text, the ingestion costs can spiral out of control with traditional logging setups.
You might want to either remove the text pieces before sending them to your logging server or consider a specialised logging system.
2. ⚠️ Set up Alerts for Failures
Viewing aggregated data is great to understand trends in usage, latency and failures. Once you have that, it's crucial to set up alerts for faster response times.
For an LLM system, failures are typically of 2 types:
Request failures: The API server responded with a 4XX or a 5XX. You can manage these through the API monitoring setup that captures & aggregates the API errors.
Response failures: The response is inaccurate or poor. LLMs are prone to confabulate, and it's critical to check the responses before they hit the user. You can use a library like Guardrails to validate the outputs or write tests after the API responds and log the validation results.
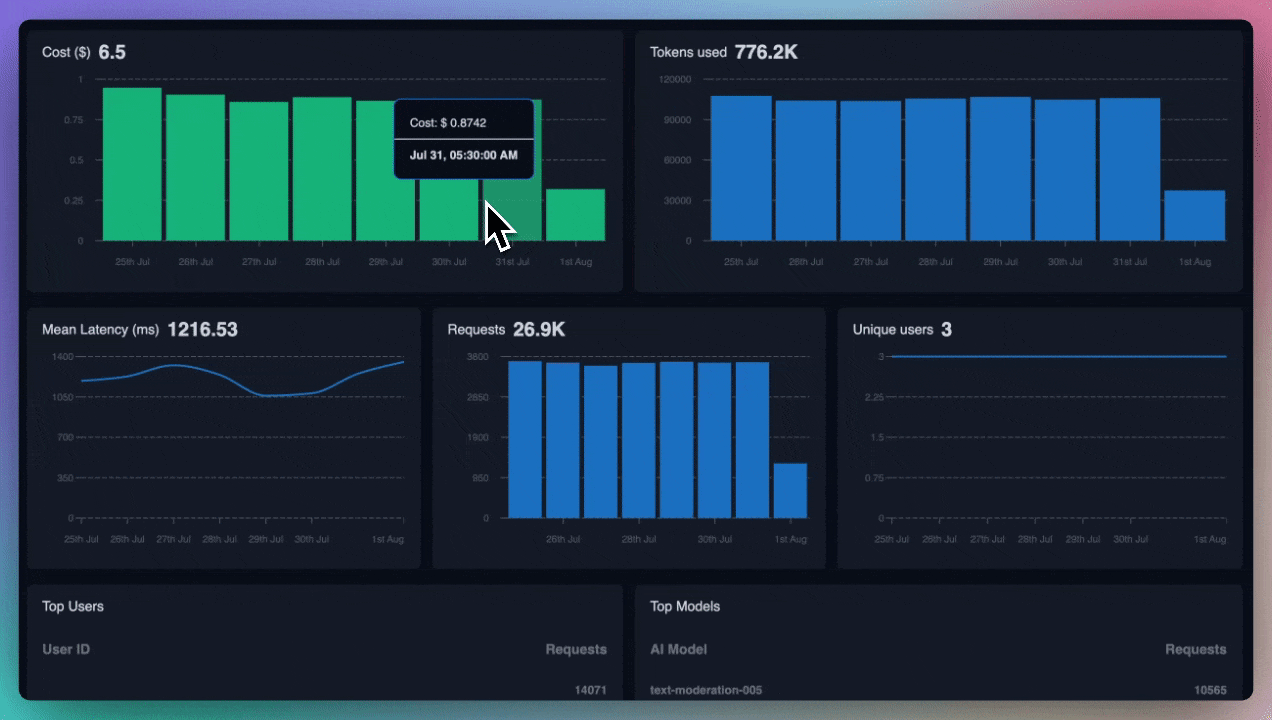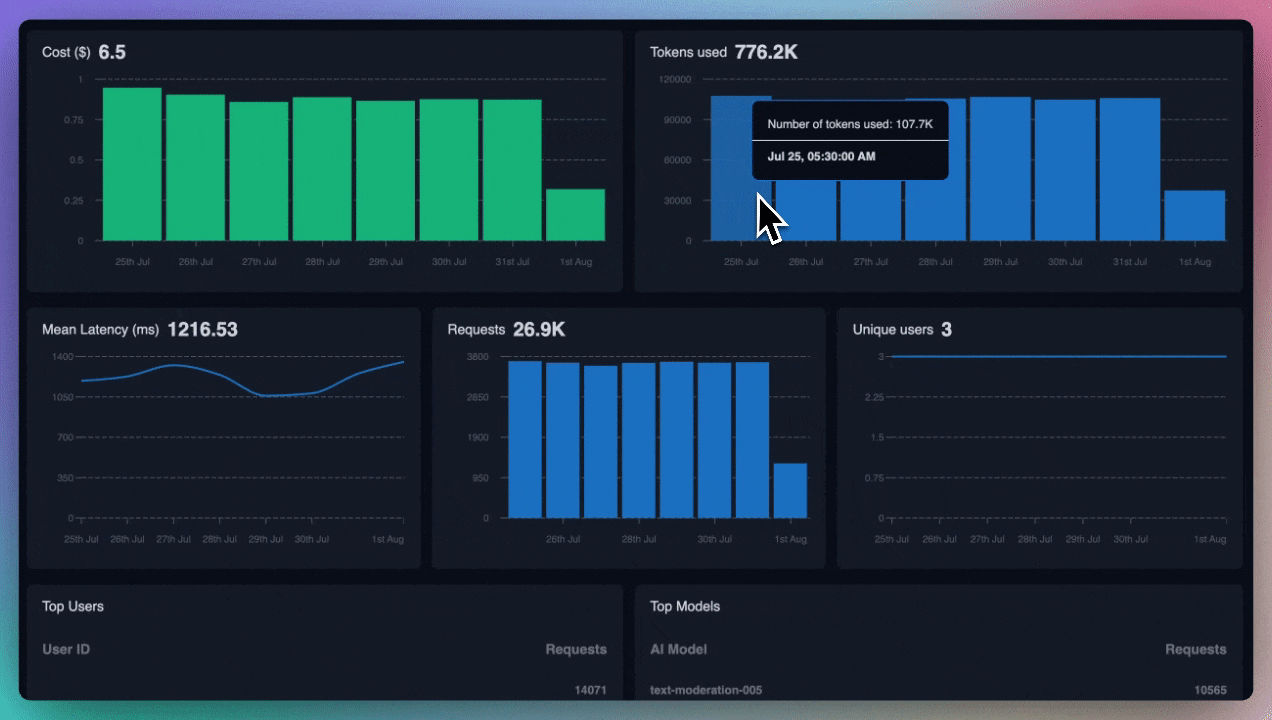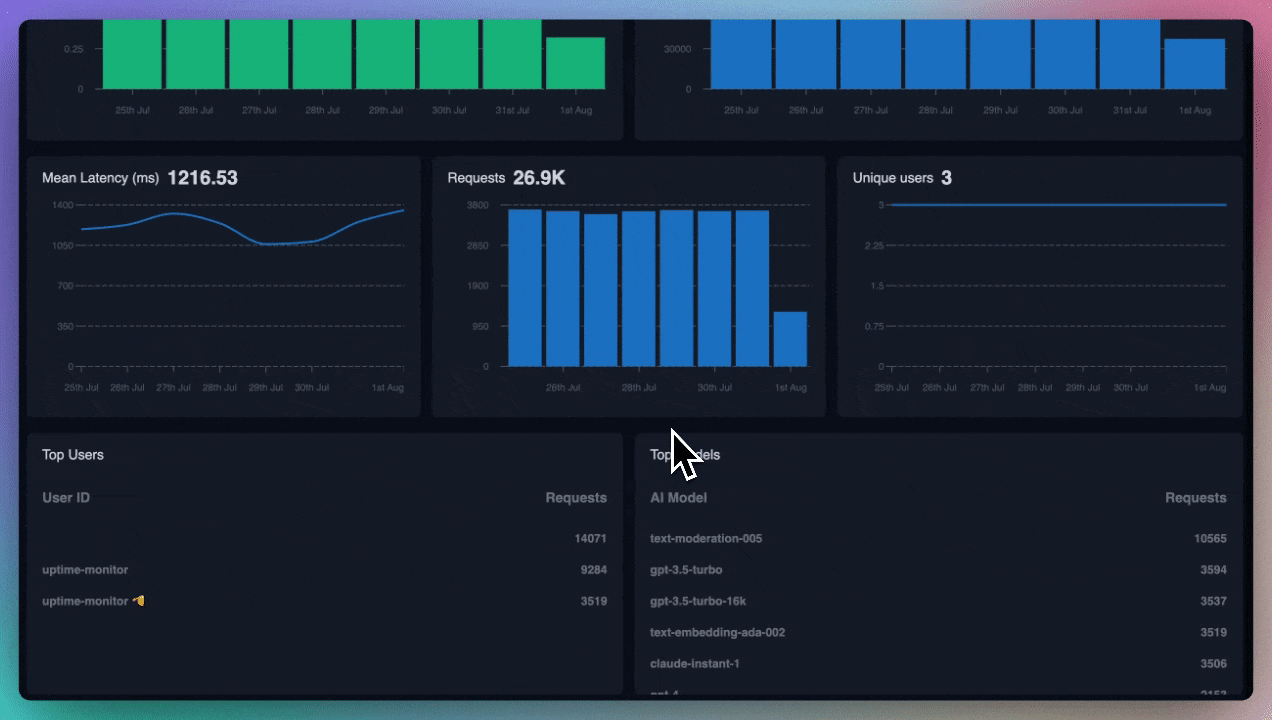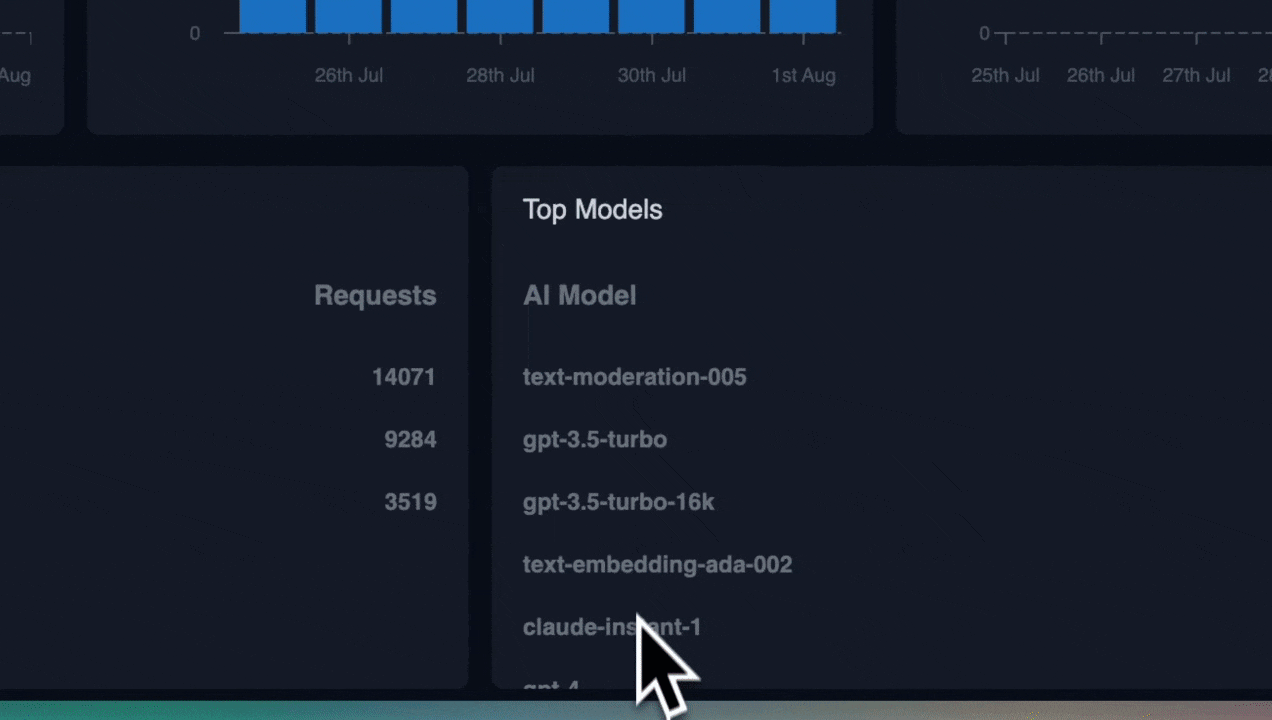
Now that you're logging request and response failures, set up alerts on your preferred channels. If these failures cross a certain threshold, you'll want to know right away for quicker debugging.
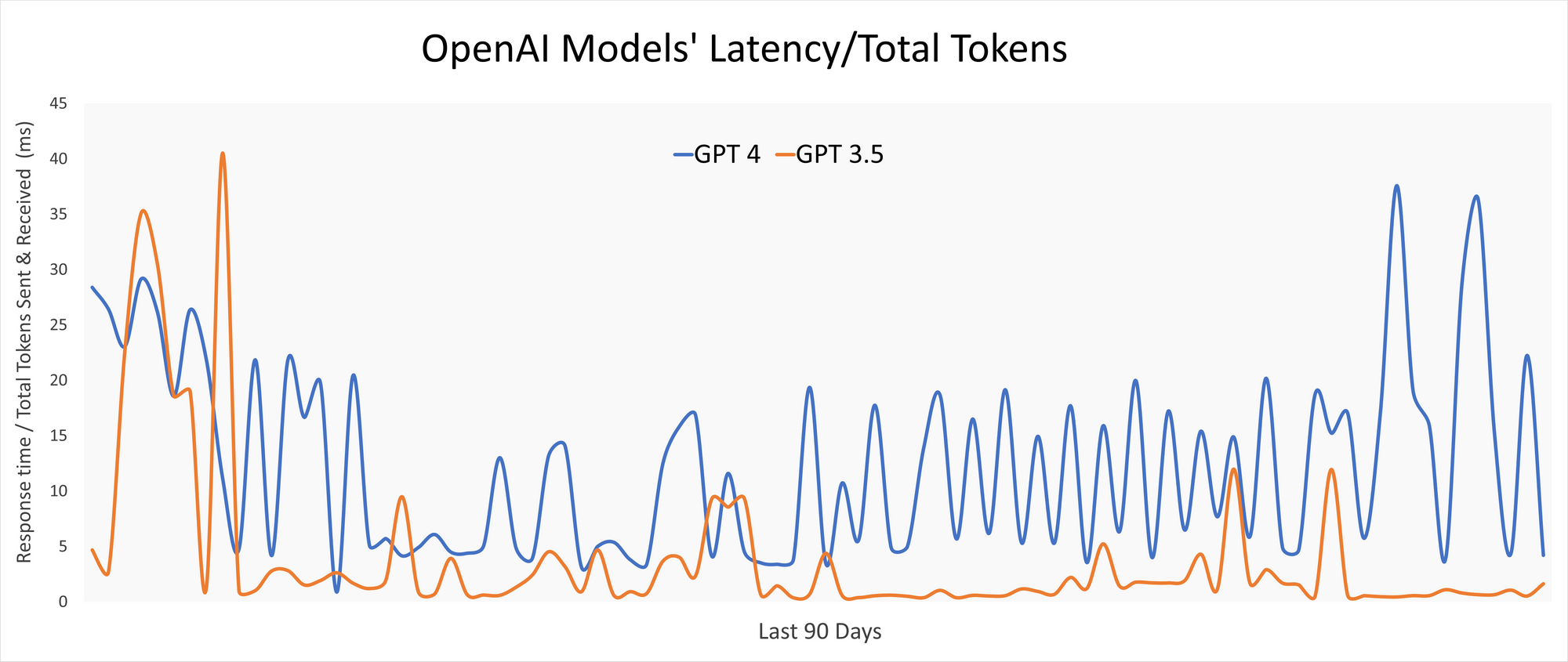
3. 📉 Monitor API Latencies
It's no secret that inference endpoints can be slower to respond than other APIs.
Which is why, it's important to monitor latency of these endpoints and take action when Apdex decreases.
While there is little to do to improve the latency of the APIs, here are 3 sure shot ways to improve user delight.
Introduce streaming: Streaming responses can greatly reduces the perceived latency of generation requests and many providers support this option. This is usually a quick change, but make sure you're able to log stream data as well.
Use smaller models for simpler tasks: You don't always need a trillion parameter model to generate email content or classify text. Instead consider using smaller, faster models which can save you both cost and latency. Consider using different (and some times multiple) models for different tasks.
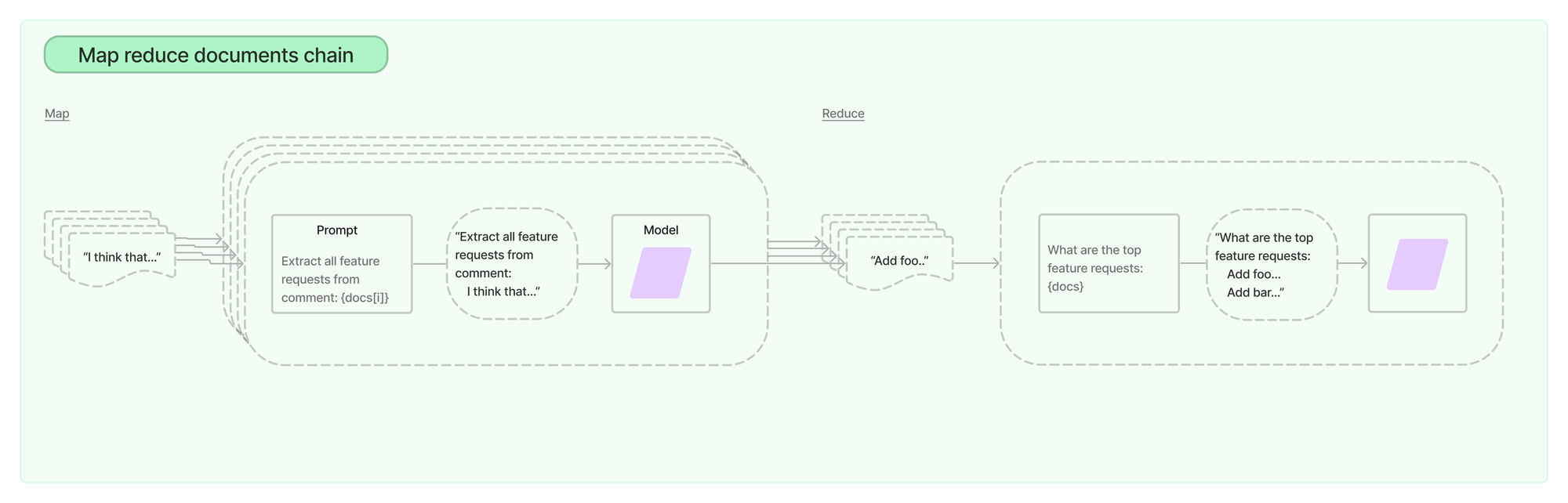
Make LLM requests in parallel: It’s well known that large prompts & completions will take way longer than shorter ones. Keeping your prompt short and limiting max_tokens can significantly speed up your app. Look for ways to parallelise your calls. So if you're summarising a large piece of text, a map-reduce can make your call really fast.
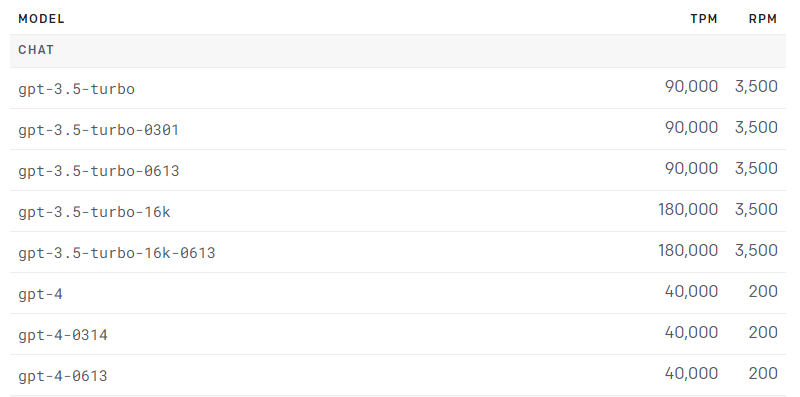
4. 🏎️ Handle Rate-Limits
Most LLM providers actively enforce rate-limits on their APIs. Building an app to absorb these HTTP 429 errors will go a long way in providing the best experience for your users.
The most common way to handle these rate limits is to add retry logic for your requests with an exponential back-off. Tenacity is the most popular library for Python users, and we've used Async-Retry from Vercel to great effect.
While, not so obvious initially, it is worthwhile to invest in user-level rate limiting as well. That way you can ensure fair usage of your API rate-limits across all your users. It's an investment that pays off in the long run by preventing any single user from dominating the request traffic.
5. 🛡️ Guard Against Abuse
At a previous company, we were attacked by bots and our API usage went through the roof.

If this happens to you, it causes 2 BIG problems:
- You end up paying your LLM provider a lot of money
- Your genuine users will start to see delays in processing since all your precious tokens are being used by bots!
The simplest way to avoid this is a captcha (I'm sure you thought of this!), but here are 2 more advanced solutions:
- User-level rate-limiting: As discussed above, implementing user-level rate limiting ensures fair usage across your user segments.
- IP fingerprinting: This advanced technique can help you identify and stop spammers more effectively. It might require a bit more effort to set up, but the added security is well worth it.
✅ So here’s the final game plan:
- Log and Analyse: Start by logging all your requests and responses. Consider investing in a specialised logging tool to handle large chunks of text without spiralling costs.
- Alerts for Failures: Don't wait for your users to tell you something's wrong. Set up alerts for both request and response level failures for quick issue resolution.
- Eye on the Clock: Keep a close watch on API latencies. Introduce streaming, use smaller models for simpler tasks, and parallelise your calls to improve performance.
- Navigating Rate Limits: Don't let HTTP 429 errors get in your way. Handle rate limits on both the LLM provider's side and on your user's end for a smoother user experience.
- Guard Against Abuse: Stay vigilant against potential abuse. Remember, a simple captcha or advanced techniques like user-level rate limiting and IP fingerprinting can save your day!
And there you have it, a comprehensive guide to ensuring your AI app stays highly reliable, even when the unexpected happens.