
Canary Testing for LLM Apps
Learn how to safely deploy LLM updates using canary testing - a phased rollout approach that lets you monitor real-world performance with a small user group before full deployment.
When you're working with large language models, testing takes on a whole new dimension of importance. LLMs don't behave like traditional software - a small change to your prompts, a new fine-tuning run, or an upgrade to the latest model version can suddenly shift performance in ways you didn't anticipate. These changes might lead to outputs you never expected or degrade the user experience without clear warnings.
This is where canary testing comes in. It gives you a way to safely introduce changes to your LLM applications by rolling out updates to just a small group of users first. By watching how your changes perform in real-world situations with this limited audience, you can spot and fix problems before they affect your entire user base.
What is canary testing?
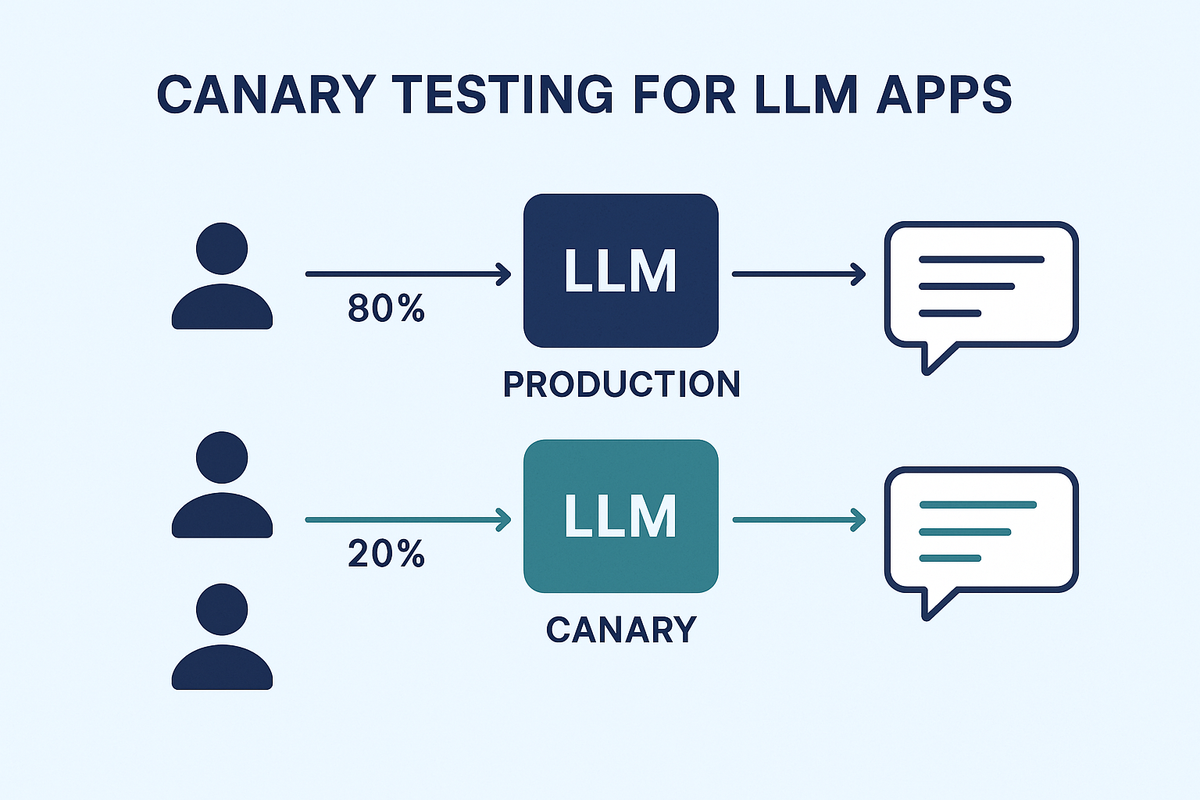
Canary testing works by sending a small portion of your user traffic to a new model or configuration while keeping most users on the stable version. This approach gives you several key advantages when working with LLMs.
First, it drastically reduces risk. If something goes wrong, only a small percentage of users are affected, not your entire customer base.
Second, you get to validate your changes in the real world. No matter how thorough your lab testing is, there's nothing like seeing how your model performs with actual users and real-world inputs.
Third, you can scale up gradually. Start with just 5% of traffic, then 10%, then 25% as you gain confidence in your new model's performance.
And if things go sideways, you can quickly redirect traffic back to the previous version, often with automated systems that detect performance issues.
Why is canary testing essential for LLM applications?
Deploying updates to LLM applications comes with unique challenges that traditional software doesn't face.
For one, these models can be wildly unpredictable. Something as small as rewording a prompt or adding new examples to your training data can completely change how the model responds to users.
Performance issues are another major concern. A model update might suddenly increase response times, use more tokens per request (driving up your costs), or start hallucinating facts more frequently.
If you're switching between API providers or upgrading to a newer model version, you're introducing even more variables. A pattern that worked perfectly with GPT-4 might behave differently with Claude, or even with the next version from the same provider.
With canary testing, you can make sure that LLM updates do not disrupt user experience, providing a controlled mechanism to review changes before full deployment.
How canary testing works for LLM apps
The canary testing process for LLM applications involves:
1. Routing a small percentage of user queries to the updated model.
2. Tracking response accuracy, latency, cost, hallucination rates, and user feedback.
3. Gradually increasing the percentage of traffic to the new version based on observed stability.
4. If KPIs degrade beyond acceptable limits, redirecting all traffic back to the previous model.
How Portkey helps with canary testing for LLM apps
Portkey's AI gateway makes canary testing straightforward with its load balancing features. You can easily set up traffic distribution by assigning different weights to your models - this controls the workload going to your new model versus your stable one.
{
"strategy": {
"mode": "loadbalance"
},
"targets": [
{
"virtual_key": "openai-virtual-key",
"weight": 0.95
},
{
"virtual_key": "anyscale-virtual-key",
"weight": 0.05,
"override_params": {
"model": "meta-llama/Llama-2-70b-chat-hf"
}
]
}
The best part? You can configure this directly on the Portkey platform without touching your application code. No need to deploy new versions of your app or modify your integration points.
Once your canary test is running, Portkey's observability tools let you track how the new model is performing. You can monitor critical metrics like cost per request, response latency, error rates, and user feedback all in one place.
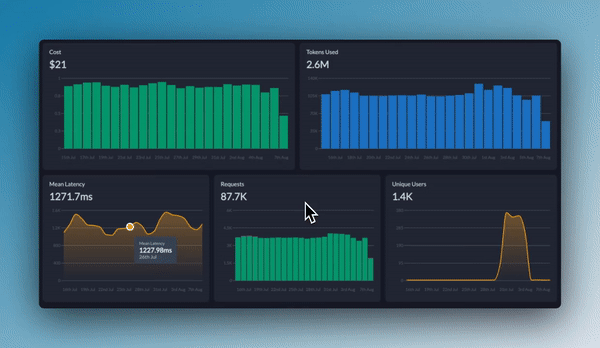
This combined approach gives you both the control to safely test new models and the visibility to make data-backed decisions about when to increase traffic or roll back changes.
Safe and reliable model updates
Canary testing gives LLM teams a safety net when releasing updates. By testing changes with a small group of real users first, you can catch problems early and protect your wider audience from unexpected issues.
Portkey takes the complexity out of this process with its built-in traffic routing capabilities and comprehensive monitoring dashboard. This makes it easier to deploy updates confidently, knowing you can quickly respond if metrics start trending in the wrong direction.
Ready to make your LLM deployments more reliable? Try Portkey today.

