
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models - Summary
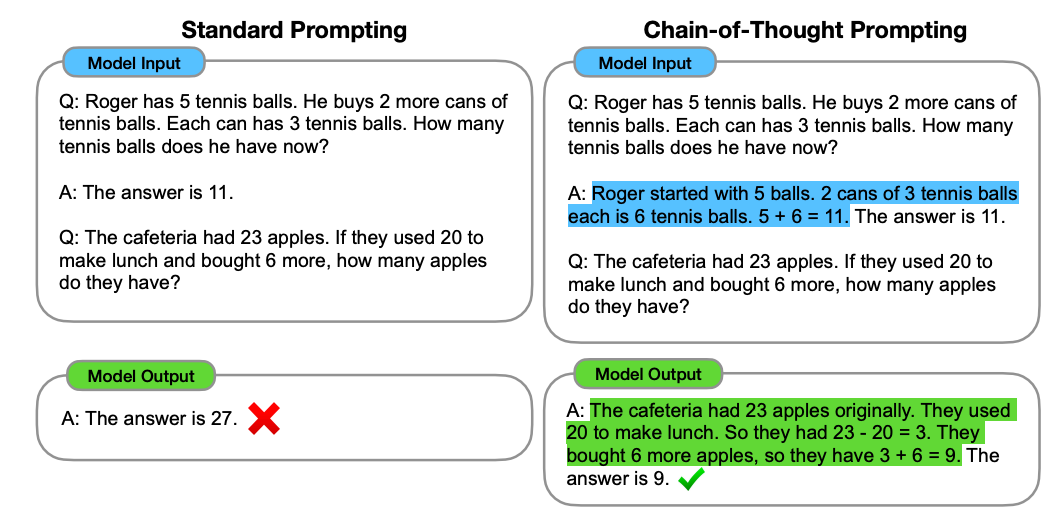
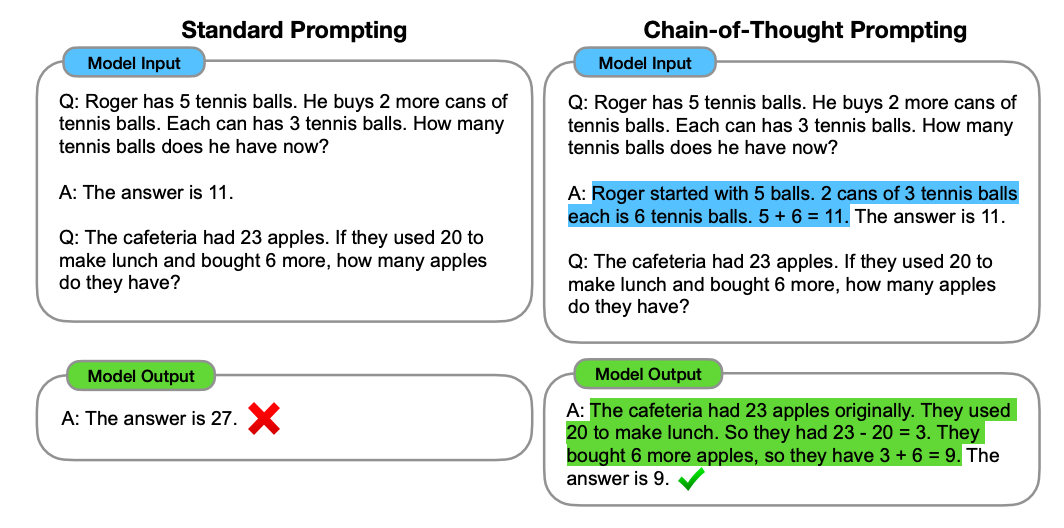
The paper explores how generating a chain of thought can improve the ability of large language models to perform complex reasoning. The authors introduce a simple method called chain-of-thought prompting, where a few chain of thought demonstrations are provided as exemplars in prompting. Experiment
Arxiv URL: https://arxiv.org/abs/2201.11903
Authors: Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc Le, Denny Zhou
Summary:
The paper explores how generating a chain of thought can improve the ability of large language models to perform complex reasoning. The authors introduce a simple method called chain-of-thought prompting, where a few chain-of-thought demonstrations are provided as exemplars in prompting. Experiments on three large language models show that chain-of-thought prompting improves performance on a range of arithmetic, commonsense, and symbolic reasoning tasks.
Key Insights & Learnings:
- Chain-of-thought prompting significantly improves the ability of large language models to perform complex reasoning.
- Reasoning abilities emerge naturally in sufficiently large language models via chain-of-thought prompting.
- Chain-of-thought prompting improves performance on a range of arithmetic, commonsense, and symbolic reasoning tasks.
- Prompting a PaLM 540B with just eight chain-of-thought exemplars achieves state-of-the-art accuracy on the GSM8K benchmark of math word problems, surpassing even finetuned GPT-3 with a verifier.
- Chain-of-thought prompting is a promising prompt engineering approach for facilitating reasoning, providing interpretability, and potentially applicable to any task that humans can solve via language.
What are the advantages?
- Requires no model fine-tuning - works with off-the-shelf language models
- Provides interpretable reasoning steps that show how the model reached its answer
- Generalizes across different types of reasoning tasks
- Enables models to adapt computation to problem complexity
Empirical results
- Tested on multiple models (PaLM, LaMDA, GPT-3) and multiple scales
- Showed consistent improvements over standard prompting
- Performance gains were largest on complex multi-step problems
- Facilitated out-of-distribution generalization on symbolic tasks
Limitations
- Only works with large models (smaller models produce incoherent reasoning)
- No guarantee of correct reasoning paths
- Performance varies based on prompt engineering
Terms Mentioned: Chain-of-thought prompting, Large language models, Arithmetic reasoning, Commonsense reasoning, Symbolic reasoning, Few-shot prompting, Math word problems, PaLM 540B, GSM8K benchmark, GPT-3
Technologies / Libraries Mentioned: Google Research, Neural Information Processing Systems (NeurIPS), arXiv

