⭐️ Ranking LLMs with Elo Ratings
Choosing an LLM from 50+ models available today is hard. We explore Elo ratings as a method to objectively rank and pick the best performers for our use case.

Large language models (LLMs) are becoming increasingly popular for various use cases, from natural language processing, and text generation to creating hyper-realistic videos.
Tech giants like OpenAI, Google, and Meta are all vying for dominance in the LLM space, offering their own unique models and capabilities. Stanford, AI21, Anthropic, Cerebras, Groq, and more companies also have very interesting projects coming live!
For text generation alone, nat.dev has over 20 models you can choose from.

Choosing a model for your use case can be challenging. You could just play it safe and choose ChatGPT or GPT-4o, but other models might be cheaper or better suited for your use case.
So how do you compare outputs?
Let's try leveraging the Elo rating system, originally designed to rank chess players, to evaluate and rank different LLMs based on their performance in head-to-head comparisons.
What are Elo ratings?
So, what are Elo ratings? They were created to rank chess players around the world. Players start with a rating between 1000 Elo (beginner) and 2800 Elo or higher (pros). When a player wins a match, their rating goes up based on their opponent’s Elo rating.
You might remember that scene from The Social Network where Zuck and Saverin scribble the Elo formula on their dorm window. Yeah, that’s the same thing we’re about to use to rank LLMs!
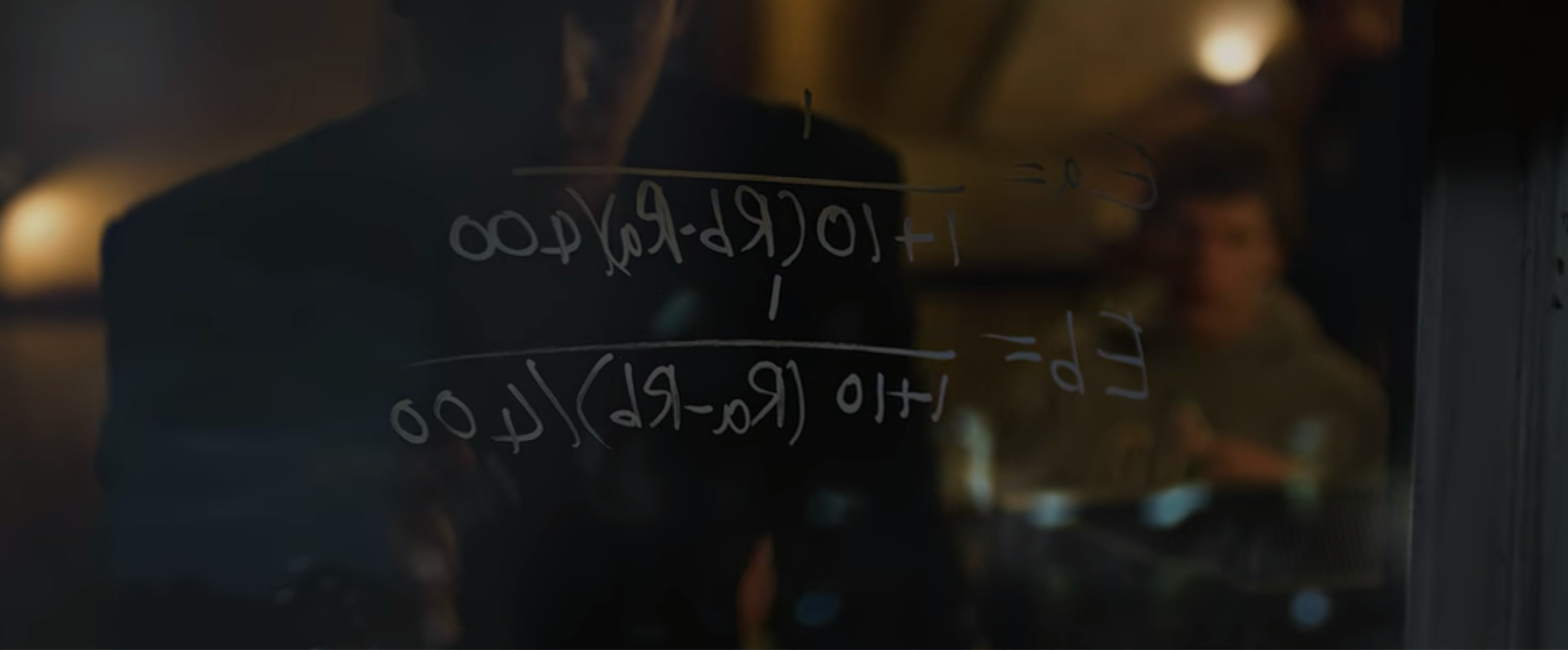
Here’s how it works: if you start with a 1000 Elo score and somehow beat Magnus Carlsen, who has a rating of 2882, your rating would jump 32 points to 1032 Elo, while his would drop 32 points to 2850.
The increase and decrease are based on a formula, but we won’t get too deep into the math here. Just know that there are libraries for all that stuff, and the Elo scoring system has been proven to work well. In fact, it’s likely used by large models for RLHF training of more command-based models like ChatGPT.
How to use Elo rating for ranking LLMs?
While traditional Elo ratings are designed for comparing two players, our goal is to rank multiple LLMs. To do this, we can adapt the Elo rating system, and we have Danny Cunningham’s awesome method to thank for that. With this expansion, we can rank multiple models at the same time, based on their performance in head-to-head matchups.
This adaptation allows us to have a more comprehensive view of how each model stacks up against the others. By comparing the models’ performances in various combinations, we can gather enough data to determine the most effective model for our use case.
Setting Up the Test
Alright, it’s time to see our method in action! We’re going to create “Satoshi tweets about …” using three different generation models to compare their performance. Our contenders are
- OpenAI's GPT-40
- OpenAI's O1
- Anthropic's Claude-3.5-sonnet
Each of these models will generate its own version of the tweet based on the same prompt.
To make things organized, we’ll save the outputs in a CSV file. The file will have columns for the prompt, OpenAI's GPT-40, O1, and Anthropic's Claude-3.5-sonnet, so it’s easy to see the results generated by each model. This setup will help us compare the different LLMs effectively and determine which one is the best fit for generating content in this specific scenario.
By conducting this test, we’ll gather valuable insights into each model’s capabilities and strengths, giving us a clearer picture of which LLM comes out on top.
Let’s Start Ranking
To make the comparison process smooth and enjoyable, we’ll create a simple user interface (UI) for uploading the CSV file and ranking the outputs. This UI will allow for a blind test, which means we won’t know which model generated each output. This way, we can minimize any potential bias while evaluating the results.

After we’ve made about six comparisons, we can start to notice patterns emerging in the rankings. (Six is a fairly small number, but then we did rig the test in the choice of our models 😉)
Here’s what’s going on in the background while you’re ranking the outputs:
- All models start with a base level of 1500 Elo: They all begin with an equal footing, ensuring a fair comparison.
- New ranks are calculated for all LLMs after each ranking input: As we evaluate and rank the outputs, the system will update the Elo ratings for each model based on their performance.
- A line chart identifies trends in ranking changes: Visualizing the ranking changes over time will help us spot trends and better understand which LLM consistently outperforms the others.

Here’s a code snippet to try out a simulation for multiple models:
%matplotlib inline
import numpy as np
import matplotlib.pyplot as plt
from multielo import MultiElo
# Initialize the Elo ratings and history
recipes = ['Model 1', 'Model 2', 'Model 3']
elo_ratings = np.array([1500, 1500, 1500])
elo_history = [np.array([1500]), np.array([1500]), np.array([1500])]
elo = MultiElo()
while True:
print("Please rank the recipes from 1 (best) to 3 (worst).")
ranks = [int(input(f"Rank for {recipe}: ")) for recipe in recipes]
# Update ratings based on user input
new_ratings = elo.get_new_ratings(elo_ratings, ranks)
# Update the rating history
for idx, rating in enumerate(new_ratings):
elo_history[idx] = np.append(elo_history[idx], rating)
elo_ratings = new_ratings
print("Current Elo Ratings:", elo_ratings)
plot_choice = input("Would you like to plot the Elo rating changes? (yes/no): ")
if plot_choice.lower() == 'yes':
for idx, recipe in enumerate(recipes):
plt.plot(elo_history[idx], label=recipe)
plt.xlabel("Number of Iterations")
plt.ylabel("Elo Rating")
plt.title("Elo Rating Changes")
plt.legend()
plt.show()
continue_choice = input("Do you want to continue ranking recipes? (yes/no): ")
if continue_choice.lower() == 'no':
breakWrapping Up the Test
We want to be confident in declaring a winner before wrapping up the A/B/C test. To reach this point, consider the following factors:
- Choose your confidence level: Many people opt for a 95% confidence level, but we can adjust it based on our specific needs and preferences.
- Keep an eye on Elo LLM ratings: As you conduct more and more tests, the differences in ratings between the models will become more stable. A larger Elo rating difference between the two options means you can be more certain about the winner.
- Carry out enough matches: It’s important to strike a balance between the number of matches and the duration of your test. You might decide to end the test when the Elo rating difference between the options meets your chosen confidence level.
What's next?
Conducting quick tests can help us pick an LLM, but we can also use real user feedback to optimize the model in real-time. By integrating this approach into our application, we'd be able to identify the winning and losing models as they emerge, adapting on the fly to improve performance.
We could also pick models for segments of a user base depending on the incoming feedback which can create different Elo ratings for different cohorts of users.
This could also be used as a starting point to identify fine-tuning and training opportunities for companies looking to get the extra edge from base LLMs.
While there are tons of ways to run A/B tests on LLMs, this simple Elo LLM rating method is a fun and effective way to refine our choices and make sure we pick the best option for our project.
Happy testing!