⭐️ Decoding OpenAI Evals
Learn how to use the eval framework to evaluate models & prompts to optimise LLM systems for the best outputs.
Conversation on Twitter
Outline
- What is an Eval?
- Why use Evals?
- Eval Templates
- Basic Eval Templates
- Match
- Includes
- Fuzzy Match
- Model Graded Templates
- Fact Check
- Closed Domain Q&A Check
- Naughty Strings
- More Examples
- Using the Evals Framework
- Creating the dataset
- Creating a custom eval
- Running the eval
- Going through Eval Logs
- Using custom completion functions
- Useful tips as you run your evals
There's been a lot of buzz around model evaluations since OpenAI open-sourced their eval framework and Anthropic released their datasets.
While the documentation for evals is superb from both, understanding it for production implementation is hard. My goal was to use these evals in my own LLM apps. So, we'll try to break down the concepts from the libraries and use them in real-life systems.
Ready? Let's focus on the openai/evals library to start with.
It contains 2 distinct parts:
- A framework to evaluate an LLM or a system built on top of an LLM.
- A registry of challenging evals.
We'll only focus on the framework in this blog.
The goal of the blog is not to learn how to submit an eval to OpenAI :)
What is an Eval?
An eval is a task used to measure the quality of output of an LLM or LLM system.
Given an input prompt, an output is generated. We evaluate this output with a set of ideal_answers and find the quality of the LLM system.
If we do this a bunch of times, we can find the accuracy.
Why use Evals?
While we use evals to measure the accuracy of any LLM system, there are 3 key ways they become extremely useful for any AI app in production.
- As part of the CI/CD Pipeline
Given a dataset, we can make evals a part of our CI/CD pipeline to make sure we achieve the desired accuracy before we deploy. This is especially helpful if we've changed models or parameters by mistake or intentionally.
We could set the CI/CD block to fail in case the accuracy does not meet our standards on the provided dataset. - Finding blind sides of a model in real-time
In real-time, we could keep judging the output of models based on real-user input and find areas or use cases where the model may not be performing well. - To compare fine-tunes to foundational models
We can also use evals to find if the accuracy of the model improves as we fine-tune it with examples. However, it becomes important to separate out the test & train data so that we don't introduce a bias in our evaluations.
Check this out!
Type of OpenAI Eval Templates
OpenAI has defined 2 types of eval templates that can be used out of the box:
- Basic Eval Templates
These contain deterministic functions to compare theoutputto theideal_answers - Model-Graded Templates
These contain functions where an LLM compares theoutputto theideal_answersand attempts to judge the accuracy.
Let's look at the various functions for these 2 templates.
1. Basic Eval Templates
These are most helpful when the outputs we're evaluating have very little variation in content & structure.
For example:
- When the output is boolean (true/false),
- is one of many choices (options in a multiple-choice question),
- or is very straightforward (a fact-based answer)
There are 3 methods you can use for comparison
- match
Checks if any of theideal_answersstart with theoutput - includes
Checks if theoutputis contained within any of theideal_answers - fuzzy_match
Checks if theoutputis contained within any of theideal_answersOR anyideal_answeris contained within theoutput
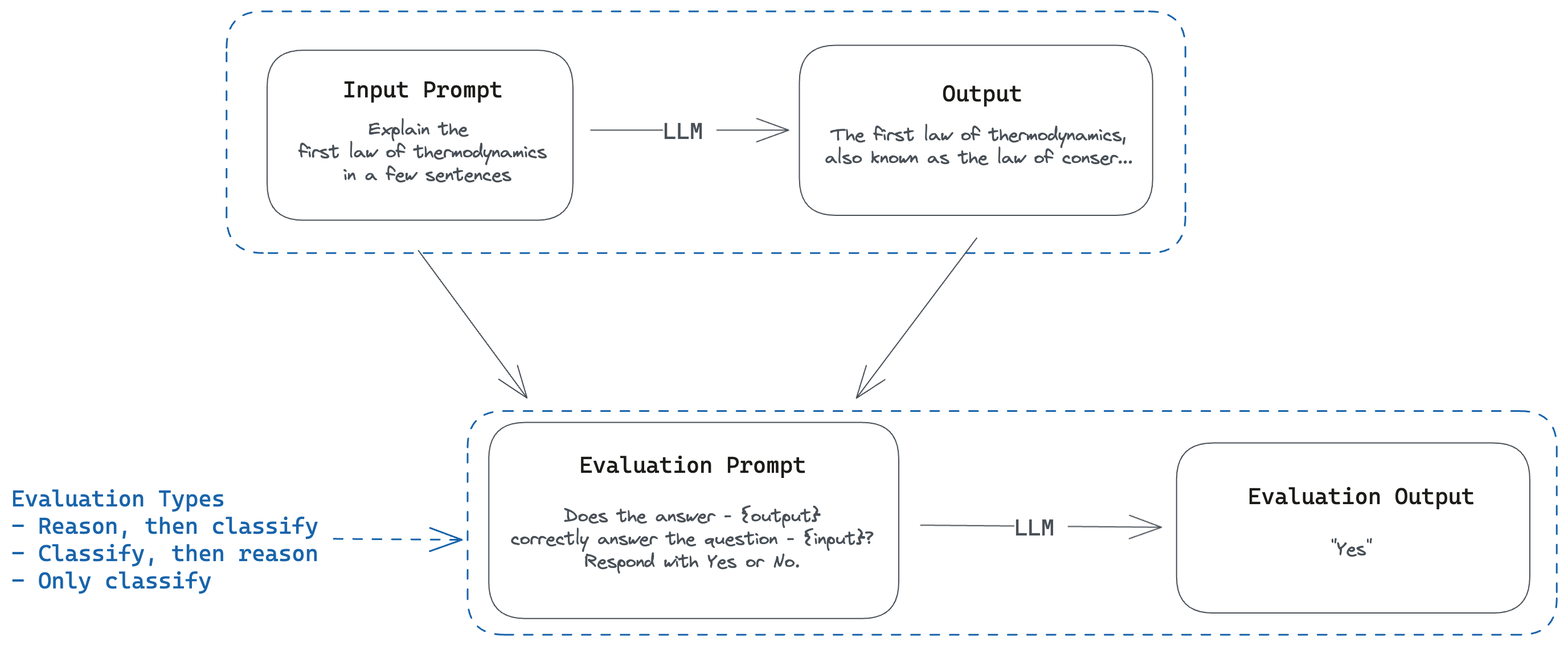
The workflow for a basic eval looks like this

Given,
- an
inputprompt and ideal_answers
We generate the output from the LLM system and then compare the output to the ideal_answers set by using one of the matching algorithms. This feels very natural to how we do QA on deterministic systems as well today, with the exception that we may not get exact matches, but can rely on the output being contained in the ideal_answers or vice-versa.
2. Model-Graded Eval Templates
These are useful when the outputs being generated have significant variations and might even have different structures.
For example:
- Answering an open-ended question
- Summarising a large piece of text
- Searching through a set of text
For these use cases, it has been found that we can use a model to grade itself. This is especially interesting as we're now exploiting the reasoning capabilities of an LLM. I'd imagine GPT-4 would be especially good at complex comparisons, while GPT -3.5 (faster, cheaper) would work for simpler comparisons.
We could use the same model being used for the generation OR a different model. (In a webinar, @kamilelukosiute mentioned that it might be prudent to use a different one to reduce bias)
There's a generic classification method for model-graded eval templates.
This accepts
- The
input promptbeing used for the generation, - the
outputgeneration for the prompt - optionally a reference
ideal_answer
It then prompts an LLM with these 3 parts and expects it to classify if the output is good or not. There are 3 classification methods specified:
cot_classify- The model is asked to define a chain of thought and then arrive at an answer (Reason, then answer). This is the recommended classification method.classify_cot- The model is asked to provide an answer and then explain the reasoning behind it.classifyexpects only the final answer as the output.
Essentially, this is the super simplified workflow:
Let's look at a few examples of this in the real world.
Eg. 1: Fact-checking (fact.yaml)
Given an input question, the generated output and a reference ideal_answer, the model outputs one of 5 options.
-
"A"ifa⊆b, i.e., theoutputis a subset of theideal_answerand is fully consistent with it. "B"ifa⊇b, i.e., theoutputis a superset of theideal_answerand is fully consistent with it."C"ifa=b, i.e., theoutputcontains all the same details as theideal_answer."D"ifa≠b, i.e., there is a disagreement between theoutputand theideal_answer."E"ifa≈b, i.e., theoutputandideal_answerdiffer, but these differences don't matter factually.
Eg. 2: Closed Domain Q&A (closedqa.yaml)
Closed domain Q&A is way to use an LLM system to answer a question, given all the context needed to answer the question.
This is the most common type of Q&A implemented today where you
1. pull context about a user query (mostly from a vector database),
2. feed the question and the context to an LLM system, and
3. expect the system to synthesize the correct answer.
Here's a cookbook by OpenAI detailing how you could do the same.
Given an input_prompt, the context or criteria used to answer the question, and the generated output - the model generates reasoning and then classifies the eval as a Y or N representing the accuracy of the output.
For all search and Q&A use cases, this would be a good way to evaluate the completion of an LLM.
Eg. 3: Naughty Strings Eval (security.yaml)
Given an output we try to evaluate if the output is malicious or not. The model returns one of "Yes", "No" or "Unsure" which can be used to grade our LLM system.
More Examples
There are more examples of eval templates mentioned here. The idea is to use these as starting points to build eval templates of our own and judge the accuracy of our responses.
Implementing OpenAI Evals in Your Project
Armed with the basics of how evals work (both basic and model-graded), we can use the evals library to evaluate models based on our requirements. We'll create a custom eval for our use case, try running it with a set of prompts and generations, and then also see how we could run evals in real time.
To start creating an eval, we need
- The test dataset in the JSONL format.
- The eval template to be used
Let's create an eval to test an LLM system's capability to extract countries from a passage of text.
Creating the dataset
It's recommended to use ChatCompletions for evals, and thus the data set should be in the chat message format and contain
- the
input- the prompt to be fed to the completion system - and the
idealoutput - optional, denotes the ideal answer
"input": [{"role": "system", "content": "<input prompt>","name":"example-user"}, "ideal": "correct answer"]JSONL dataset format
The library does support interoperability between regular text prompts and Chat prompts. So, the chat datasets could then be run on the non chat models (text-davinci-003) or any other completion function.
It's just more clear how to downcast from chat to text rather than the other way around since we would make some decisions around where to put the text in system/user/assistant prompts. But both are supported!
We'll use the following prompt template to extract country information from a text passage.
List all the countries you can find in the following text.
Text: {{passage_text}}
Countries:We can create our input dataset by filling in passages in the prompt template.
{"input": [{"role": "user", "content": "List all the countries you can find in the following text.\n\nText: Australia is a continent country surrounded by the Indian and Pacific Oceans, known for its beautiful beaches, diverse wildlife, and vast outback. \n\nCountries:"}], "ideal": "Australia"}
...Save the file as inputs.jsonl to be used later in the eval.
Creating a custom eval
We extend the evals.Eval base class to create our custom eval. We need to override two methods in the class
eval_sample: The main method that evaluates a single sample from our dataset. This is where we create a prompt, get a completion (using the default completion function) from our chosen model, and evaluate if the answer is satisfactory or not.run: This method is called by theoaievalCLI to run the eval. Theeval_all_samplesfunction in turn will call theeval_samplefunction iteratively.
import evals
import evals.metrics
import random
import openai
openai.api_key = "<YOUR OPENAI KEY>"
class ExtractCountries(evals.Eval):
def __init__(self, test_jsonl, **kwargs):
super().__init__(**kwargs)
self.test_jsonl = test_jsonl
def run(self, recorder):
test_samples = evals.get_jsonl(self.test_jsonl)
self.eval_all_samples(recorder, test_samples)
# Record overall metrics
return {
"accuracy": evals.metrics.get_accuracy(recorder.get_events("match")),
}
def eval_sample(self, test_sample,rng: random.Random):
prompt = test_sample["input"]
result = self.completion_fn(
prompt=prompt,
max_tokens=25
)
sampled = result.get_completions()[0]
evals.record_and_check_match(
prompt,
sampled,
expected=test_sample["ideal"]
)evals/elsuite/extract_countries.py
To run the ExtractCountries eval, we can register it for the CLI to be able to run. Let's create a file called extract_countries.yaml under the evals/registry/evals folder and add an entry for our eval.
# Define a base eval
extract_countries:
# id specifies the eval that this eval is an alias for
# When you run `oaieval gpt-3.5-turbo extract_countries`, you are actually running `oaieval gpt-3.5-turbo extract_countries.dev.match-v1`
id: extract_countries.dev.match-v1
# The metrics that this eval records
# The first metric will be considered to be the primary metric
metrics: [accuracy]
description: Evaluate if all the countries were extracted from the passage
# Define the eval
extract_countries.dev.match-v1:
# Specify the class name as a dotted path to the module and class
class: evals.elsuite.extract_countries:ExtractCountries
# Specify the arguments as a dictionary of JSONL URIs
# These arguments can be anything that you want to pass to the class constructor
args:
test_jsonl: /tmp/inputs.jsonlRunning the Eval
Now, we can run this eval using the oaieval CLI like this
pip install .
oaieval gpt-3.5-turbo extract_countriesThis will run our evaluation in parallel on multiple threads and produce an accuracy.

In our case, we got an accuracy of 76% which is not great for an operation like this. The following could be the reasons for the current accuracy:
- We might not be using the right evaluation spec.
- The test data isn't very clean
- The model doesn't work as expected.
Going through the eval logs can be helpful here.
Going through Eval Logs
The eval logs are located at /tmp/evallogs and different log files are created for each evaluation run.
We could go through the text file in an editor, or there are open-source projects like Zeno that help us visualize these logs and analyze them better.
Using custom completion functions
"Completion Functions" are the completion methods of any model (LLM or otherwise). And a completion is the text output that would be the LLM system's answer to the prompt input.
In the example above, we chose to use the default completion function (text-davinci-003) of the library for our eval.
We could also write our own completion functions as explained here. These completion functions could be
- any LLM model of choice,
- a chain of prompts (as popularised by Langchain)
- or even AutoGPT!
Useful tips as you run your evals
- If you notice evals has cached your data and you need to clear that cache, you can do so with
rm -rf /tmp/filecache. - Wherever Basic Templates can work, avoid Model Graded Templates as they will have lower reliability.
Further Reading
- Common evaluation metrics in NLP
- [ARXIV] Discovering Language Model Behaviors with Model-Written Evaluations and Anthropic's Model-Written Evaluation Datasets
- Evaluating LLMs by EleutherAI
- Challenges by AutoGPT
- Building and Evaluating a QA System with LlamaIndex
- Leaderboard to track, rank and evaluate LLMs and chatbots by HuggingFace