Failover routing strategies for LLMs in production
Learn why LLM reliability is fragile in production and how to build resilience with multi-provider failover strategies with an AI gateway.
If you’re running LLMs in production, you’ve seen them fail. Providers go down, rate limits kick in, responses time out, or latency suddenly spikes. These aren’t edge cases; they happen often enough to break user trust and disrupt business workflows.
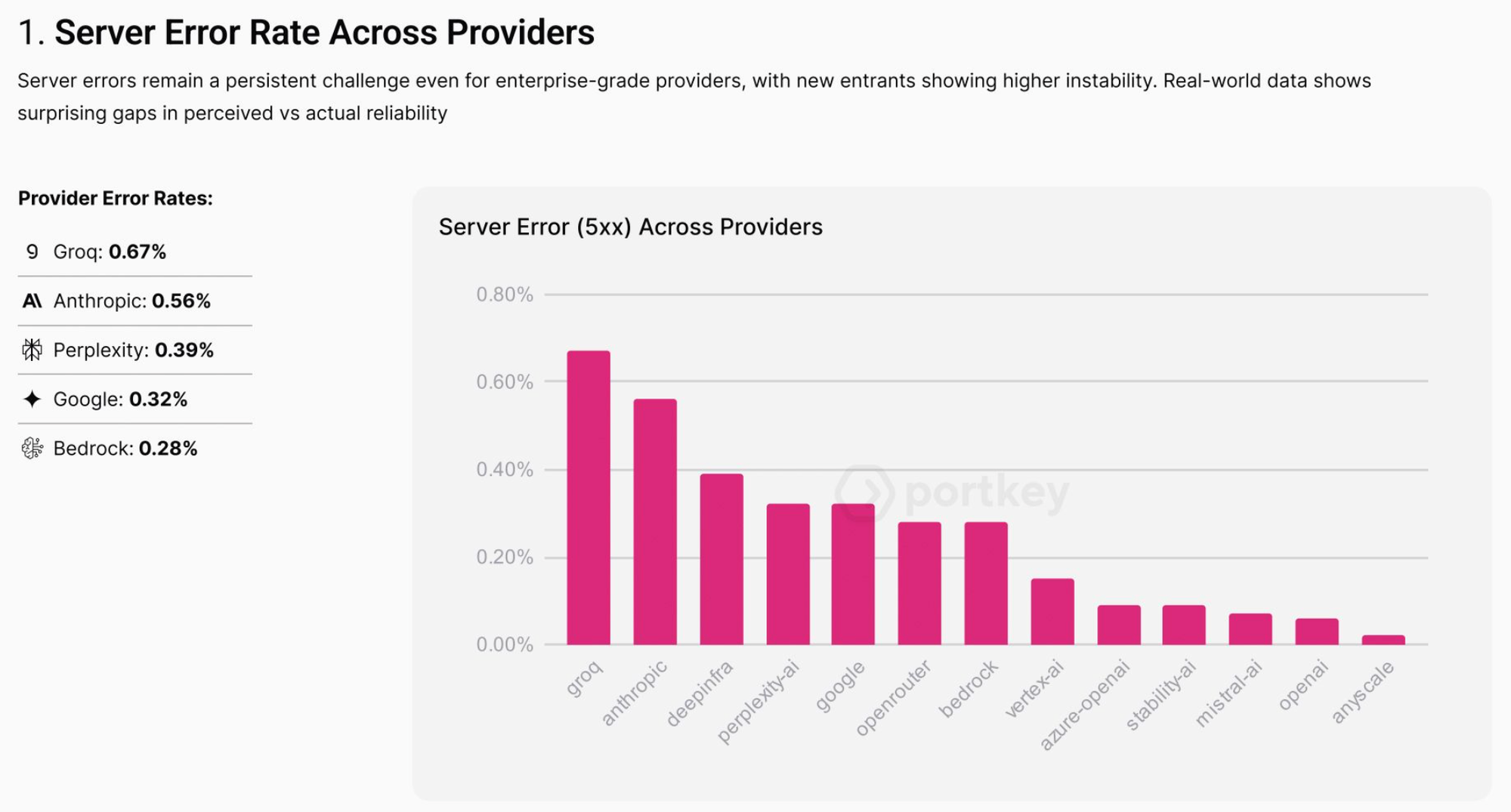
A 500 error in a live app doesn’t just look bad, it forces retries, slows down end-users, and cascades into support tickets. Even with “99.99% uptime,” that still adds up to 52 minutes per year, plenty of time to cause friction at scale.
(Source: Uptime Calculator)
The reality: LLM reliability is still fragile, and every outage or delay surfaces directly to your users.
Check this out!
Delay is the new downtime
When people think of outages, they picture a provider going dark. But in production AI apps, reliability issues often show up more subtly: as delays.
A chatbot that takes 6–8 seconds to respond feels broken, even if the API technically succeeded. For a customer support workflow, that delay means a longer handle time. For a trading or healthcare assistant, it can mean decisions that arrive too late to be useful.
The stakes are high because users equate delay with failure. Just like downtime makes a web app unusable, slow LLM responses make AI features feel unreliable. And unlike classic SaaS, where a few seconds might be tolerable, conversational and real-time AI experiences demand near-instant responsiveness.
This is why teams increasingly treat latency thresholds the same way they treat errors: if a response doesn’t come back fast enough, it’s effectively a failure.
Why multiple providers are a thumb rule for scale
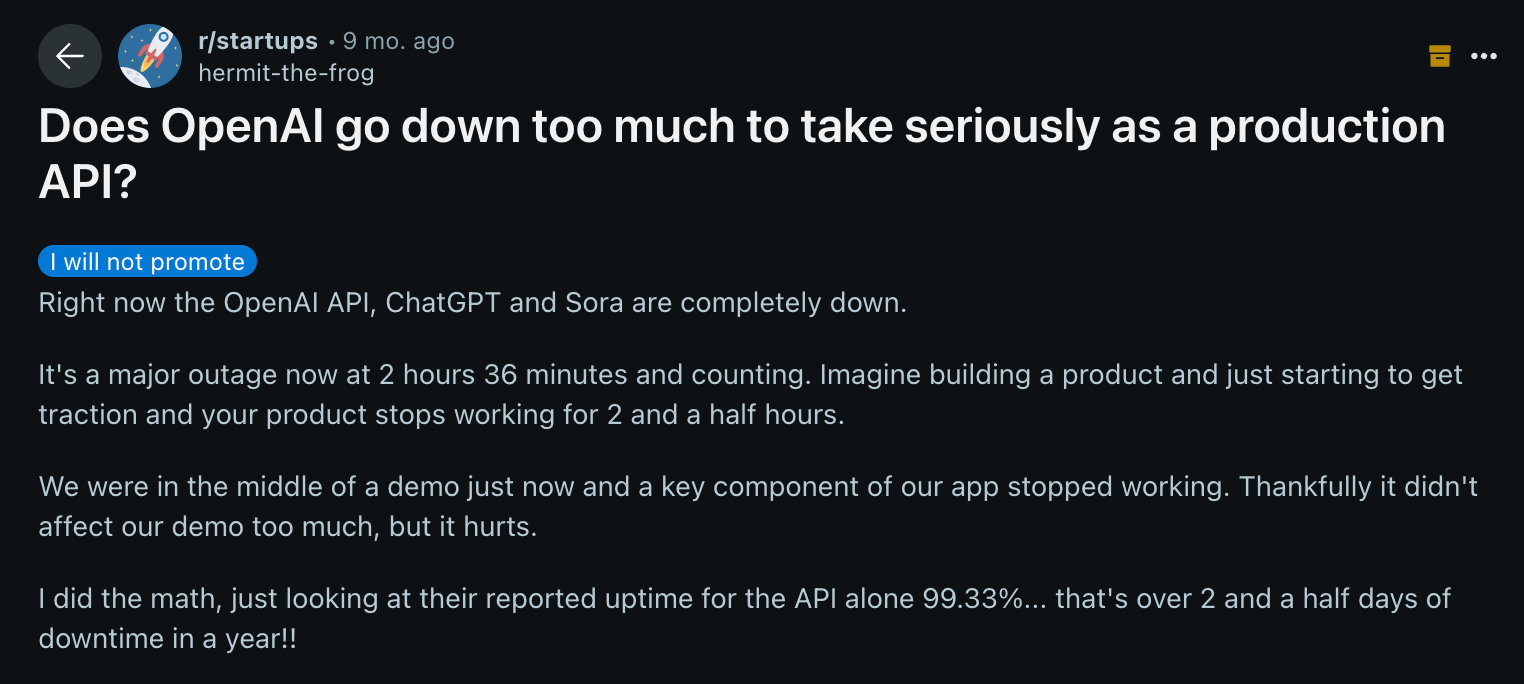
In early prototypes, it’s common to build on a single LLM provider. But once you move to production and start handling real traffic at scale, relying on just one quickly becomes risky.
- Single point of failure: If that provider goes down, your entire application stalls.
- Scaling bottlenecks: Rate limits can cap how many requests you can process, slowing adoption.
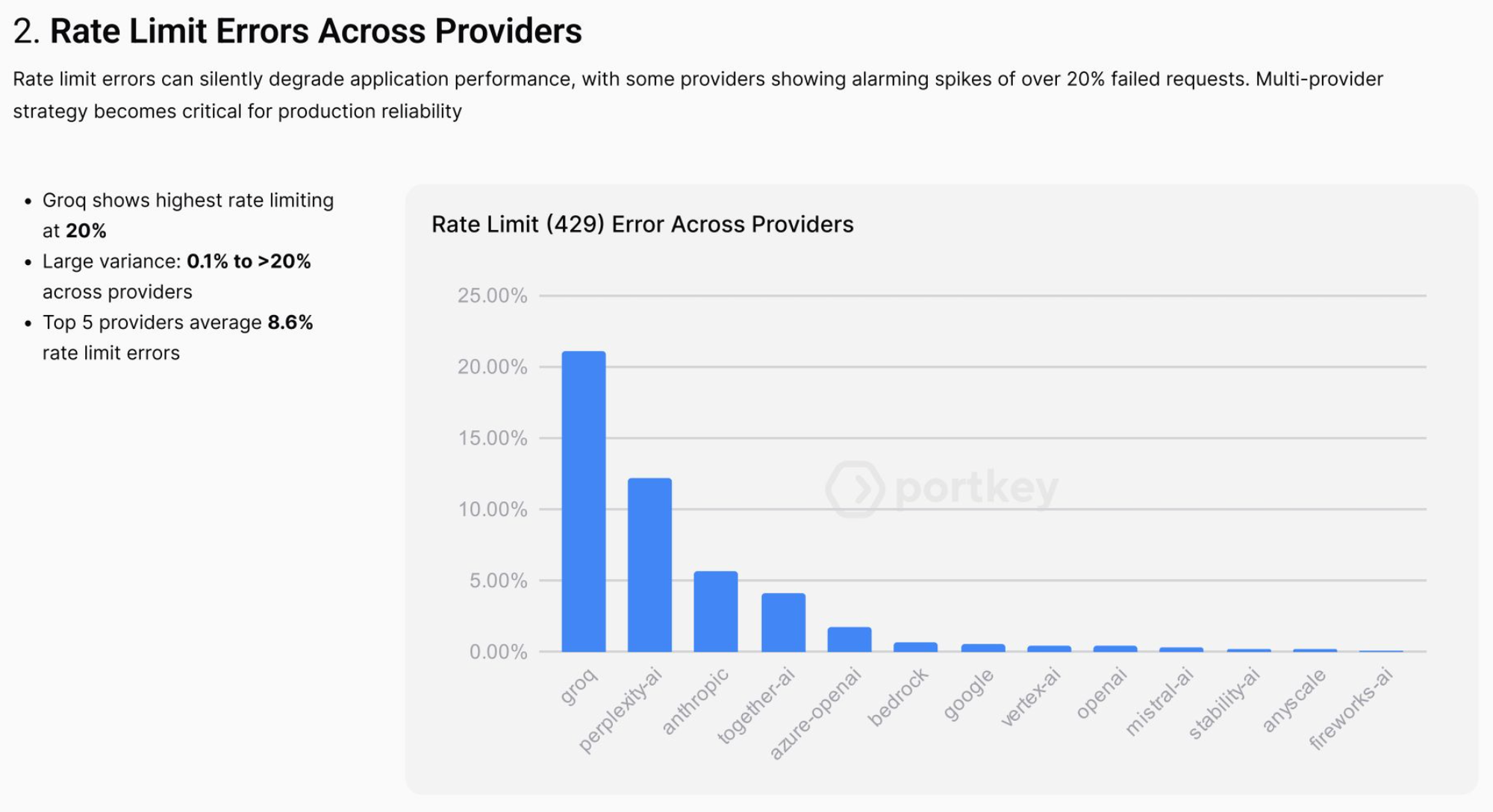
- Cost exposure: You’re locked into one pricing model, with no room to optimize workloads.
- Feature gaps: Different providers excel at different tasks — e.g., some models are cheaper for classification, others stronger for reasoning.
Enterprises that process millions of requests daily almost always hedge across two or more providers. This isn’t just about reliability and resilience + flexibility. By default, traffic can be split or routed intelligently so no single vendor becomes a choke point.
In practice, using multiple providers is less a “nice to have” and more a baseline design principle for production AI systems.
LLM failover routing strategies
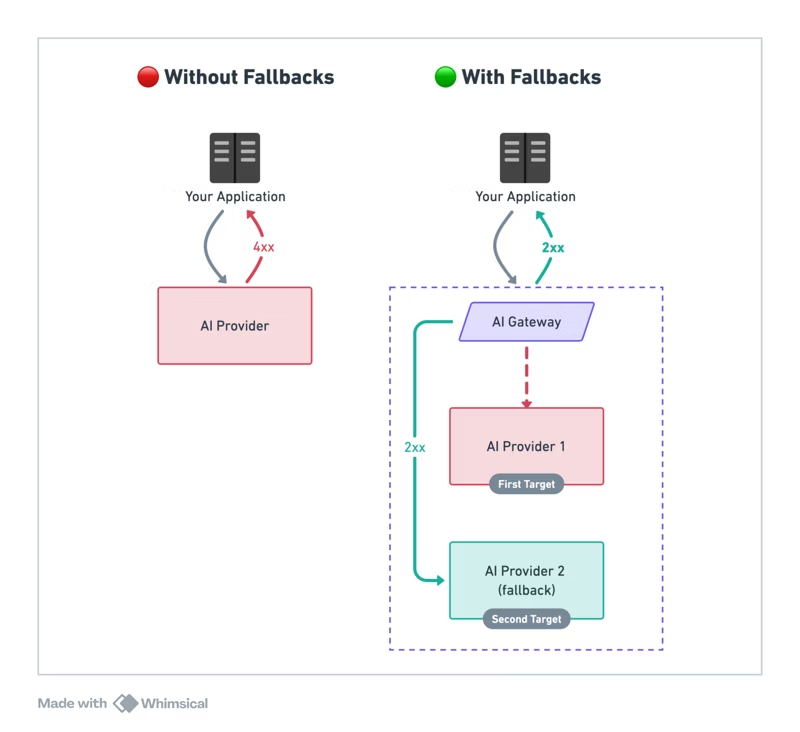
Once you acknowledge that failures and delays are inevitable, the question becomes: how do you design around them? That’s where failover strategies come in. Instead of treating the LLM as a single point of failure, you set rules for when and how to route traffic across multiple providers.
1. Failover on primary provider failure
The most straightforward strategy: if your primary LLM provider is down or returns an error, automatically retry on a backup provider.
- Example: If GPT-4o returns a 503 Service Unavailable, the same request is instantly re-sent to Claude 3.5 Sonnet.
- Benefit: Keeps your app live during outages.
- Trade-off: If done sequentially (wait → retry), users may see longer latency. Some teams run requests in parallel to minimize this.
2. Failover on status codes
Not all failures are total outages. LLM providers return status codes that can trigger specific actions:
- 429 Too Many Requests (rate limit): Instantly reroute traffic to a secondary provider.
- 500-level errors: Retry on another provider instead of exposing the error to the user.
- Guardrail failures: If a model returns unsafe or toxic content flagged by a moderation layer, the request can be retried with another provider or model.
3. Failover on latency thresholds
Sometimes the model responds, but too slowly to be acceptable. In those cases, you can set latency thresholds.
- Example: If the first provider hasn’t responded within 2 seconds, trigger the same request on a second provider. Whichever comes back first is returned to the user.
- Benefit: Users don’t wait 8 seconds staring at a spinner.
- Trade-off: Higher infra costs, since you may be running duplicate requests.
4. Distributing workload across providers
Failover doesn’t only have to be reactive. Proactive distribution of requests can reduce risk:
- Split traffic across providers (e.g., 70% OpenAI, 30% Anthropic).
- Optimize for cost by routing low-priority tasks to cheaper models, and high-priority ones to premium models.
- Reduce blast radius of a single provider outage.
With these strategies, teams move from being at the mercy of a single provider to running resilient, multi-provider AI systems.
Why DIY failover routing is hard
On paper, failover sounds simple: check if the provider fails, and if so, retry elsewhere. In practice, building it yourself quickly gets messy.
- Complex routing logic: You need to handle dozens of edge cases — different error codes, timeout handling, latency cutoffs, and guardrail violations.
- Provider differences: Every LLM API has slightly different error formats, rate-limit rules, and response structures. Normalizing them takes work.
- Observability gaps: Without centralized logs, it’s hard to know when failover was triggered, how often, or what it cost.
- Operational overhead: Teams end up writing custom wrappers, managing queues, and maintaining glue code, all of which grows brittle as usage scales.
Most engineering teams don’t want to reinvent a distributed routing layer. They want reliability without the overhead of building and maintaining it in-house. That’s where platforms like Portkey come in.
How Portkey makes failover simple
Portkey's LLM gateway gives you a unified way to manage multiple providers without adding operational complexity. Instead of juggling different SDKs, auth tokens, and error formats, you connect once through Portkey’s single, unified API.
From there, you can route requests to specific models based on rules and conditions, without rewriting your application code.
1. Failover on primary provider failure
If your primary provider goes down or throws a server error, Portkey automatically retries on your backup.
{
"strategy": {
"mode": "fallback"
},
"targets": [
{
"provider":"@openai-virtual-key",
"override_params": {
"model": "gpt-4o"
}
},
{
"provider":"@anthropic-virtual-key",
"override_params": {
"model": "claude-3.5-sonnet-20240620"
}
}
]
}2. Failover on status codes
Handle rate limiting (429), provider errors (500s), or custom codes with automatic failover to alternate providers.
{
"strategy": {
"mode": "fallback",
"on_status_codes": [ 429 ]
},
"targets": [
{
"provider":"@openai-virtual-key"
},
{
"provider":"@azure-openai-virtual-key"
}
]
}3. Failover on latency thresholds (Request Timeouts)
Unpredictable latency is one of the hardest issues in production. In your routing logic, set a maximum duration for a response. If the provider exceeds that threshold, the request is automatically terminated and retried elsewhere, ensuring your users never feel stuck waiting.
import Portkey from 'portkey-ai';
const portkey = new Portkey({
apiKey: "PORTKEY_API_KEY",
requestTimeout: 3000
})
const chatCompletion = await portkey.chat.completions.create({
messages: [{ role: 'user', content: 'Say this is a test' }],
model: '@openai/gpt-4o-mini',
});
console.log(chatCompletion.choices);4. Load balancing and conditional routing
Portkey also supports distribution of workloads. You can balance traffic across multiple providers, split based on cost or performance, or apply fine-grained conditions (e.g., “use cheaper model for summarization, premium model for reasoning”).
{
"strategy": {
"mode": "conditional",
"conditions": [
{
"query": { "metadata.user_plan": { "$eq": "paid" } },
"then": "finetuned-gpt4"
},
{
"query": { "metadata.user_plan": { "$eq": "free" } },
"then": "base-gpt4"
}
],
"default": "base-gpt4"
},
"targets": [
{
"name": "finetuned-gpt4",
"provider": "@xx",
"override_params": {
"model": "ft://gpt4-xxxxx"
}
},
{
"name": "base-gpt4",
"provider": "@yy",
"override_params": {
"model": "gpt-4"
}
}
]
}With these strategies, Portkey abstracts away the heavy lifting of building and maintaining your own routing system. You configure once, and Portkey guarantees reliability across providers, at scale.
Make your apps resilient
Reliability is the dividing line between an AI demo and a production-ready AI application.

Outages, rate limits, and latency spikes are inevitable when working with LLMs, but they don’t have to break your user experience.
By using multiple providers and applying smart failover strategies, you can make sure your applications keep running smoothly, no matter what’s happening with individual models.
Portkey's AI gateway gives you this resilience out of the box: one unified API, multiple providers, and built-in routing strategies for failover, timeouts, and load balancing. Instead of building custom wrappers and patchwork retries, you get a production-grade reliability layer ready to use from day one.
Ready to make your AI apps resilient? Book a demo with Portkey.