
FinOps practices to optimize GenAI costs and maximize efficiency
Learn how to apply FinOps principles to manage your organization's GenAI spending. Discover practical strategies for budget control, cost optimization, and building sustainable AI operations across teams. Essential reading for technology leaders implementing enterprise AI.

A growing tech startup rolls out an AI-powered customer service chatbot, expecting modest costs. Three months later, their finance team is staring at a bill that's jumped from $10,000 to $100,000. This plays out across businesses today, where 62% of organizations report cloud-related mistakes costing them over $25,000 monthly.
The rush to adopt AI is understandable. But beneath this excitement lies a growing challenge. Unlike traditional software licenses with predictable monthly fees, generative AI costs behave differently. Each conversation with a chatbot, every piece of content generated, and all the code snippets created add to the bill in ways that aren't always obvious.
The problem? Most organizations are still treating AI spending like traditional IT costs. A recent survey of over 300 IT professionals reveals a sobering truth: 78% estimate that between 21-50% of their cloud spending goes to waste. As organizations layer generative AI on top of their existing cloud infrastructure, these inefficiencies compound.
This is where FinOps enters the picture. By applying FinOps principles to generative AI, businesses can turn cost management from a source of stress into a strategic advantage.
Understanding GenAI Cost Drivers
GenAI costs have a tiny but mighty unit: the token. Think of tokens as the fuel for AI models. When you input "How's the weather today?" into ChatGPT, you're not just using four words – you're using around 7-8 tokens, each contributing to your bill. This tokenization system means costs can spiral quickly, especially when processing lengthy documents or handling multiple conversations.
Also, different AI models come with different price tags. While GPT-4 might offer superior results, it could cost up to 10 times more than its smaller counterparts. The trick is finding the sweet spot between capability and cost. 49% cited incorrect resource sizing as a major source of waste. This same principle applies even more critically to AI model selection, where choosing an oversized model for simple tasks is like using a sledgehammer to hang a picture.
Beyond the obvious costs of API calls and model usage, lie the hidden expenses:
- Data Preparation: Cleaning and formatting data for AI consumption often requires significant computing resources.
- Testing and Fine-tuning: Like a chef perfecting a recipe, getting AI outputs right requires multiple iterations. Each test run and fine-tuning session adds to the bill. In fact, 48% of organizations report costly AI experiments as a significant drain on resources.
- Storage Costs: Those AI-generated outputs need to be stored somewhere. With 50% of organizations citing excessive log/data retention as their top inefficiency, storage costs can quickly balloon without proper management.
Costs don't just increase linearly – they can explode exponentially. A customer service chatbot might handle 100 queries in testing, but what happens when it faces 10,000 real-world interactions daily?
Understanding these cost drivers is the first step toward managing them effectively. Just as 45% organizations struggle with limited visibility into their cloud spending, many find GenAI costs equally opaque. The key is transforming this understanding into actionable cost management strategies.
Core FinOps Practices for Gen AI Workloads
- Real-Time Monitoring and Forecasting
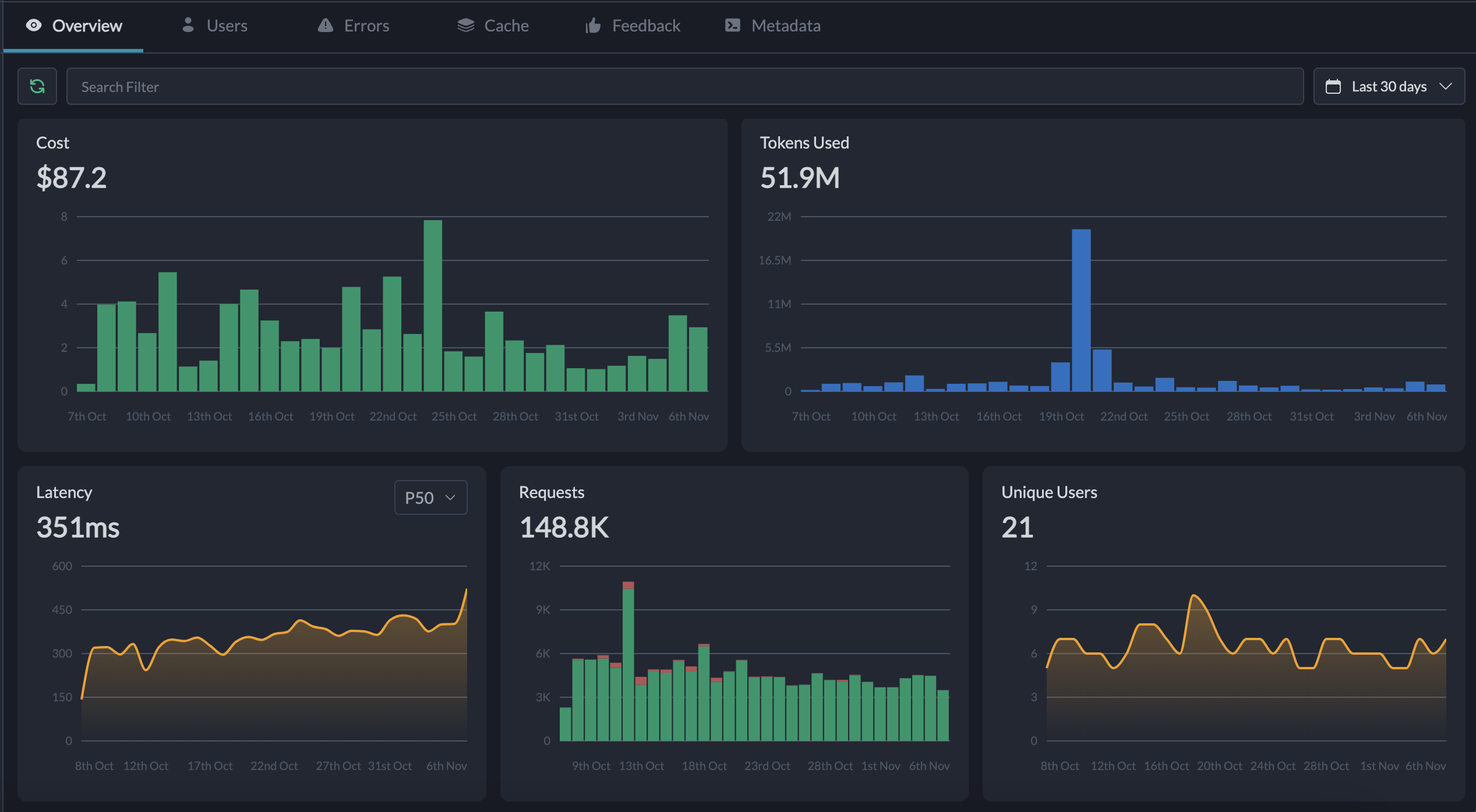
Visibility is essential for running AI operations efficiently. Knowing exactly how much GPU power or storage space is being used—and where—makes it easier to identify bottlenecks and forecast future expenses. With FinOps, teams can use real-time dashboards to track infrastructure usage across workloads, whether during training runs or live inference pipelines.
Tracking trends also helps teams adjust budgets based on usage forecasts, ensuring no surprises at the end of the month. Portkey's observability capability allows teams to track their spending for every specific virtual key by timeframe.
2. Cross-Functional Accountability and Collaboration
Running Gen AI isn’t just an engineering task; it involves multiple teams working together. Developers need resources to build and deploy models, operations teams ensure infrastructure is stable and scalable, and finance teams keep everything within budget.
Portkey supports real-time monitoring, so teams and finance leaders can track how budgets are allocated across different projects. This transparency helps organizations set strong limits, with alerts and permissions in place to manage budget overruns.
3. Optimizing Performance and Costs
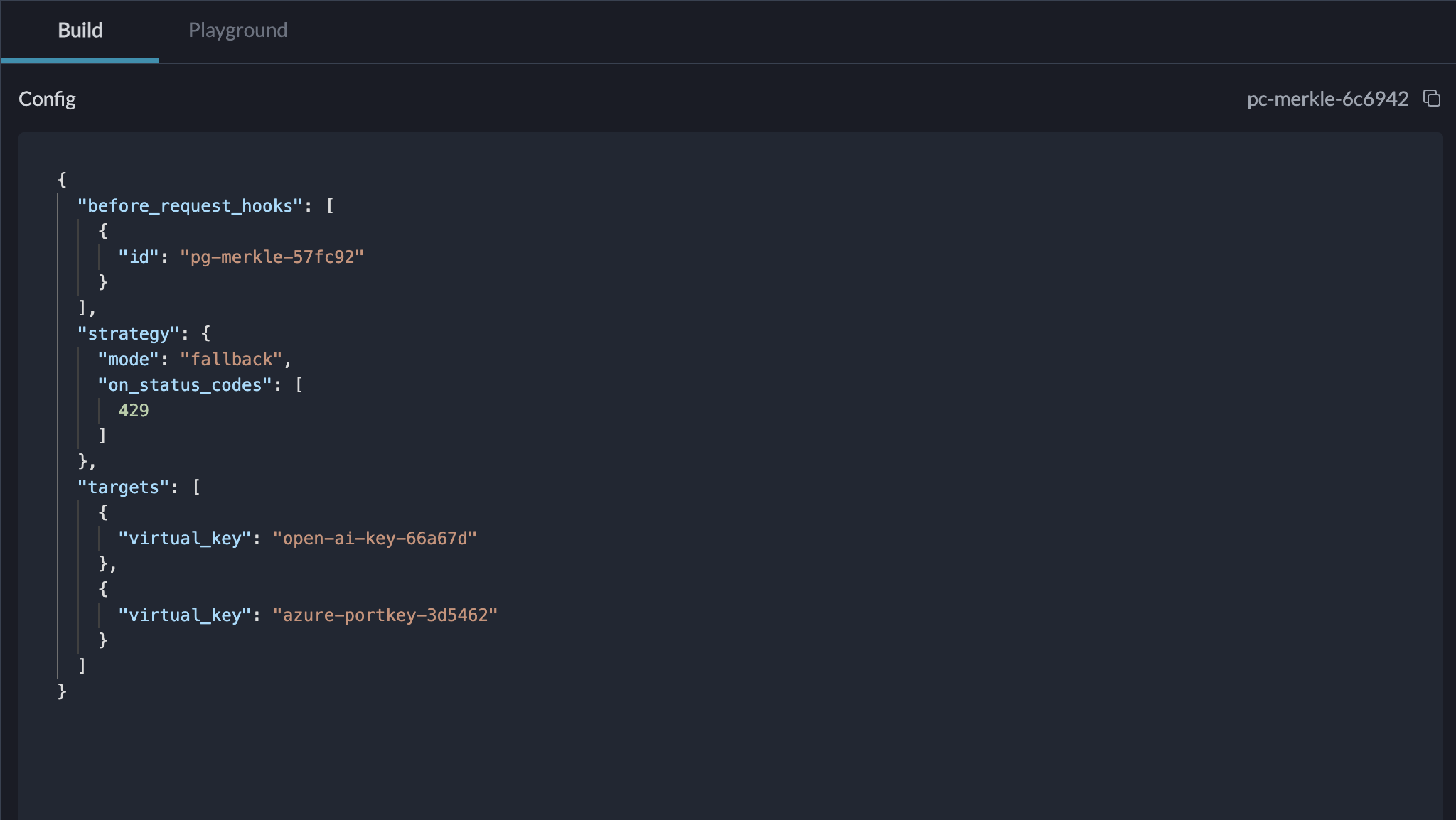
Large models like transformers and multimodal frameworks can quickly drain cloud budgets if not carefully managed. FinOps encourages teams to use spot instances for non-critical tasks, where lower-cost compute resources are available during off-peak times. Additionally, scheduling workloads to run during quieter hours helps avoid high infrastructure costs, and removing redundant datasets reduces storage expenses.
Portkey helps you optimize costs with its solutions for semantic cache, and easy routing to cheaper, faster open-source models without affecting any workload
4. Automating Budget Controls and Resource Scaling
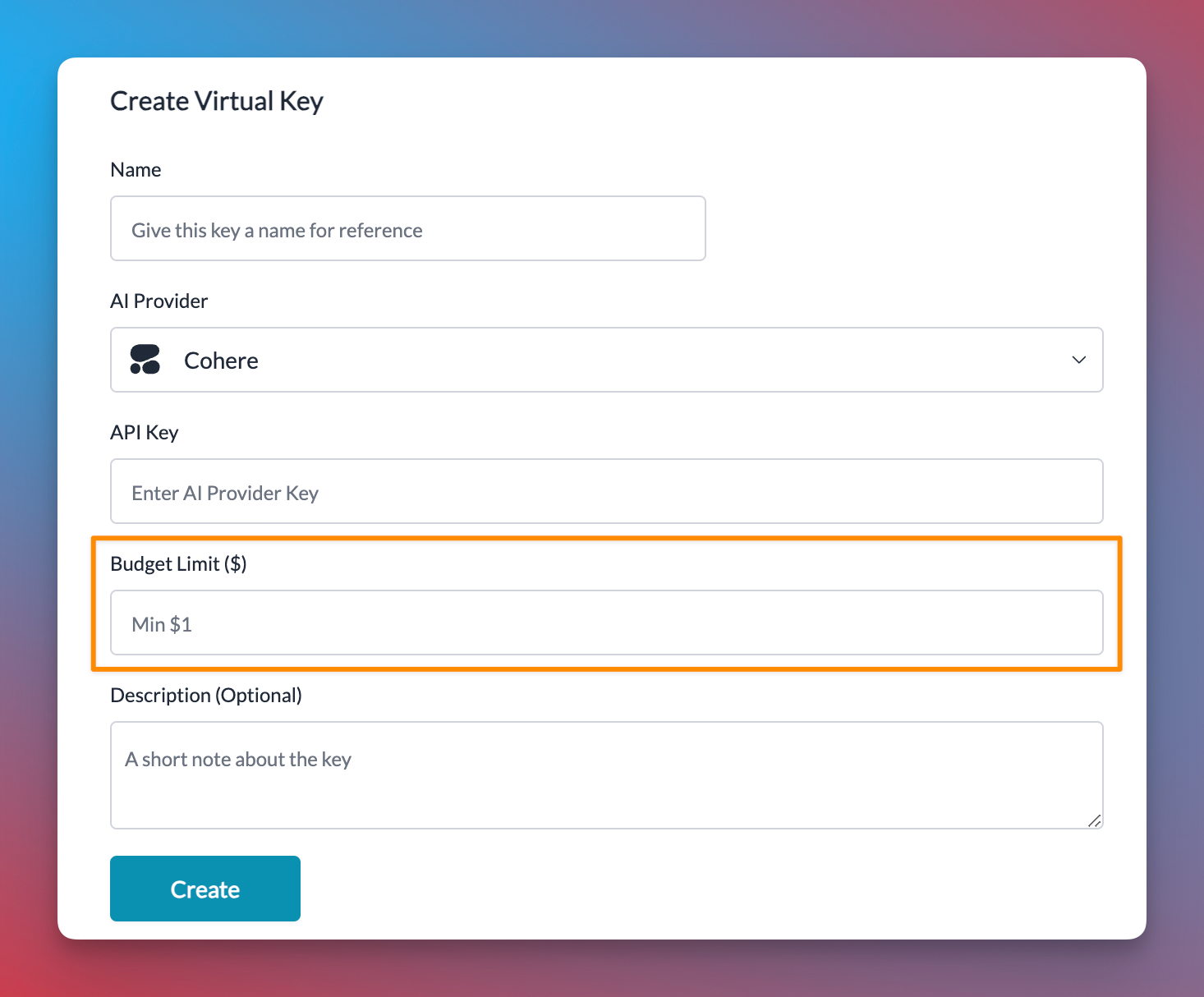
Managing AI workloads manually isn’t scalable. FinOps emphasizes the use of automated policies to keep infrastructure aligned with demand. Budget thresholds can be set to trigger alerts when usage exceeds predefined limits, giving teams time to make adjustments before costs get out of hand.
With Portkey, budget control becomes easier. The Gateway’s rate-limiting capabilities prevent unnecessary expenses from workloads. Teams can also automate the shutdown of unused resources, controlling costs without compromising performance. If any team exceeds its allocated funds, Portkey can implement automated restrictions, allowing finance teams to maintain control without restricting innovation.
As we've explored throughout this guide, the intersection of FinOps and GenAI isn't just about cutting costs – it's about building a sustainable foundation for AI innovation. And with the right approach, your organization can lead the way.
Struggling with growing AI costs across your organization? Let's talk about building a sustainable FinOps strategy for your GenAI initiatives. Schedule a 30-minute chat.
Sources:

