
Transforming E-Commerce Search with Semantic Cache: Insights from Walmart's Journey
We recently spoke with Rohit Chatter, Chief Software Architect at Walmart, who offered profound insights into how Walmart is leveraging these technologies, particularly focusing on semantic caching and its impact on e-commerce search functions.
The potential of Large Language Models (LLMs) and Generative AI in transforming business operations is no longer just theoretical.
Real-world applications are demonstrating significant improvements in efficiency, customer experience, and innovation.
I recently spoke with Rohit Chatter, Chief Software Architect at Walmart, who offered profound insights into how Walmart is leveraging these technologies, particularly focusing on semantic caching and its impact on e-commerce search functions.
If you'd rather listen to the conversation, here's the video.
Rohit Chatter's journey in the tech & AI world, spanning over 27 years, including his pivotal role at Walmart Labs, underscores a relentless pursuit of innovation.
Under his guidance, Walmart is not just adapting to the generative AI wave; it's riding the crest, especially in the realm of semantic search capabilities.
Prior to joining Walmart Labs, Rohit was the CTO of Inmobi marketing cloud where he led large engineering teams.
Semantic Caching at Walmart
Semantic caching at Walmart represents a significant leap from traditional caching mechanisms.
Traditional caching relies on exact match inputs to retrieve data, a method that falls short when dealing with the nuances of human language. Semantic caching, however, thrives on understanding and interpreting the meaning behind queries, enabling it to handle variations in phrasing with finesse.

Semantic Caching enabled massive gains for Walmart over traditional caching systems. Chatter shares, "Semantic caching has allowed us to handle tail queries with unexpected efficiency. What we anticipated might yield a 10-20% caching rate for tail queries pleasantly surprised us with a rate close to 50%."
"Semantic caching has allowed us to handle tail queries with unexpected efficiency. What we anticipated might yield a 10-20% caching rate for tail queries pleasantly surprised us with a rate closer to 50%"
Here's a more detailed post explaining semantic cache if you like:
 Vrushank Vyas
Vrushank Vyas
Generative AI in Search
Walmart's application of generative AI in search functions is particularly groundbreaking.
By understanding the intent behind customer queries, the system can present highly relevant product groupings. This approach not only enhances the shopping experience but also significantly improves the efficiency of search operations.
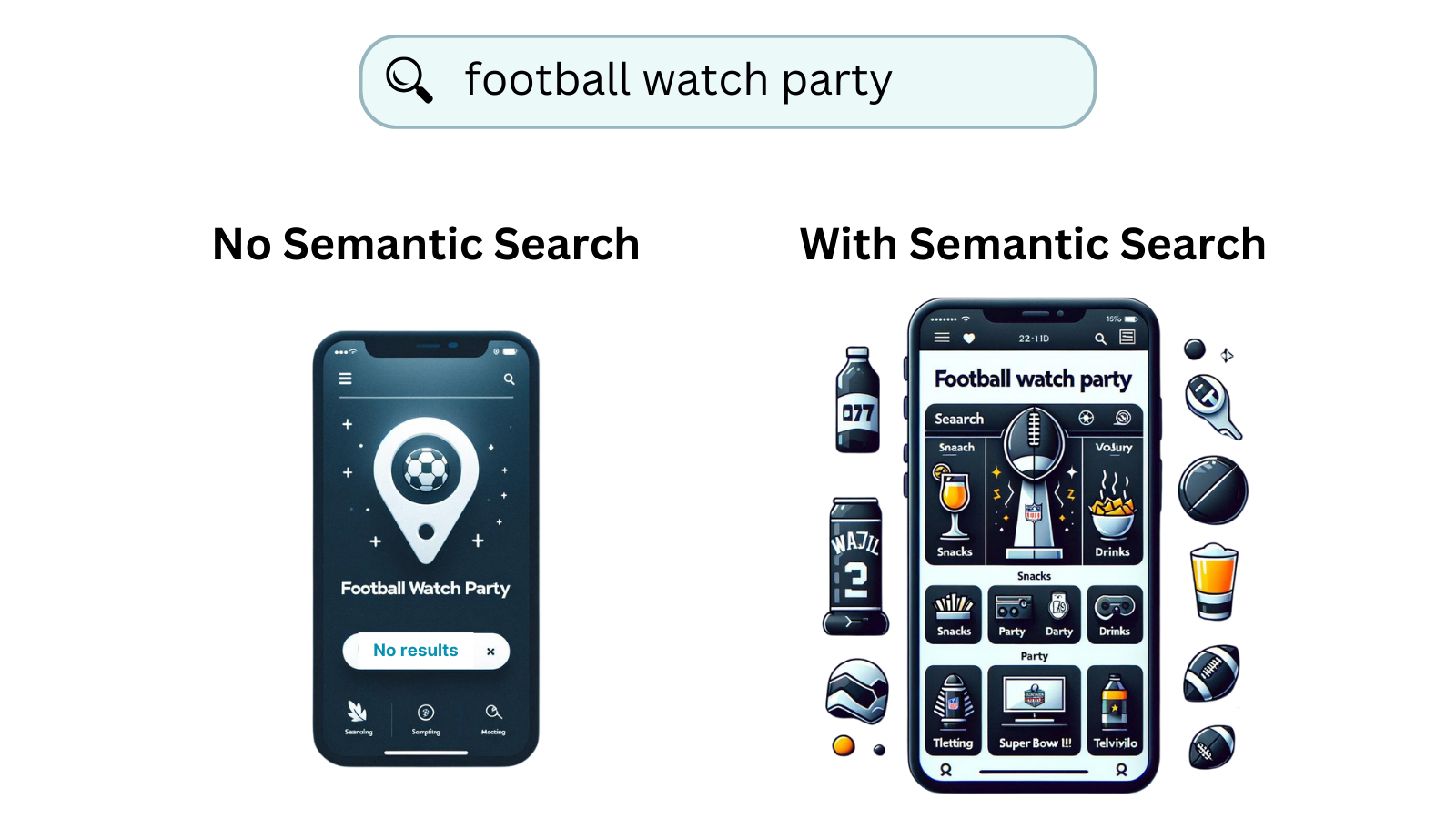
- Real-World Example: "A query like 'football watch party' returns not just snacks and chips but also party drinks, Super Bowl apparel, and televisions, demonstrating our system's ability to grasp and respond to the nuanced needs of our customers," Chatter elaborates.
Challenges and Solutions
Integrating generative AI into Walmart's search function was not without its challenges.
"Balancing cost and performance is crucial. We are progressing towards achieving sub-second response times, ensuring that our customers receive timely and relevant results," Chatter notes.
Latency and cost are two significant hurdles.
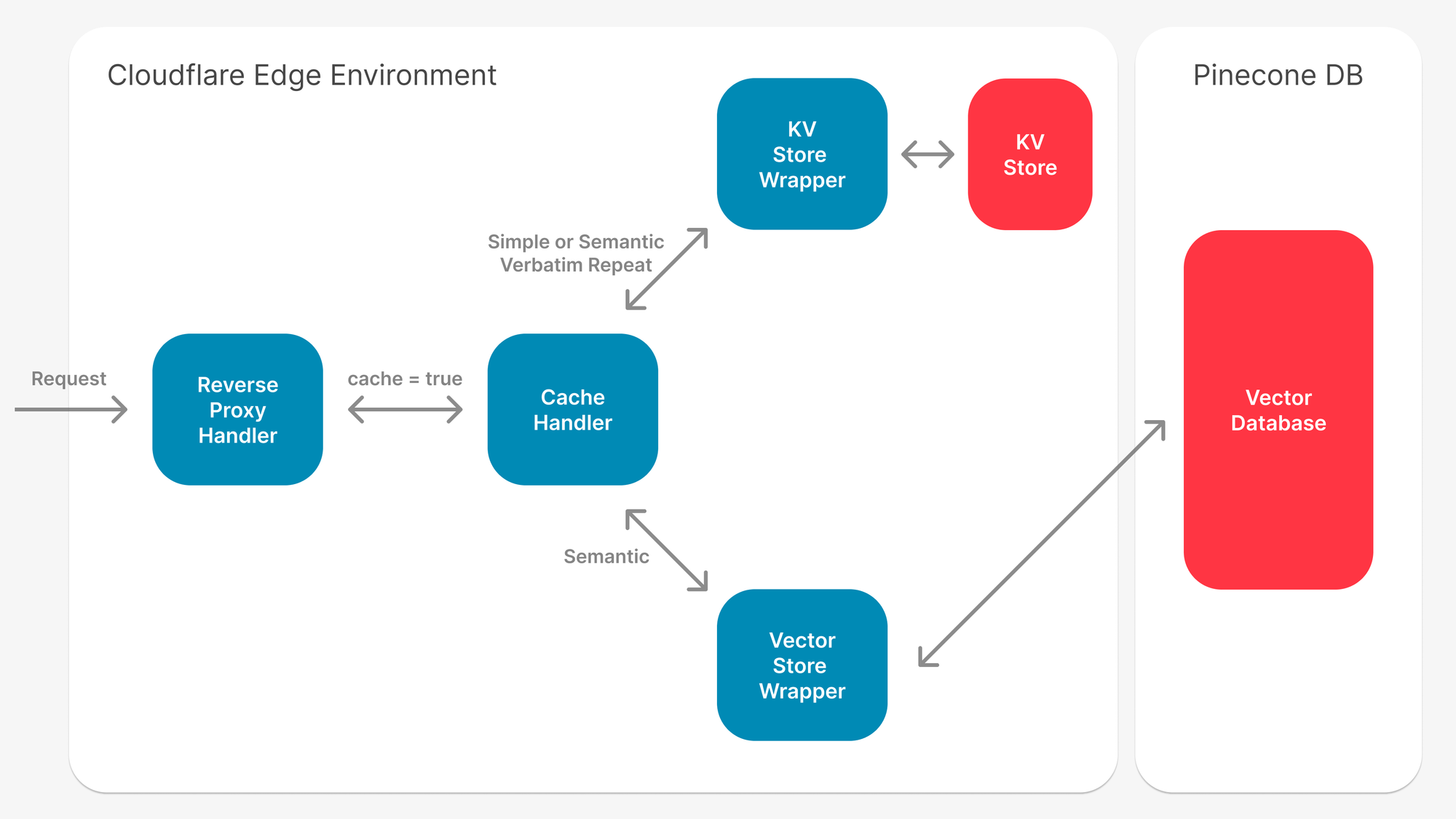
Latency Challenges: Semantic caching has a lot more to compute compared to a traditional cache making the overall process slow.
Cost Challenges: While a simple cache can be extremely cheap to set up and scale, semantic caching needs every product SKU and query to be converted to vectors and then searched upon which can be expensive on both the storage and compute.
There's a significant trade-off between more results v/s a drop in performance, so it's usually advisable to use both systems together.
Through strategic planning and innovative engineering, Walmart is making strides toward making this technology scalable and efficient.
The Road Ahead
The conversation with Chatter was not just a reflection on current achievements but also a window into the future. Walmart's commitment to exploring and integrating generative AI across its operations suggests a future where technology and retail intertwine more seamlessly than ever.
Vision for the Future: Chatter's vision extends beyond immediate technological achievements, hinting at a future where AR, VR, and generative AI converge to offer unparalleled shopping experiences.
Walmart's journey with semantic caching and generative AI is a testament to the transformative power of these technologies. As we continue to explore the boundaries of what's possible, conversations like the one with Rohit Chatter provide invaluable insights and inspiration. The future of e-commerce, powered by AI, promises to be as exciting as it is innovative.
In this journey of technological evolution, Walmart is not just changing how we search for products online; it's redefining the experience of shopping itself.
If you'd like to stay updated about more such deep dives we do with industry experts in the future, consider joining the LLMs in the Production Discord Channel.


Our gateway that supports caching is open source here with over 3.5k stars
 Portkey-AI
Portkey-AI
