Gemini 3.0 vs GPT-5.1: a clear comparison for builders
A concise comparison of Gemini 3.0 and GPT-5.1 across reasoning, coding, multimodal tasks, agent performance, speed, and cost. Learn which model performs better overall and how teams can run both through a single production-ready gateway.

Frontier models continue to shape how teams build AI apps, agents, and multimodal systems. As workloads move from simple chat interfaces to complex reasoning, real-time interaction, and full agent workflows, choosing the right model becomes a product and infrastructure decision, not just a benchmark comparison.
Gemini 3.0 and GPT 5.1 represent the newest generation of general-purpose models available across major ecosystems. Both push forward on reasoning, coding assistance, multimodal understanding, and responsiveness, but they approach these capabilities differently. This comparison outlines where each model works best, how they differ in architecture and behavior, and what teams should consider when making model choices across production workloads.
Check this out!
Benchmarks & performance comparison
Coding performance
Gemini 3.0:
Gemini 3.0 performs well across real-world software tasks. Its scores on SWE-bench, LiveCodeBench Pro, and t2-bench show that it handles multi-file reasoning, debugging, and long-step coding workflows with ease. It also does well on long-horizon agent tasks like Vending-Bench, indicating strong consistency across extended chains of actions.

GPT-5.1:
GPT-5.1 matches Gemini on core coding benchmarks and stays stable across repeated attempts. It performs well in tool-driven coding workflows, especially tasks like Terminal-Bench where structured planning and command execution matter. Its behavior tends to be more predictable, which helps when plugging the model into IDE agents or CI workflows.
Reasoning and academic performance
Gemini 3.0:
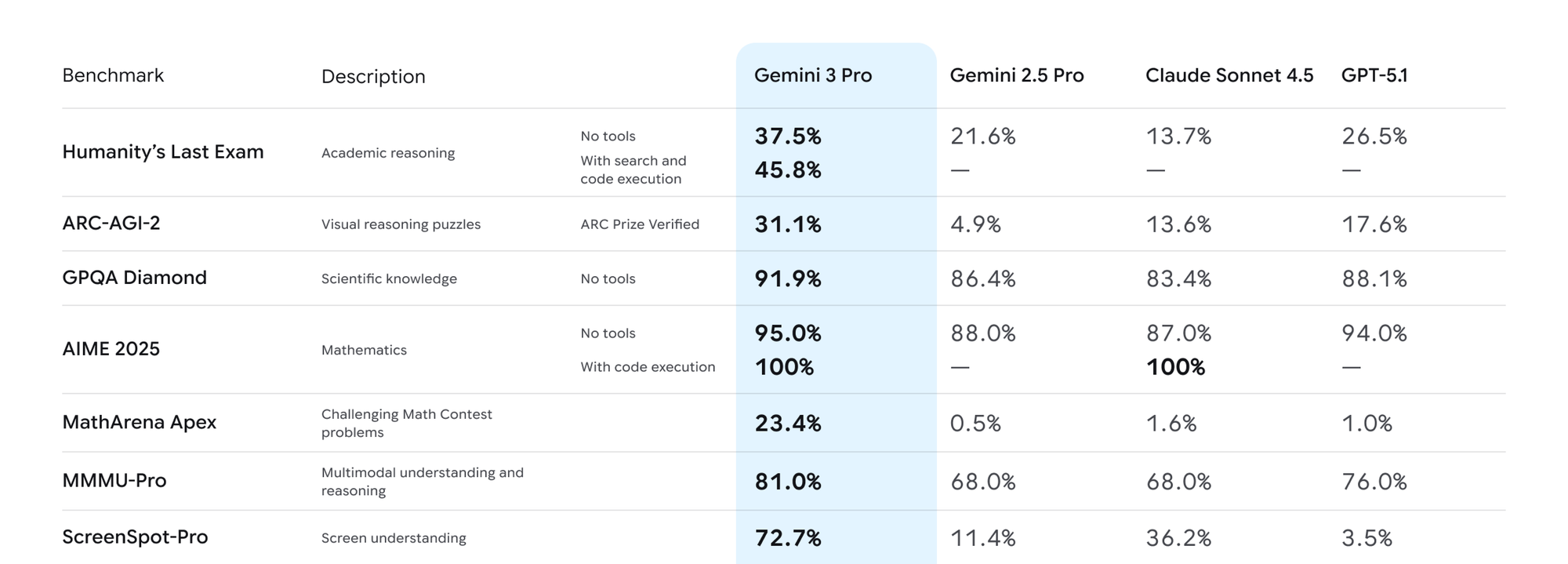
Gemini 3.0 delivers strong results across academic and competition-style reasoning benchmarks. It leads on GPQA Diamond, ARC-AGI-2, MMMU-Pro, and AIME 2025, pointing to deeper scientific knowledge, better visual–logical reasoning, and stronger performance on problems that require multi-step deduction without tools.
GPT-5.1:
GPT-5.1 stays close on most academic benchmarks and occasionally matches Gemini, especially on AIME 2025 and GPQA. Its reasoning is more uniform across categories, which leads to fewer fluctuations across different problem types. While Gemini often peaks higher, GPT-5.1 maintains steadier accuracy across a wider range of structured reasoning tasks.
Multimodal and vision-language performance
Gemini 3.0:
Gemini 3.0 is strong across multimodal reasoning, leading on MMMU-Pro, Video-MMMU, and ScreenSpot-Pro. These benchmarks measure how well a model interprets images, charts, video frames, and mixed visual-text inputs. Gemini’s higher scores suggest stronger cross-modal grounding and better consistency when tasks require linking visual details to structured reasoning.

GPT-5.1:
GPT-5.1 performs well on multimodal tasks too, staying competitive on most image-based and text-vision problems. Although Gemini posts higher results on visual reasoning benchmarks, GPT-5.1 tends to handle everyday multimodal tasks with steady accuracy and fewer erratic outputs.
Agentic and tool-use performance
Gemini 3.0:
Gemini 3.0 performs well on long-horizon agent tasks, showing strong planning ability and good follow-through across multi-step workflows. Benchmarks like Vending-Bench and complex coding agents reflect its ability to maintain goals, adapt mid-task, and combine reasoning with tool calls effectively.
GPT-5.1:
GPT-5.1 shows strong and steady tool-use behavior, especially in structured environments. It executes commands, interprets tool outputs, and updates plans with fewer inconsistencies. While Gemini may complete longer chains more effectively, GPT-5.1 generally produces more predictable agent behavior run after run.
Pricing and efficiency
Gemini 3.0:
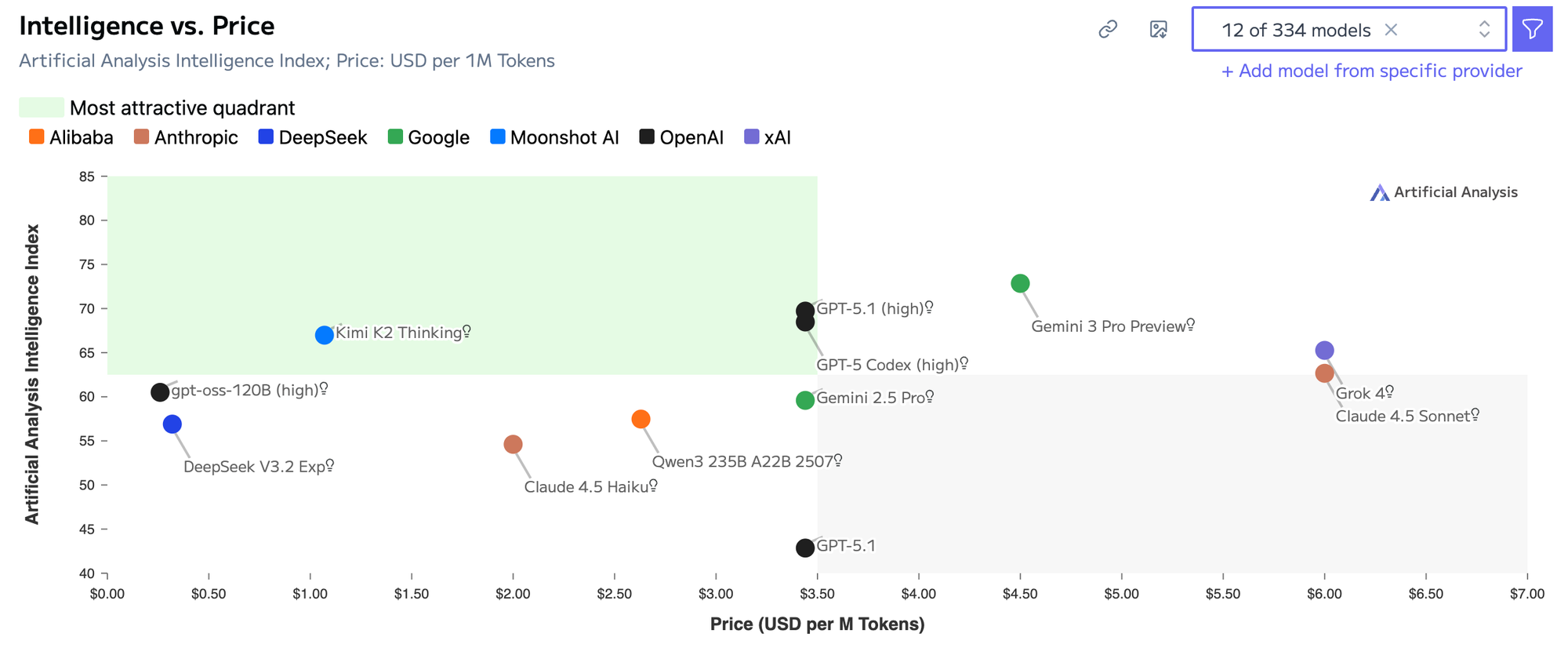
Gemini 3.0 sits in the higher-priced tier among frontier models. While its intelligence scores place it near the top, the model falls outside the “most attractive” price–performance zone on the chart. This means teams get strong capability, but at a higher per-token cost compared to alternative frontier models.
GPT-5.1:
GPT-5.1 lands in a more balanced price–performance position. It is still expensive relative to mid-tier models, but it sits inside the chart’s attractive efficiency quadrant. The model offers high reasoning and coding performance without drifting into the premium pricing range that Gemini 3.0 occupies.
Speed and latency
Gemini 3.0:
Gemini 3.0 delivers solid output speed, reaching 130 tokens per second. This places it among the faster frontier models, making it suitable for interactive apps, UI assistants, and high-volume chat workloads where responsiveness matters.
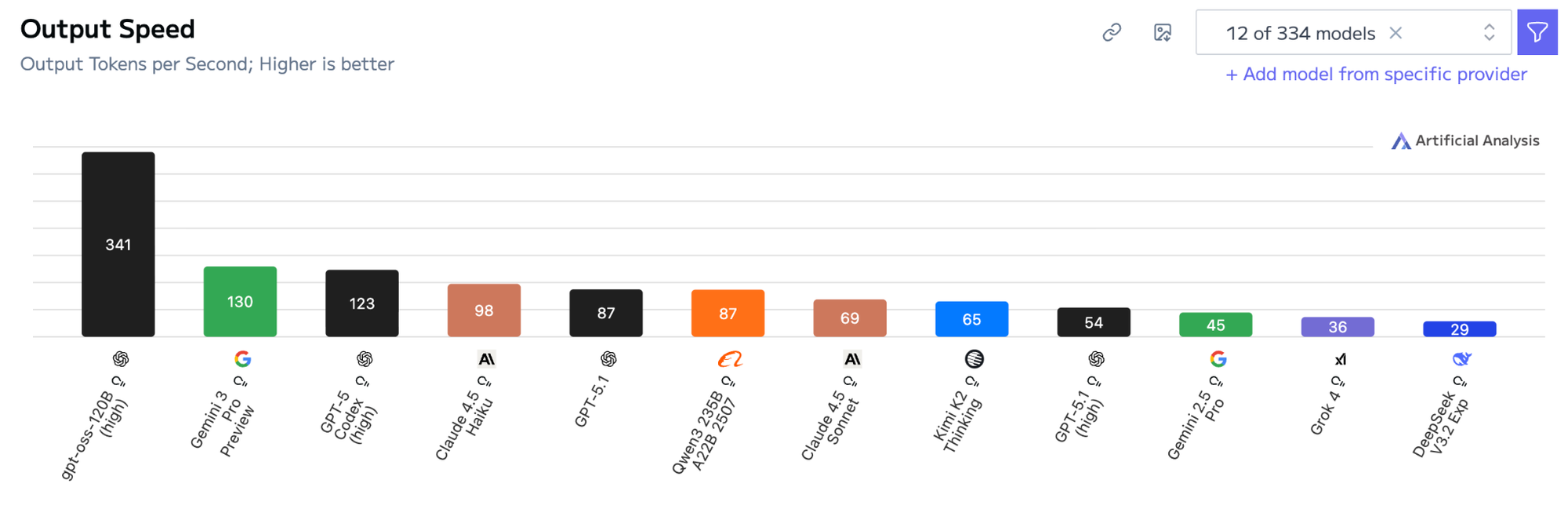
GPT-5.1:
GPT-5.1 sits lower on the speed chart at 87 tokens per second. While not slow, it’s noticeably behind Gemini 3.0 and the fastest OpenAI variants. Its advantage lies more in reasoning stability than raw throughput.
Which model should you choose?
Across most benchmark categories, Gemini 3.0 comes out ahead. It leads in academic reasoning, multimodal understanding, long-horizon tasks, and generation speed. For teams prioritizing depth of reasoning, stronger visual comprehension, and fast, responsive outputs, Gemini 3.0 is the more capable model overall.
GPT-5.1 remains competitive, especially in coding stability, tool-use consistency, and cost efficiency. Its performance is steady across categories, making it a dependable option for production workloads where predictability, lower variance, and budget alignment matter.
Run both models through one production-ready gateway
Teams increasingly need to evaluate and use multiple frontier models side by side. Portkey's AI gateway makes this simpler by giving you unified access to Gemini 3.0, GPT-5.1, and hundreds of other models through a single API. You can route traffic, compare outputs, and switch models without changing your application code.
Portkey also adds the controls needed for production use:
- Role-based access, budgets, and quotas
- Guardrails for safe and compliant usage
- Full observability for logs, latency, and spend
- Consistent behavior across providers, models, and tools
Whether you're optimizing for performance, cost, or reliability, Portkey helps you run both models with clear visibility and governance in place.
If your team is evaluating or planning a multi-model strategy, you can get started with Portkey in minutes. Book a demo or start integrating to try both models through one unified gateway.