
GPT-5.4 vs Claude Opus 4.6: a guide to choosing the right model
GPT-5.4 vs Claude Opus 4.6: head-to-head across 12 benchmarks: coding, tool use, reasoning, and more. See which model wins where, and when to use each.

This guide compares the models head-to-head across the benchmarks that matter most for developers: coding, tool use, reasoning, and real-world task completion.
TL;DR: Quick decision framework
Choose Claude Opus 4.6 if you prioritize multi-file refactoring, long-context coherence, novel reasoning (ARC-AGI-2), and agentic search. Best for complex software engineering tasks requiring deep architectural understanding.
Choose GPT-5.4 if you need native computer use, faster tool execution, lower costs, or efficient token usage. Best for rapid prototyping, desktop automation, and cost-sensitive production deployments.
GPT-5.4 vs Claude Opus 4.6: Model specifications
GPT-5.4 vs Claude Opus 4.6: Coding benchmarks
Both companies report strong coding performance, but on different benchmark variants.
Here's how they compare:
BrowseComp: agentic web search
BrowseComp measures a model's ability to persistently search across multiple rounds to find relevant information, particularly for "needle-in-a-haystack" questions that require synthesizing data from many sources.
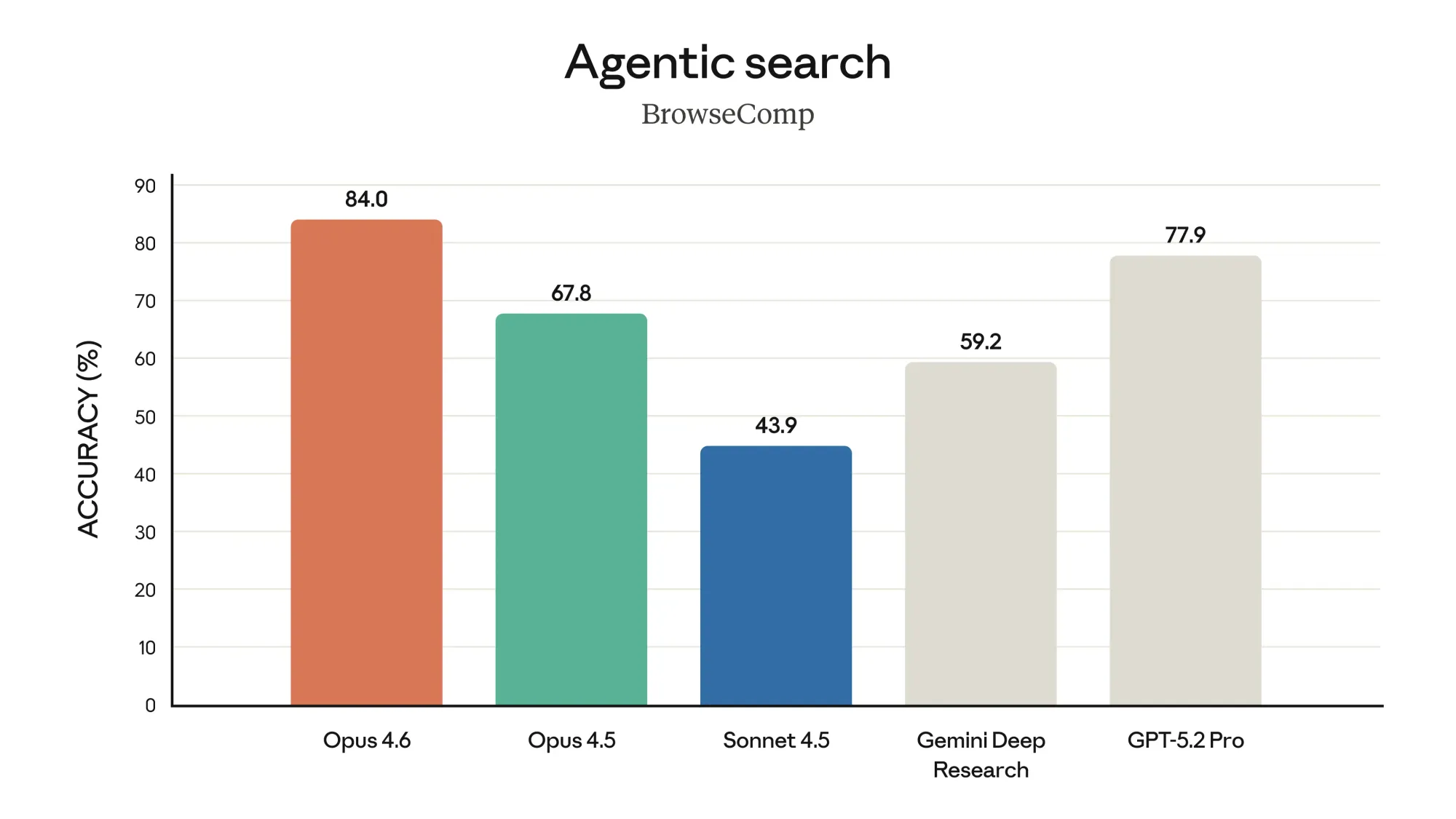
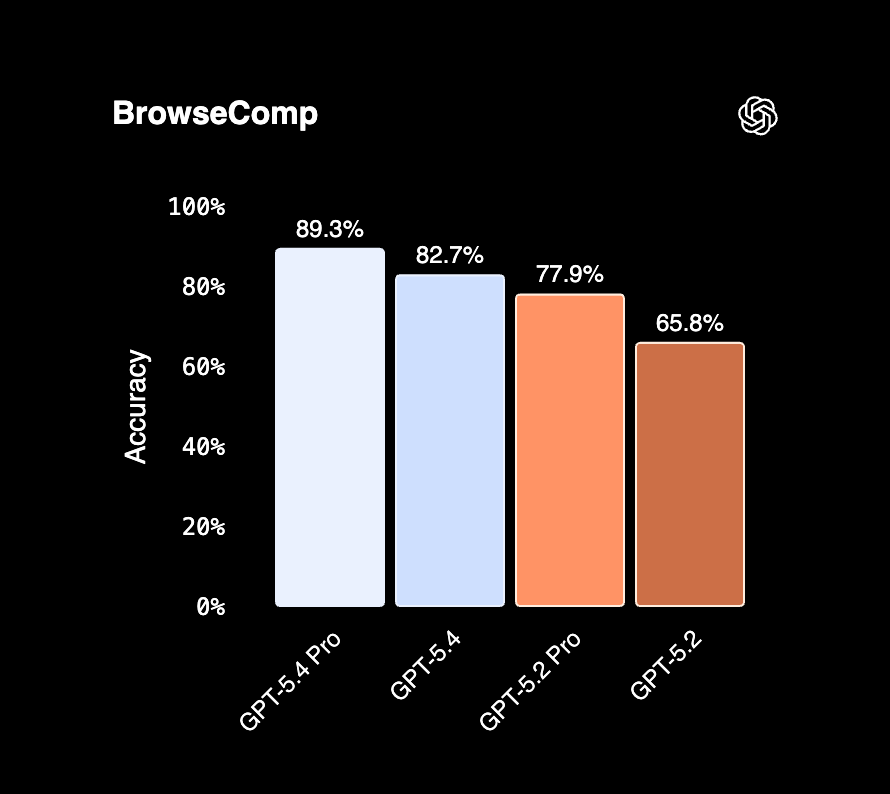
This is one of the few benchmarks where we can make a direct comparison: GPT-5.2 Pro scores 77.9% on both Anthropic's and OpenAI's evaluations, confirming they're using the same methodology.
| Model | BrowseComp | Source |
|---|---|---|
| Claude Opus 4.6 | 84.0% | Anthropic |
| GPT-5.4 | 82.7% | OpenAI |
| GPT-5.4 Pro | 89.3% | OpenAI |
The takeaway: At standard tiers, Claude Opus 4.6 edges out GPT-5.4 by 1.3 points (84.0% vs 82.7%). But if you're willing to pay for GPT-5.4 Pro, it pulls ahead significantly at 89.3%.
For developers building agents that need to search the web and synthesize information from multiple sources, both models are strong choices. The decision comes down to whether the Pro tier pricing makes sense for your use case.
Terminal-Bench 2.0: agentic terminal coding
Terminal-Bench 2.0 tests a model's ability to navigate and complete tasks in a terminal environment, file editing, git operations, build systems, and debugging workflows that developers do daily.
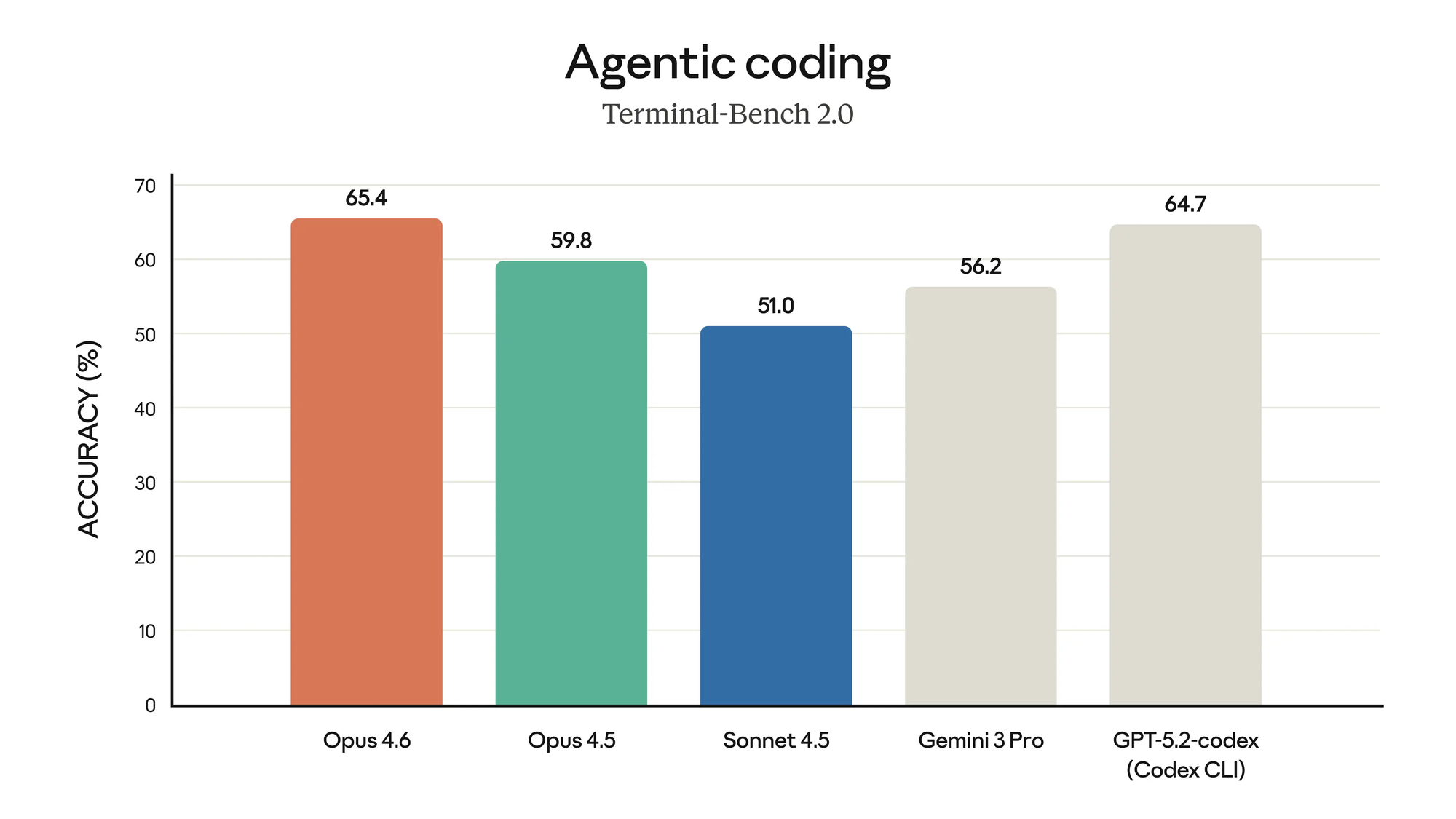
| Model | Terminal-Bench 2.0 |
|---|---|
| GPT-5.4 | 75.1% |
| Claude Opus 4.6 | 65.4% |
The takeaway: GPT-5.4 has a clear advantage here, outperforming Claude Opus 4.6 by nearly 10 points. If your workflow is heavily terminal-based — running tests, executing scripts, iterating in a shell — GPT-5.4 is the stronger choice.
SWE-Bench: agentic coding
SWE-Bench tests a model's ability to resolve real GitHub issues, the kind of bug fixes and feature implementations that developers handle daily.
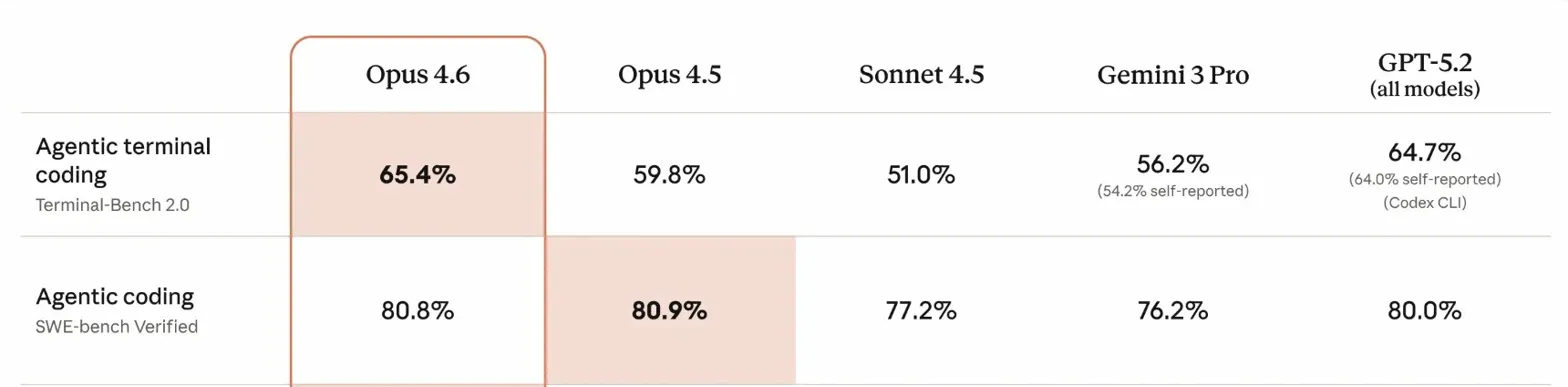
Here's the catch: Anthropic and OpenAI reported on different variants.
| Benchmark | Claude Opus 4.6 | GPT-5.4 |
|---|---|---|
| SWE-Bench Verified | 80.8% | Not reported |
| SWE-Bench Pro (Public) | Not reported | 57.7% |
SWE-Bench Verified is the standard variant. SWE-Bench Pro is intentionally harder, designed to resist data contamination and benchmark gaming. Comparing 80.8% to 57.7% would be apples to oranges.
The takeaway: Both models are clearly strong at coding. Claude leads on the standard benchmark, GPT-5.4 chose to report on the harder one. Without head-to-head results on the same variant, we can't pick a winner, but either model will handle real-world GitHub issues competently.
GDPval: professional knowledge work
GDPval evaluates AI performance on economically valuable tasks across professional domains, finance, legal, project management, and similar knowledge work.
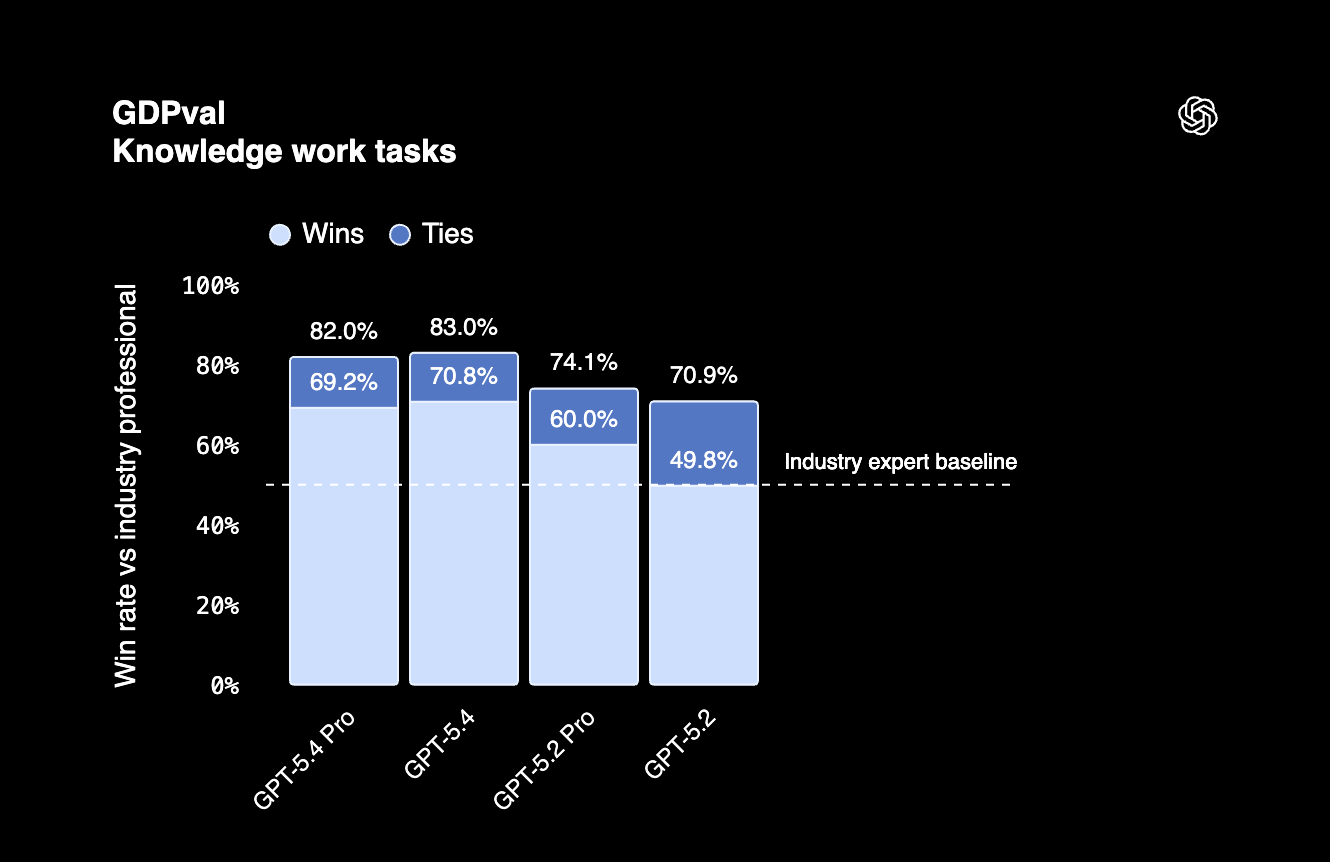
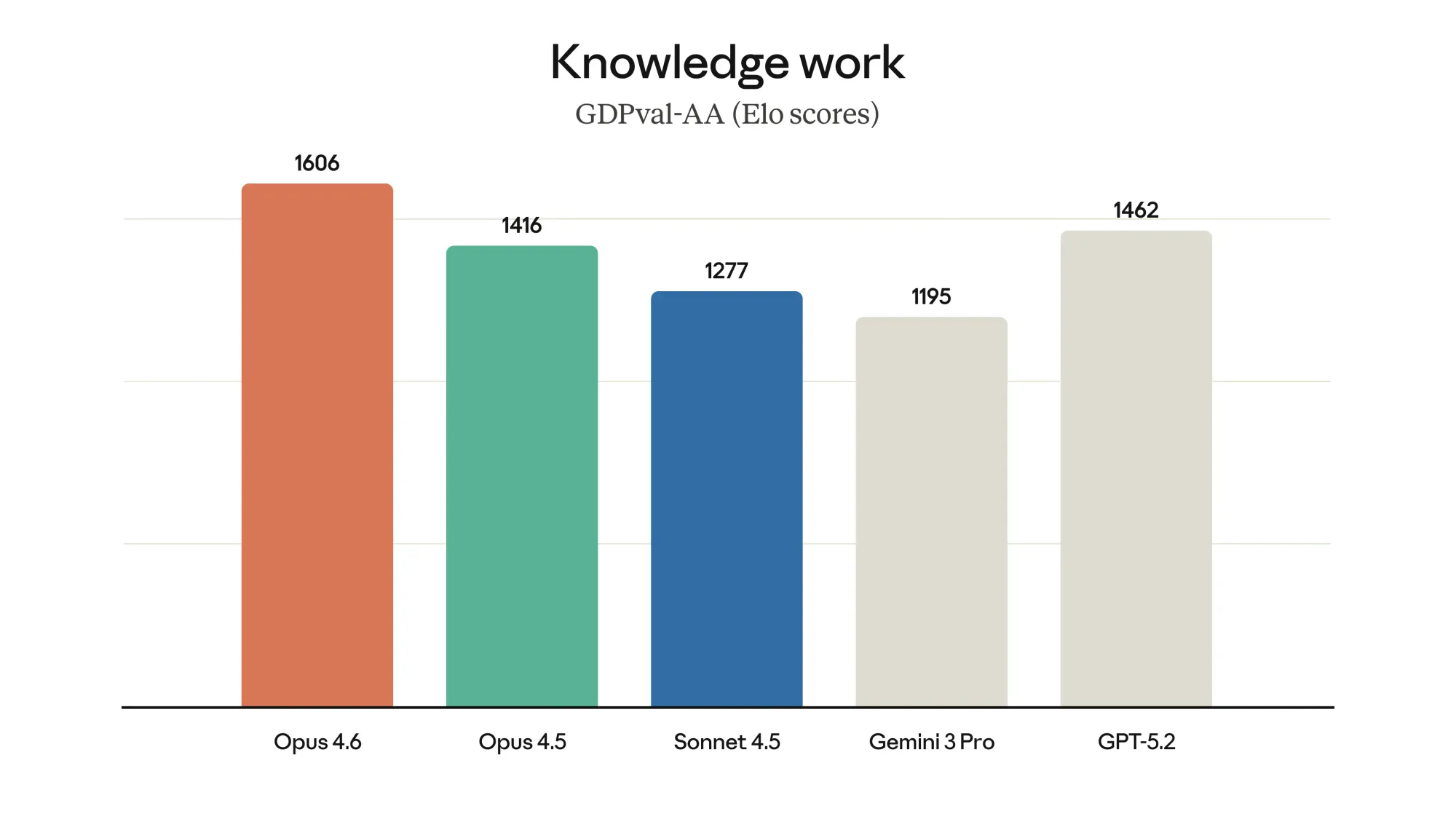
The two companies report this benchmark differently:
| Model | Metric | Score |
|---|---|---|
| Claude Opus 4.6 | Elo rating | 1606 |
| GPT-5.4 | Wins or ties vs humans | 83.0% |
Anthropic uses Elo scores (like chess ratings) where Claude Opus 4.6 leads GPT-5.2 by 144 points. OpenAI reports that GPT-5.4 matches or exceeds human professionals 83% of the time.
The takeaway: Both models excel at professional knowledge work, but the different reporting methods make direct comparison impossible. What's clear: Claude Opus 4.6 is the top performer in Anthropic's Elo ranking, and GPT-5.4 beats human professionals in the majority of tasks.
MMMU Pro: visual reasoning
MMMU Pro tests multimodal reasoning, understanding and analyzing images, charts, and diagrams. GPT-5.2 scores 79.5% on both Anthropic's and OpenAI's evaluations, confirming the same methodology.
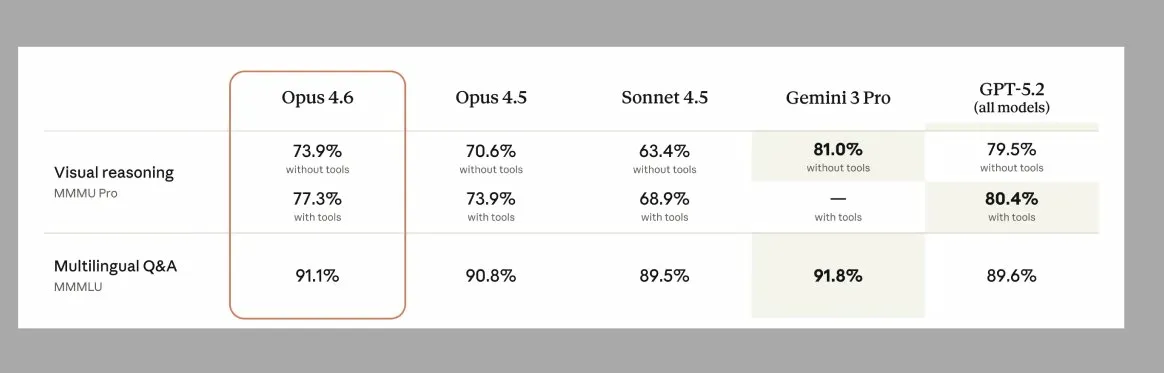
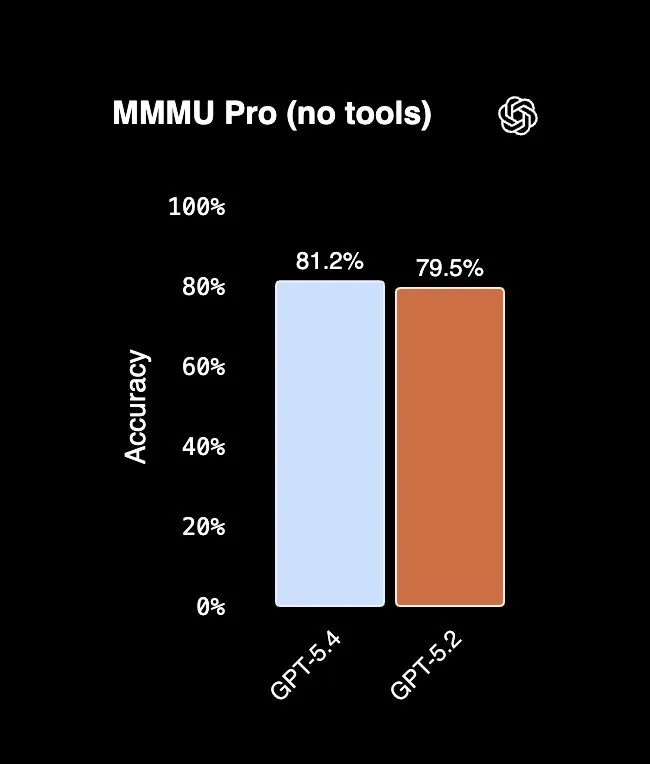
| Model | Without tools | With tools |
|---|---|---|
| GPT-5.4 | 81.2% | Not reported |
| Claude Opus 4.6 | 73.9% | 77.3% |
The takeaway: GPT-5.4 leads. Claude Opus 4.6 improves to 77.3% with tools enabled, but still trails GPT-5.4's baseline. If your workflow involves interpreting visual content, charts, diagrams, screenshots, scanned documents, GPT-5.4 has a clear advantage.
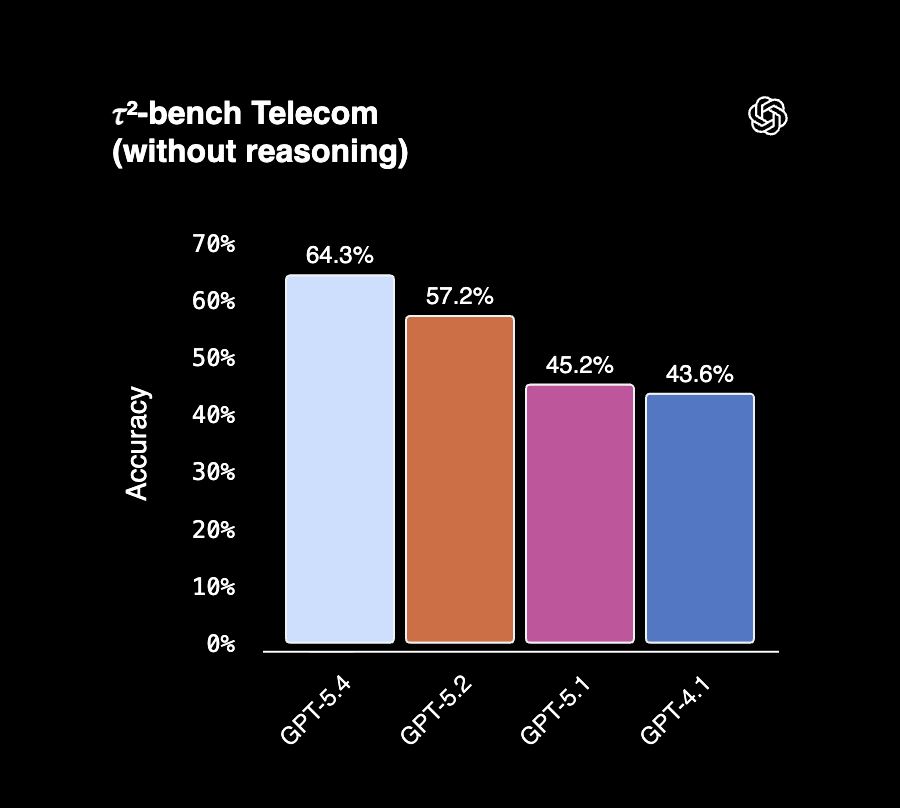
Tool use: τ²-bench and MCP Atlas
τ²-bench tests how reliably models can call tools to complete tasks in specific domains like telecom and retail. MCP Atlas measures scaled tool orchestration — coordinating across many tools and servers in complex workflows.
Both benchmarks are directly comparable: GPT-5.2 scores match across Anthropic's and OpenAI's evaluations.

| Benchmark | Claude Opus 4.6 | GPT-5.4 |
|---|---|---|
| τ²-bench Telecom | 99.3% | 98.9% |
| MCP Atlas | 59.5% | 67.2% |
The takeaway: For domain-specific tool calling, both models are near-perfect, pick either. For complex multi-tool orchestration, GPT-5.4 has the edge.
OSWorld: computer use
OSWorld tests a model's ability to interact with desktop applications — navigating UIs, clicking through workflows, and completing real tasks using screenshots, mouse, and keyboard.
| Model | OSWorld |
|---|---|
| GPT-5.4 | 75.0% |
| Claude Opus 4.6 | 72.7% |
Note: Anthropic reports on OSWorld, OpenAI reports on OSWorld-Verified (a slightly different variant), so this comparison may not be exact.

The takeaway: Both models exceed the human expert baseline of 72.4%. GPT-5.4 edges ahead, and it's OpenAI's first general-purpose model with native computer use built in, no plugins or wrappers needed. If desktop automation is core to your workflow, GPT-5.4 is the safer bet.
Humanity's Last Exam: multidisciplinary reasoning
Humanity's Last Exam is a benchmark created by crowdsourcing extremely difficult questions from subject matter experts across dozens of academic fields — math, physics, law, medicine, philosophy, and more. It's designed to be a ceiling test: problems hard enough that current AI systems struggle to solve them.
| Model | Without tools | With tools |
|---|---|---|
| Claude Opus 4.6 | 40.0% | 53.1% |
| GPT-5.4 | 39.8% | 52.1% |
The takeaway: These models are nearly identical on hard reasoning tasks. Claude Opus 4.6 has a razor-thin lead in both conditions, but the difference is negligible. For complex multidisciplinary problems, either model will perform similarly.
ARC-AGI-2: novel problem-solving
ARC-AGI-2 tests fluid intelligence — the ability to solve novel visual puzzles from just a few examples. It's designed to resist memorization and measure genuine reasoning on problems the model has never seen before.
| Model | ARC-AGI-2 |
|---|---|
| GPT-5.4 | 73.3% |
| Claude Opus 4.6 | 68.8% |
The takeaway: GPT-5.4 leads on novel reasoning tasks. If your use case involves solving unfamiliar problems that don't fit established patterns, GPT-5.4 has an edge.
GPQA Diamond: graduate-level reasoning
GPQA Diamond tests expert-level scientific reasoning — the kind of questions that would challenge PhD students in physics, chemistry, and biology.
| Model | GPQA Diamond |
|---|---|
| GPT-5.4 | 92.8% |
| Claude Opus 4.6 | 91.3% |
The takeaway: Both models are exceptional at graduate-level reasoning, scoring above 91%. GPT-5.4 edges ahead slightly, but the gap is small enough that either model handles expert-level scientific questions with ease.
GPT-5.4 vs Claude Opus 4.6: Pricing comparison
GPT-5.4 is 40-50% cheaper at base rates.
For a typical coding session (10K input, 5K output), you're looking at ~$0.10 with GPT-5.4 vs ~$0.175 with Claude.
However, GPT-5.4's pricing doubles for contexts over 272K tokens, which can eliminate the cost advantage for long-context workloads.
GPT 5.4 vs Claude Opus 4.6: How to choose?
When to choose what
| You're trying to... | Choose | Why |
|---|---|---|
| Build agents that search the web and synthesize information | Claude Opus 4.6 | Leads on BrowseComp (84% vs 82.7%). Search tasks are token-heavy with multiple rounds — Claude's accuracy edge means fewer failed searches and retries, potentially offsetting the higher token cost. |
| Automate desktop tasks (filling forms, navigating UIs) | GPT-5.4 | Leads on OSWorld (75% vs 72.7%) with native computer use. Desktop automation involves many small interactions — cheaper tokens add up, and GPT-5.4's native support means less setup overhead. |
| Run coding agents in terminal environments | GPT-5.4 | Leads on Terminal-Bench 2.0 (75.1% vs 65.4%). Coding agents are token-hungry — iterations, test runs, error logs. Higher accuracy + 50% cheaper tokens is a clear win for terminal workflows. |
| Fix bugs in real codebases | Depends | Claude scores 80.8% on SWE-Bench Verified; GPT-5.4 scores 57.7% on harder SWE-Bench Pro — different benchmarks, can't compare directly. If Claude's accuracy means fewer retries, it may offset cost. For high-volume CI/CD where cost dominates, lean GPT-5.4. |
| Build agents that coordinate 20+ tools or MCP servers | GPT-5.4 | Leads on MCP Atlas (67.2% vs 59.5%). Tool Search feature cuts token usage by ~47% — for multi-tool agents making many calls, this compounds into major savings. |
| Process charts, diagrams, or screenshots | GPT-5.4 | Leads on MMMU Pro (81.2% vs 73.9%). Vision tasks are typically lower token volume, so cost difference is modest — but GPT-5.4's accuracy edge makes it the better choice regardless. |
| Solve novel, unfamiliar problems | GPT-5.4 | Leads on ARC-AGI-2 (73.3% vs 68.8%). Reasoning tasks can require multiple attempts; better accuracy + cheaper tokens both favor GPT-5.4. |
| Build agents that call domain-specific APIs | Either | Both near-perfect on τ²-bench (99.3% vs 98.9%). At this accuracy level, cost becomes the deciding factor — GPT-5.4 if volume is high, Claude if you're already in that ecosystem. |
| Tackle hard research or academic questions | Either | Essentially tied on Humanity's Last Exam and GPQA Diamond. Both models handle expert-level reasoning equally well — choose based on cost or existing workflow. |
| Analyze entire codebases or large document sets | Claude Opus 4.6 | GPT-5.4 pricing doubles past 272K tokens. For long-context work, Claude's flat pricing wins — and a single pass is cheaper than chunking and reassembling with GPT-5.4. |
GPT-5.4 wins on execution-heavy, high-iteration tasks where its accuracy lead and cheaper tokens compound. Claude Opus 4.6 is the better choice for agentic search and long-context work where its strengths offset the pricing. For pure reasoning, they're tied, go with whatever fits your stack.
The bottom line
GPT-5.4 and Claude Opus 4.6 are both frontier models, but they're not interchangeable.
The real answer: use both.
The best strategy for many teams is to route tasks to the model that handles them best. Use GPT-5.4 for terminal-heavy coding and automation. Use Claude Opus 4.6 for deep search and long-context analysis. Fall back to the cheaper model when accuracy is comparable.
This is where Portkey comes in. Portkey's unified AI gateway gives you a single API to access both Claude and OpenAI models, even when you're using Claude Code, Codex, or calling the APIs directly. You get built-in observability, caching, fallback handling, and the flexibility to route requests to the right model for each task. No vendor lock-in, no rewriting your stack.
If you're building production AI applications that need the best of both worlds, check out Portkey.

