Comparing lean LLMs: GPT-5 Nano and Claude Haiku 4.5
Compare GPT-5 Nano and Claude Haiku 4.5 across reasoning, coding, and cost. See which lightweight model fits your production stack and test both directly through Portkey’s Prompt Playground or AI Gateway.

Large language models are getting faster, smaller, and more specialized. The industry is no longer just chasing “frontier” performance, it’s optimizing for speed, cost, and deployability.That’s where GPT-5 Nano and Claude Haiku 4.5 come in.
Both models are designed for real-time use cases, chatbots, coding assistants, multi-agent systems, and apps that need millisecond-level responses. Yet, they come from two very different philosophies:
- GPT-5 Nano: OpenAI’s leanest model in the GPT-5 family, built for efficiency and scale.
- Claude Haiku 4.5: Anthropic’s latest iteration in the Haiku line, promising near-frontier reasoning at a fraction of the cost.
In this blog, we’ll break down how these models perform across key dimensions like reasoning, coding, and multi-agent tasks; where they differ in latency and price; and which one fits best depending on your production needs.
Check this out!
GPT-5 Nano
GPT-5 Nano is the smallest model in OpenAI’s GPT-5 lineup, engineered for ultra-low latency and high throughput. It’s designed for production workloads where response time and cost per request matter more than frontier-level reasoning.
While OpenAI hasn’t disclosed full architecture details, Nano inherits the GPT-5 family’s system improvements, including faster inference paths, improved grounding, and more stable outputs across multi-turn conversations.
Nano trades off deep reasoning and contextual nuance for efficiency. Developers using the OpenAI API or platforms like Portkey can slot it into latency-sensitive paths while reserving GPT-5 or GPT-5 Mini for complex reasoning.
Claude Haiku 4.5
Claude Haiku 4.5 is Anthropic’s newest lightweight model, sitting below Sonnet 4.5 and Opus 4.5 in the Claude 4 family. Anthropic positions Haiku 4.5 as its “fastest and most affordable” model, delivering over 2× speed and ⅓ the cost of Sonnet 4 while maintaining strong reasoning and coding performance.
Haiku 4.5 benefits from the same Constitutional AI alignment stack and tool-use framework as the larger Claude models. Its design emphasizes reliability and contextual understanding within constrained budgets.
Anthropic’s system card notes improvements in computer-use tasks and agentic reasoning, reflecting optimizations that make Haiku 4.5 especially competitive for interactive or agent-driven workflows.
Benchmarks & performance comparison
Coding performance
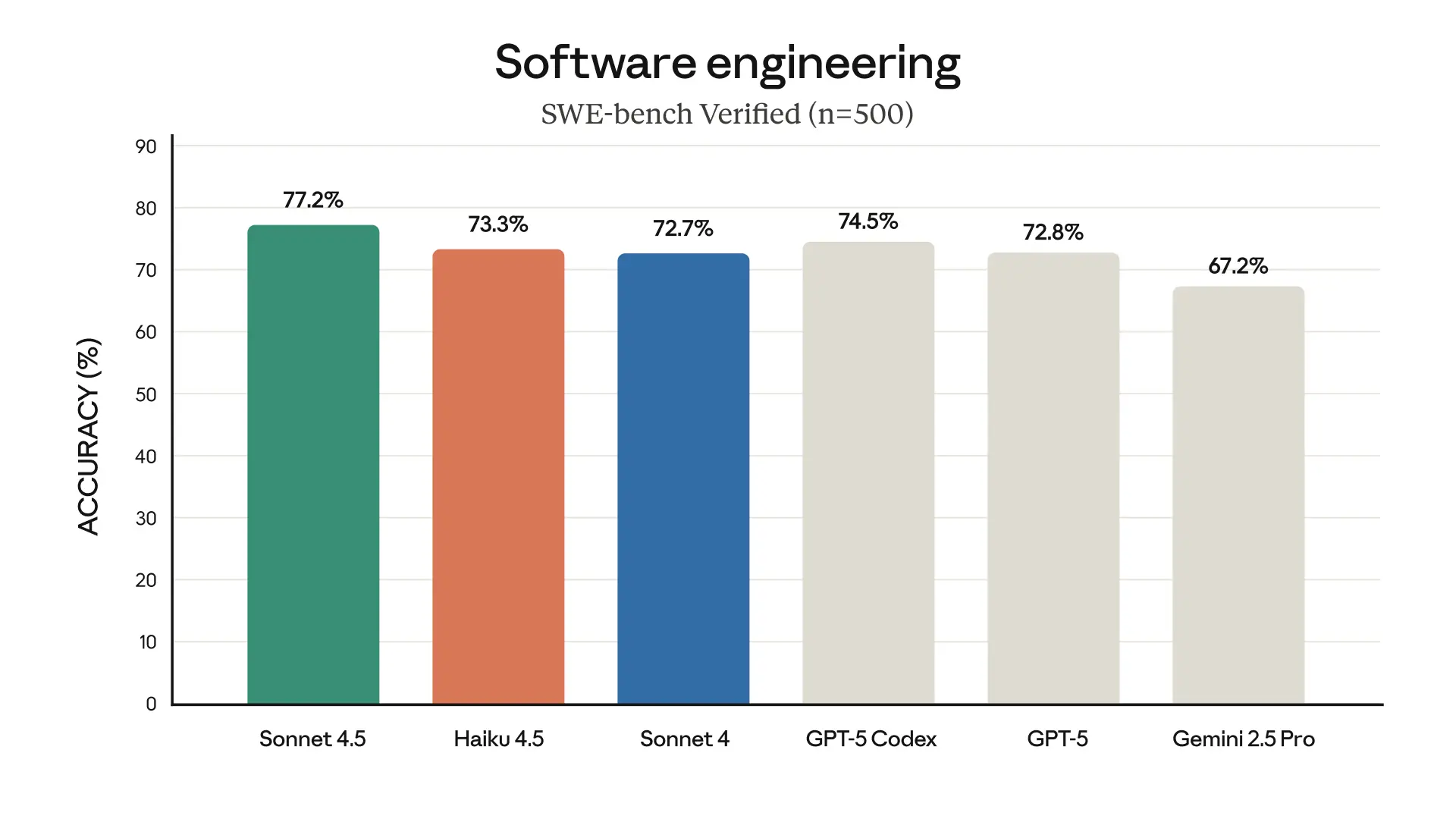
Claude Haiku 4.5: Haiku 4.5 continues Anthropic’s trend of compressing strong reasoning into smaller, faster models. The benchmark data shows that it performs close to Sonnet-tier models on real-world software tasks, indicating that Anthropic has significantly improved its smaller models’ ability to reason across multi-file codebases and handle bug-fix prompts with minimal context.
In practice, this means Haiku 4.5 can now power coding assistants and IDE integrations without major trade-offs in correctness.

Haiku 4.5 also shows strong performance in agentic coding tasks, problems that require chaining multiple reasoning steps, invoking tools, or simulating environment interactions.
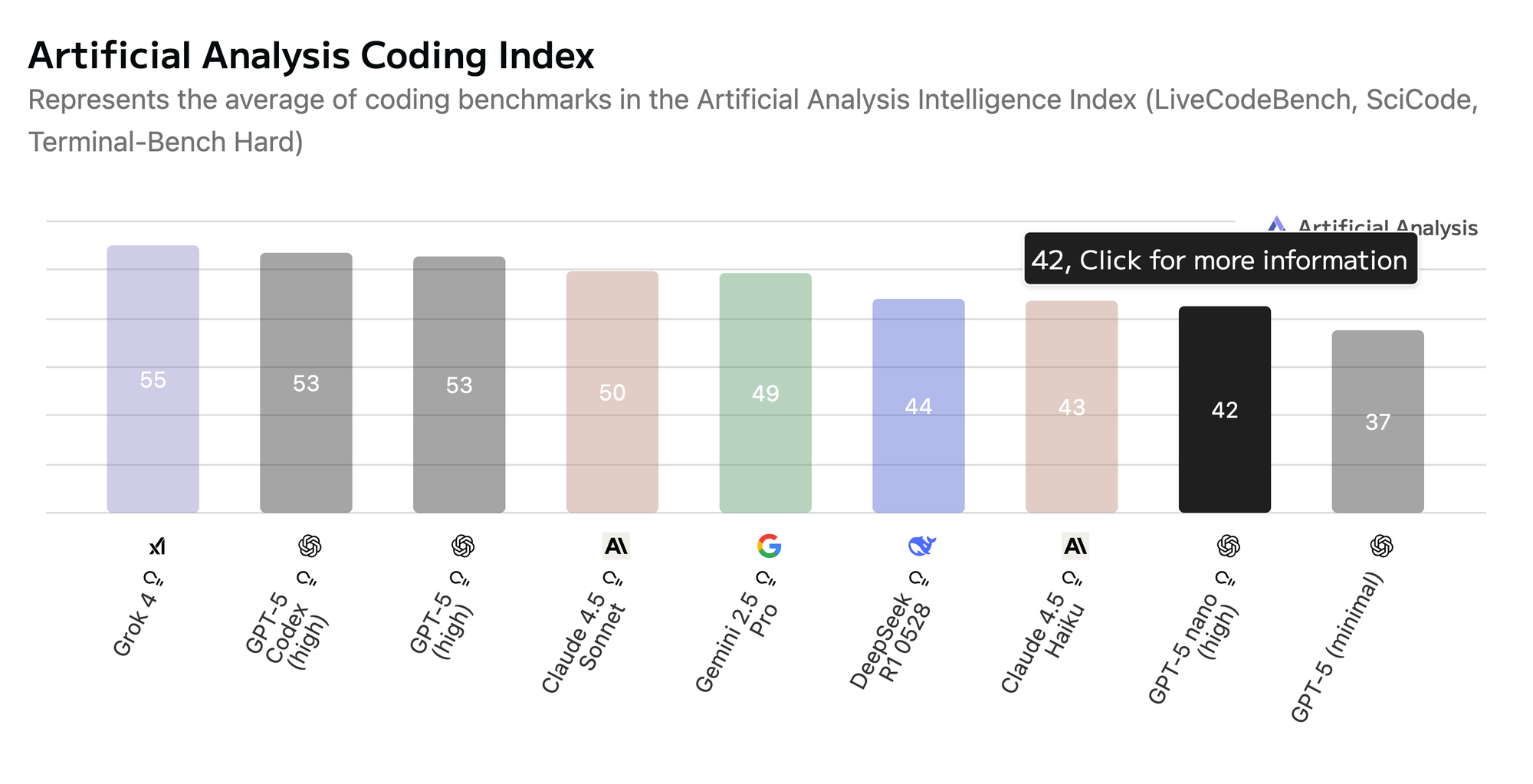
GPT-5 Nano: GPT-5 Nano sits squarely in the “efficiency-first” category. It trades depth for speed, excelling in shorter completions, boilerplate generation, and in-editor code suggestions where response time is critical. However, its lower aggregate coding score suggests it may struggle with more complex debugging or reasoning-heavy refactors.
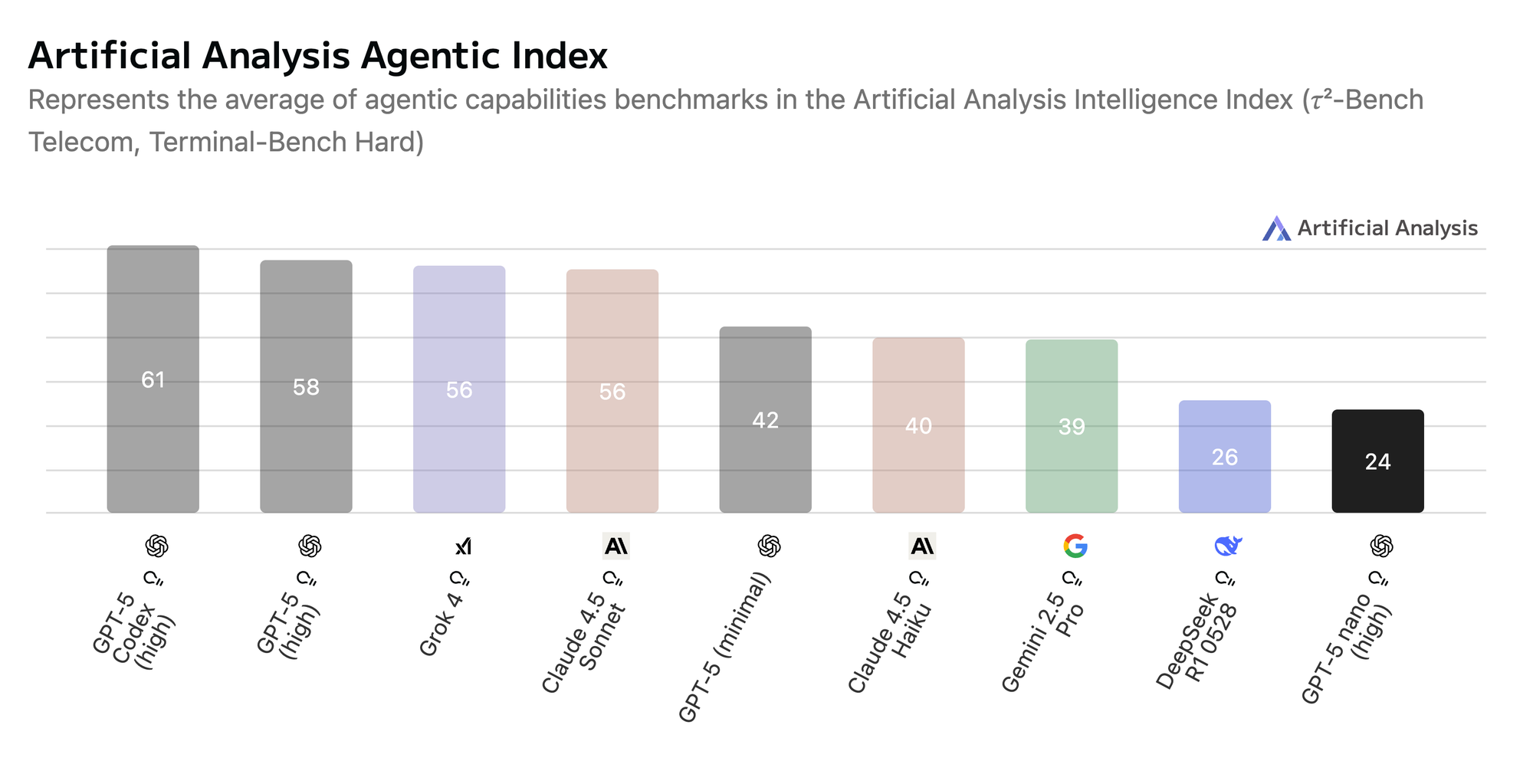
GPT-5 Nano, on the other hand, clearly optimizes for speed at the expense of complex tool orchestration. The benchmark gap suggests that Nano’s smaller context capacity and shallower reasoning depth limit its ability to persist multi-step states across tool invocations.
Mathematical reasoning

Claude Haiku 4.5
Haiku 4.5 performs strongly on symbolic and competition-style math tasks, showing it can retain structured reasoning even with limited context. It generalizes well on step-by-step logic problems and equation-based reasoning, making it capable in use cases like tutoring, evaluation agents, or analytical workflows without relying on external tools.
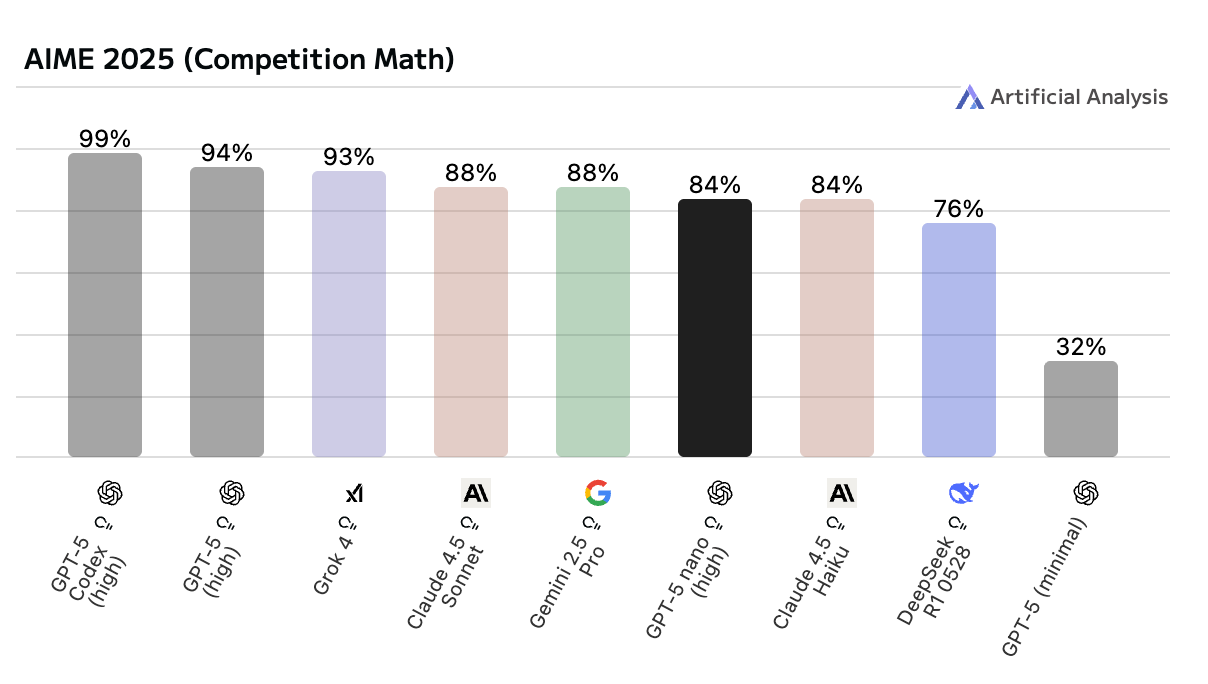
GPT-5 Nano
GPT-5 Nano delivers solid math accuracy for its size, benefitting from the GPT-5 family’s stronger arithmetic grounding. It’s quick at producing concise answers but occasionally skips intermediate reasoning steps, which can affect reliability on multi-part problems. This makes it efficient for simple or procedural math, though less consistent on extended proofs or abstract reasoning.
Reasoning
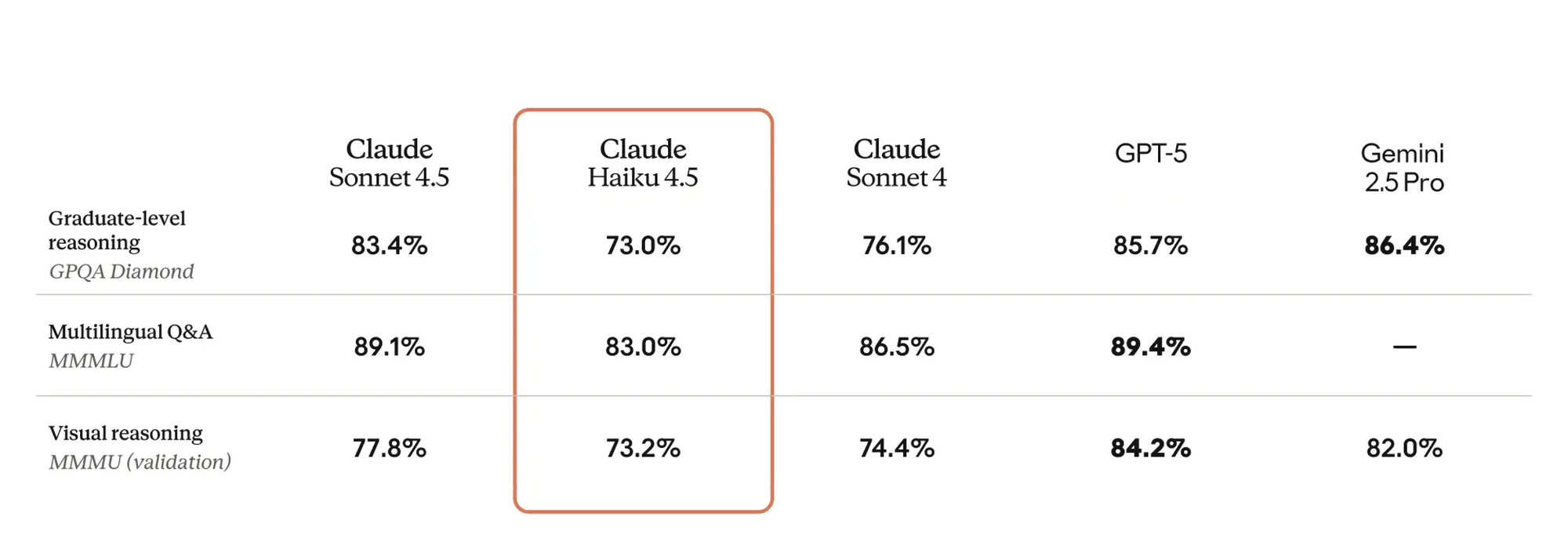
Claude Haiku 4.5
Haiku 4.5 demonstrates strong general reasoning for its size, maintaining coherence across multi-step logic and factual inference. It performs consistently on graduate-level benchmarks, showing improved abstraction and structured thinking over previous Haiku versions. This makes it reliable for decision-support, analysis, and assistant-style workflows that require both reasoning and contextual recall.

GPT-5 Nano
GPT-5 Nano holds its own within the lightweight model class, but its reasoning depth is narrower. It delivers quick, surface-level conclusions rather than multi-layered logic, which works well for short queries and dynamic environments but less for sustained analytical reasoning. It’s best used when you need fast judgment calls, not detailed argumentation.
Comparing costs: GPT-5-nano vs Claude Haiku 4.5
| Model | Input cost (per 1M tokens) | Output cost (per 1M tokens) | Cached input | Relative cost |
|---|---|---|---|---|
| GPT-5 Nano | $0.05 | $0.40 | $0.005 | ≈ 20–25× cheaper |
| Claude Haiku 4.5 | $1.00 | $5.00 | $1.25 – $2.00 (cache writes) | Mid-tier pricing |
Haiku 4.5 is positioned as Anthropic’s cost-efficient model within the Claude 4.5 lineup, but it’s still far more expensive than OpenAI’s lightweight tiers. At around $1 per million input tokens and $5 per million output tokens, it’s priced for teams that need stronger reasoning while keeping below frontier-model budgets.
GPT-5 Nano is optimized for extreme efficiency, with prices starting at $0.05 per million input tokens and $0.40 per million output tokens. That makes it roughly 20–25× cheaper than Haiku 4.5. Its low cached-input cost ($0.005 per MTok) further favors repetitive or automated pipelines. Nano is built for scale, routing layers, chatbots, summarization loops, or agent backends where response time and cost per request dominate.
When to use which
Both models represent the new wave of smaller, faster, and more deployable LLMs but they serve different ends of the spectrum.
Choose GPT-5 Nano when:
- You need speed and scale above all else—chat, summarization, or retrieval tasks.
- Cost is a deciding factor and you’re optimizing for millions of requests.
- Your system can offload complex reasoning to larger fallback models when needed.
Choose Claude Haiku 4.5 when:
- You need reliable reasoning within a smaller model footprint.
- Your workflows involve planning, multi-step tool use, or analytical depth.
- Latency is important, but accuracy and structure take precedence over raw throughput.
In production environments, these two can complement each other:
- GPT-5 Nano can act as the fast triage or executor layer, handling simple requests, pre-processing, and initial tool calls.
- Claude Haiku 4.5 can step in as the reasoning layer, validating, refining, or performing higher-order synthesis where precision matters.
Try them yourself
You don’t have to take benchmarks at face value, test how GPT-5 Nano and Claude Haiku 4.5 perform on your own workloads.
Head to the Prompt Playground on Portkey to compare prompts across both models side by side, or use them directly through the AI Gateway to manage routing, caching, and observability in production.